
Tutorial: Como afinar o BERT para reconhecimento de entidades nomeadas (NER)



Tutorial: Como afinar o BERT para NER
Originalmente publicado por Chris Tran, investigador de aprendizagem automática da Skim AI.![]()
Introdução
Este artigo trata do aperfeiçoamento do BERT para o reconhecimento de entidades nomeadas (NER). Especificamente, como treinar uma variação do BERT, SpanBERTa, para NER. É a Parte II de III de uma série sobre o treino de modelos linguísticos personalizados do BERT para espanhol para uma variedade de casos de utilização:
- Parte I: Como treinar um modelo linguístico RoBERTa para espanhol a partir do zero
- Parte III: Como treinar um modelo linguístico da ELECTRA para o espanhol a partir do zero
Na minha publicação anterior no blogue, discutimos como a minha equipa pré-treinou o SpanBERTa, um modelo linguístico transformador para espanhol, num grande corpus de raiz. O modelo demonstrou ser capaz de prever corretamente palavras mascaradas numa sequência com base no seu contexto. Nesta publicação do blogue, para tirar realmente partido do poder dos modelos transformadores, vamos afinar o SpanBERTa para uma tarefa de reconhecimento de identidades nomeadas.
De acordo com a sua definição em WikipédiaO reconhecimento de entidades nomeadas (NER) (também conhecido como identificação de entidades, fragmentação de entidades e extração de entidades) é uma subtarefa da extração de informação que procura localizar e classificar entidades nomeadas mencionadas em texto não estruturado em categorias pré-definidas, tais como nomes de pessoas, organizações, localizações, códigos médicos, expressões temporais, quantidades, valores monetários, percentagens, etc.
Utilizaremos o script run_ner.py por Hugging Face e Conjunto de dados CoNLL-2002 para afinar o SpanBERTa.
Configuração
Descarregar transformadores e instalar os pacotes necessários.
%%capture
!git clone https://github.com/huggingface/transformers
%cd transformers
!pip install .
!pip install -r ./examples/requirements.txt
%cd ..
Dados
1. Descarregar conjuntos de dados
O comando abaixo irá descarregar e descomprimir o conjunto de dados. Os ficheiros contêm os dados de treino e de teste para três partes do CoNLL-2002 tarefa partilhada:
- esp.testa: Dados de teste espanhóis para a fase de desenvolvimento
- esp.testb: Dados de testes espanhóis
- esp.train: Dados de comboios espanhóis
%ptura
!wget -O 'conll2002.zip' 'https://drive.google.com/uc?export=download&id=1Wrl1b39ZXgKqCeAFNM9EoXtA1kzwNhCe'
!descompactar 'conll2002.zip'
O tamanho de cada conjunto de dados:
!wc -l conll2002/esp.train
!wc -l conll2002/esp.testa
!wc -l conll2002/esp.testb
273038 conll2002/esp.train
54838 conll2002/esp.testa
53050 conll2002/esp.testb
Todos os ficheiros de dados têm três colunas: palavras, etiquetas de parte do discurso associadas e etiquetas de entidades nomeadas no formato IOB2. As quebras de frase são codificadas por linhas vazias.
!head -n20 conll2002/esp.train
Melbourne NP B-LOC
( Fpa O
Austrália NP B-LOC
) Fpt O
, Fc O
25 Z O
pode NC O
( Fpa O
EFE NC B-ORG
) Fpt O
. Fp O
- Fg O
El DA O
Abogado NC B-PER
General AQ I-PER
del SP I-PER
Estado NC I-PER
, Fc O
Apenas manteremos a coluna da palavra e a coluna da etiqueta da entidade nomeada para os nossos conjuntos de dados de treino, desenvolvimento e teste.
!cat conll2002/esp.train | cut -d " " -f 1,3 > train_temp.txt
!cat conll2002/esp.testa | cut -d " " -f 1,3 > dev_temp.txt
!cat conll2002/esp.testb | cut -d " " -f 1,3 > test_temp.txt
2. Pré-processamento
Vamos definir algumas variáveis de que necessitamos para outras etapas de pré-processamento e para treinar o modelo:
MAX_LENGTH = 120 #@param {type: "integer"}
MODELO = "chriskhanhtran/spanberta" #@param ["chriskhanhtran/spanberta", "bert-base-multilingual-cased"]
O script abaixo dividirá frases maiores que MAX_LENGTH (em termos de tokens) em frases pequenas. Caso contrário, as frases longas serão truncadas quando tokenizadas, causando a perda de dados de treino e a não previsão de alguns tokens no conjunto de teste.
