
Tutorial: How to Fine-Tune BERT for Named Entity Recognition (NER)



Tutorial: How to Fine-tune BERT for NER
Originally published by Skim AI's Machine Learning Researcher, Chris Tran.![]()
Introduction
This article is on how to fine-tune BERT for Named Entity Recognition (NER). Specifically, how to train a BERT variation, SpanBERTa, for NER. It is Part II of III in a series on training custom BERT Language Models for Spanish for a variety of use cases:
- Part I: How to Train a RoBERTa Language Model for Spanish from Scratch
- Part III: How to Train an ELECTRA Language Model for Spanish from Scratch
In my previous blog post, we have discussed how my team pretrained SpanBERTa, a transformer language model for Spanish, on a big corpus from scratch. The model has shown to be able to predict correctly masked words in a sequence based on its context. In this blog post, to really leverage the power of transformer models, we will fine-tune SpanBERTa for a named-entity recognition task.
According to its definition on Wikipedia, Named-entity recognition (NER) (also known as entity identification, entity chunking and entity extraction) is a subtask of information extraction that seeks to locate and classify named entity mentioned in unstructured text into pre-defined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.
We will use the script run_ner.py by Hugging Face and CoNLL-2002 dataset to fine-tune SpanBERTa.
Setup
Download transformers and install required packages.
%%capture
!git clone https://github.com/huggingface/transformers
%cd transformers
!pip install .
!pip install -r ./examples/requirements.txt
%cd ..
Data
1. Download Datasets
The below command will download and unzip the dataset. The files contain the train and test data for three parts of the CoNLL-2002 shared task:
- esp.testa: Spanish test data for the development stage
- esp.testb: Spanish test data
- esp.train: Spanish train data
%%capture
!wget -O 'conll2002.zip' 'https://drive.google.com/uc?export=download&id=1Wrl1b39ZXgKqCeAFNM9EoXtA1kzwNhCe'
!unzip 'conll2002.zip'
The size of each dataset:
!wc -l conll2002/esp.train
!wc -l conll2002/esp.testa
!wc -l conll2002/esp.testb
273038 conll2002/esp.train
54838 conll2002/esp.testa
53050 conll2002/esp.testb
All data files has three columns: words, associated part-of-speech tags and named entity tags in the IOB2 format. Sentence breaks are encoded by empty lines.
!head -n20 conll2002/esp.train
Melbourne NP B-LOC
( Fpa O
Australia NP B-LOC
) Fpt O
, Fc O
25 Z O
may NC O
( Fpa O
EFE NC B-ORG
) Fpt O
. Fp O
- Fg O
El DA O
Abogado NC B-PER
General AQ I-PER
del SP I-PER
Estado NC I-PER
, Fc O
We will only keep the word column and the named entity tag column for our train, dev and test datasets.
!cat conll2002/esp.train | cut -d " " -f 1,3 > train_temp.txt
!cat conll2002/esp.testa | cut -d " " -f 1,3 > dev_temp.txt
!cat conll2002/esp.testb | cut -d " " -f 1,3 > test_temp.txt
2. Preprocessing
Let’s define some variables that we need for further pre-processing steps and training the model:
MAX_LENGTH = 120 #@param {type: "integer"}
MODEL = "chriskhanhtran/spanberta" #@param ["chriskhanhtran/spanberta", "bert-base-multilingual-cased"]
The script below will split sentences longer than MAX_LENGTH (in terms of tokens) into small ones. Otherwise, long sentences will be truncated when tokenized, causing the loss of training data and some tokens in the test set not being predicted.
%%capture
!wget "https://raw.githubusercontent.com/stefan-it/fine-tuned-berts-seq/master/scripts/preprocess.py"
!python3 preprocess.py train_temp.txt $MODEL $MAX_LENGTH > train.txt
!python3 preprocess.py dev_temp.txt $MODEL $MAX_LENGTH > dev.txt
!python3 preprocess.py test_temp.txt $MODEL $MAX_LENGTH > test.txt
2020-04-22 23:02:05.747294: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1
Downloading: 100% 1.03k/1.03k [00:00<00:00, 704kB/s]
Downloading: 100% 954k/954k [00:00<00:00, 1.89MB/s]
Downloading: 100% 512k/512k [00:00<00:00, 1.19MB/s]
Downloading: 100% 16.0/16.0 [00:00<00:00, 12.6kB/s]
2020-04-22 23:02:23.409488: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1
2020-04-22 23:02:31.168967: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1
3. Labels
In CoNLL-2002/2003 datasets, there are have 9 classes of NER tags:
- O, Outside of a named entity
- B-MIS, Beginning of a miscellaneous entity right after another miscellaneous entity
- I-MIS, Miscellaneous entity
- B-PER, Beginning of a person’s name right after another person’s name
- I-PER, Person’s name
- B-ORG, Beginning of an organisation right after another organisation
- I-ORG, Organisation
- B-LOC, Beginning of a location right after another location
- I-LOC, Location
If your dataset has different labels or more labels than CoNLL-2002/2003 datasets, run the line below to get unique labels from your data and save them into labels.txt. This file will be used when we start fine-tuning our model.
!cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
Fine-tuning Model
These are the example scripts from transformers's repo that we will use to fine-tune our model for NER. After 04/21/2020, Hugging Face has updated their example scripts to use a new Trainer class. To avoid any future conflict, let's use the version before they made these updates.
%%capture
!wget "https://raw.githubusercontent.com/chriskhanhtran/spanish-bert/master/ner/run_ner.py"
!wget "https://raw.githubusercontent.com/chriskhanhtran/spanish-bert/master/ner/utils_ner.py"
Now it's time for transfer learning. In my previous blog post, I have pretrained a RoBERTa language model on a very large Spanish corpus to predict masked words based on the context they are in. By doing that, the model has learned inherent properties of the language. I have uploaded the pretrained model to Hugging Face's server. Now we will load the model and start fine-tuning it for the NER task.
Below are our training hyperparameters.
MAX_LENGTH = 128 #@param {type: "integer"}
MODEL = "chriskhanhtran/spanberta" #@param ["chriskhanhtran/spanberta", "bert-base-multilingual-cased"]
OUTPUT_DIR = "spanberta-ner" #@param ["spanberta-ner", "bert-base-ml-ner"]
BATCH_SIZE = 32 #@param {type: "integer"}
NUM_EPOCHS = 3 #@param {type: "integer"}
SAVE_STEPS = 100 #@param {type: "integer"}
LOGGING_STEPS = 100 #@param {type: "integer"}
SEED = 42 #@param {type: "integer"}
Let's start training.
!python3 run_ner.py
--data_dir ./
--model_type bert
--labels ./labels.txt
--model_name_or_path $MODEL
--output_dir $OUTPUT_DIR
--max_seq_length $MAX_LENGTH
--num_train_epochs $NUM_EPOCHS
--per_gpu_train_batch_size $BATCH_SIZE
--save_steps $SAVE_STEPS
--logging_steps $LOGGING_STEPS
--seed $SEED
--do_train
--do_eval
--do_predict
--overwrite_output_dir
Performance on the dev set:
04/21/2020 02:24:31 - INFO - __main__ - ***** Eval results *****
04/21/2020 02:24:31 - INFO - __main__ - f1 = 0.831027443864822
04/21/2020 02:24:31 - INFO - __main__ - loss = 0.1004064822183894
04/21/2020 02:24:31 - INFO - __main__ - precision = 0.8207885304659498
04/21/2020 02:24:31 - INFO - __main__ - recall = 0.8415250344510795
Performance on the test set:
04/21/2020 02:24:48 - INFO - __main__ - ***** Eval results *****
04/21/2020 02:24:48 - INFO - __main__ - f1 = 0.8559533721898419
04/21/2020 02:24:48 - INFO - __main__ - loss = 0.06848683688204177
04/21/2020 02:24:48 - INFO - __main__ - precision = 0.845858475041141
04/21/2020 02:24:48 - INFO - __main__ - recall = 0.8662921348314607
Here are the tensorboards of fine-tuning spanberta and bert-base-multilingual-cased for 5 epoches. We can see that the models overfit the training data after 3 epoches.
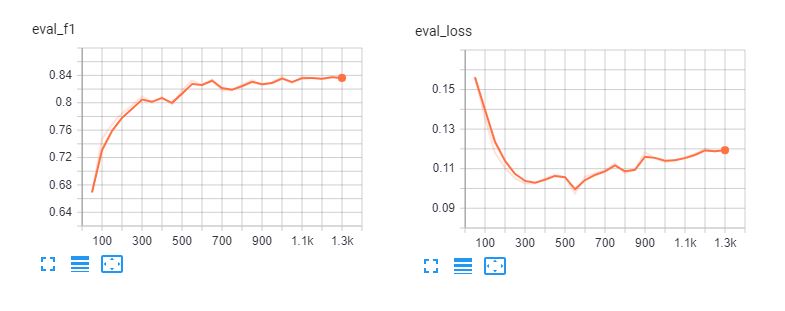
Classification Report
To understand how well our model actually performs, let's load its predictions and examine the classification report.
def read_examples_from_file(file_path):
"""Read words and labels from a CoNLL-2002/2003 data file.
Args:
file_path (str): path to NER data file.
Returns:
examples (dict): a dictionary with two keys: words (list of lists)
holding words in each sequence, and labels (list of lists) holding
corresponding labels.
"""
with open(file_path, encoding="utf-8") as f:
examples = {"words": [], "labels": []}
words = []
labels = []
for line in f:
if line.startswith("-DOCSTART-") or line == "" or line == "n":
if words:
examples["words"].append(words)
examples["labels"].append(labels)
words = []
labels = []
else:
splits = line.split(" ")
words.append(splits[0])
if len(splits) > 1:
labels.append(splits[-1].replace("n", ""))
else:
# Examples could have no label for mode = "test"
labels.append("O")
return examples
Read data and labels from the raw text files:
y_true = read_examples_from_file("test.txt")["labels"]
y_pred = read_examples_from_file("spanberta-ner/test_predictions.txt")["labels"]
Print the classification report:
from seqeval.metrics import classification_report as classification_report_seqeval
print(classification_report_seqeval(y_true, y_pred))
precision recall f1-score support
LOC 0.87 0.84 0.85 1084
ORG 0.82 0.87 0.85 1401
MISC 0.63 0.66 0.65 340
PER 0.94 0.96 0.95 735
micro avg 0.84 0.86 0.85 3560
macro avg 0.84 0.86 0.85 3560
The metrics we are seeing in this report are designed specifically for NLP tasks such as NER and POS tagging, in which all words of an entity need to be predicted correctly to be counted as one correct prediction. Therefore, the metrics in this classification report are much lower than in scikit-learn's classification report.
import numpy as np
from sklearn.metrics import classification_report
print(classification_report(np.concatenate(y_true), np.concatenate(y_pred)))
precision recall f1-score support
B-LOC 0.88 0.85 0.86 1084
B-MISC 0.73 0.73 0.73 339
B-ORG 0.87 0.91 0.89 1400
B-PER 0.95 0.96 0.95 735
I-LOC 0.82 0.81 0.81 325
I-MISC 0.85 0.76 0.80 557
I-ORG 0.89 0.87 0.88 1104
I-PER 0.98 0.98 0.98 634
O 1.00 1.00 1.00 45355
accuracy 0.98 51533
macro avg 0.89 0.87 0.88 51533
weighted avg 0.98 0.98 0.98 51533
From above reports, our model has a good performance in predicting person, location and organization. We will need more data for MISC entities to improve our model's performance on these entities.
Pipeline
After fine-tuning our models, we can share them with the community by following the tutorial in this page. Now we can start loading the fine-tuned model from Hugging Face's server and use it to predict named entities in Spanish documents.
from transformers import pipeline, AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("skimai/spanberta-base-cased-ner-conll02")
tokenizer = AutoTokenizer.from_pretrained("skimai/spanberta-base-cased-ner-conll02")
ner_model = pipeline('ner', model=model, tokenizer=tokenizer)
The example below is obtained from La Opinión and means "The economic recovery of the United States after the coronavirus pandemic will be a matter of months, said Treasury Secretary Steven Mnuchin."
sequence = "La recuperación económica de los Estados Unidos después de la "
"pandemia del coronavirus será cuestión de meses, afirmó el "
"Secretario del Tesoro, Steven Mnuchin."
ner_model(sequence)
[{'entity': 'B-ORG', 'score': 0.9155661463737488, 'word': 'ĠEstados'},
{'entity': 'I-ORG', 'score': 0.800682544708252, 'word': 'ĠUnidos'},
{'entity': 'I-MISC', 'score': 0.5006815791130066, 'word': 'Ġcorona'},
{'entity': 'I-MISC', 'score': 0.510674774646759, 'word': 'virus'},
{'entity': 'B-PER', 'score': 0.5558510422706604, 'word': 'ĠSecretario'},
{'entity': 'I-PER', 'score': 0.7758238315582275, 'word': 'Ġdel'},
{'entity': 'I-PER', 'score': 0.7096233367919922, 'word': 'ĠTesoro'},
{'entity': 'B-PER', 'score': 0.9940345883369446, 'word': 'ĠSteven'},
{'entity': 'I-PER', 'score': 0.9962581992149353, 'word': 'ĠM'},
{'entity': 'I-PER', 'score': 0.9918380379676819, 'word': 'n'},
{'entity': 'I-PER', 'score': 0.9848328828811646, 'word': 'uch'},
{'entity': 'I-PER', 'score': 0.8513168096542358, 'word': 'in'}]
Looks great! The fine-tuned model successfully recognizes all entities in our example, and even recognizes "corona virus."
Conclusion
Named-entity recognition can help us quickly extract important information from texts. Therefore, its application in business can have a direct impact on improving human's productivity in reading contracts and documents. However, it is a challenging NLP task because NER requires accurate classification at the word level, making simple approaches such as bag-of-word impossible to deal with this task.
We have walked through how we can leverage a pretrained BERT model to quickly gain an excellent performance on the NER task for Spanish. The pretrained SpanBERTa model can also be fine-tuned for other tasks such as document classification. I have written a detailed tutorial to finetune BERT for sequence classification and sentiment analysis.
Next in this series is Part 3, we will discuss how to use ELECTRA, a more efficient pre-training approach for transformer models which can quickly achieve state-of-the-art performance. Stay tuned!