%ptura
!wget "https://raw.githubusercontent.com/stefan-it/fine-tuned-berts-seq/master/scripts/preprocess.py"
!python3 preprocess.py train_temp.txt $MODEL $MAX_LENGTH > train.txt
!python3 preprocess.py dev_temp.txt $MODEL $MAX_LENGTH > dev.txt
!python3 preprocess.py test_temp.txt $MODEL $MAX_LENGTH > test.txt
2020-04-22 23:02:05.747294: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Abriu com sucesso a biblioteca dinâmica libcudart.so.10.1
Descarregando: 100% 1.03k/1.03k [00:00<00:00, 704kB/s]
Descarregando: 100% 954k/954k [00:00<00:00, 1.89MB/s]
Descarregando: 100% 512k/512k [00:00<00:00, 1.19MB/s]
Descarregando: 100% 16.0/16.0 [00:00<00:00, 12.6kB/s]
2020-04-22 23:02:23.409488: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Abriu com sucesso a biblioteca dinâmica libcudart.so.10.1
2020-04-22 23:02:31.168967: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Abriu com sucesso a biblioteca dinâmica libcudart.so.10.1
3. Etiquetas
Nos conjuntos de dados CoNLL-2002/2003, existem 9 classes de etiquetas NER:
- O, Fora de uma entidade nomeada
- B-MIS, Início de uma entidade diversa logo após outra entidade diversa
- I-MIS, Entidade diversa
- B-PER, Início do nome de uma pessoa logo após o nome de outra pessoa
- I-PER, Nome da pessoa
- B-ORG, Início de uma organização logo após outra organização
- I-ORG, Organização
- B-LOC, Início de uma localização logo após outra localização
- I-LOC, Localização
Se o seu conjunto de dados tiver etiquetas diferentes ou mais etiquetas do que os conjuntos de dados CoNLL-2002/2003, execute a linha abaixo para obter etiquetas únicas dos seus dados e guarde-as em etiquetas.txt. Este ficheiro será utilizado quando começarmos a afinar o nosso modelo.
!cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
Modelo de afinação
Estes são os exemplos de scripts de transformadoresque utilizaremos para afinar o nosso modelo para NER. Após 21/04/2020, a Hugging Face actualizou os seus scripts de exemplo para utilizar um novo Treinador classe. Para evitar qualquer conflito futuro, vamos utilizar a versão anterior a estas actualizações.
%ptura
!wget "https://raw.githubusercontent.com/chriskhanhtran/spanish-bert/master/ner/run_ner.py"
!wget "https://raw.githubusercontent.com/chriskhanhtran/spanish-bert/master/ner/utils_ner.py"
Agora é a vez da aprendizagem por transferência. No meu publicação anterior no blogueNa minha pesquisa, pré-treinei um modelo linguístico RoBERTa num corpus espanhol muito grande para prever palavras mascaradas com base no contexto em que se encontram. Ao fazê-lo, o modelo aprendeu propriedades inerentes à língua. Fiz o upload do modelo pré-treinado para o servidor do Hugging Face. Agora vamos carregar o modelo e começar a ajustá-lo para a tarefa NER.
Abaixo estão os nossos hiperparâmetros de treino.
MAX_LENGTH = 128 #@param {type: "integer"}
MODELO = "chriskhanhtran/spanberta" #@param ["chriskhanhtran/spanberta", "bert-base-multilingual-cased"]
OUTPUT_DIR = "spanberta-ner" #@param ["spanberta-ner", "bert-base-ml-ner"]
BATCH_SIZE = 32 #@param {type: "integer"}
NUM_EPOCHS = 3 #@param {type: "integer"}
SAVE_STEPS = 100 #@param {type: "integer"}
LOGGING_STEPS = 100 #@param {type: "integer"}
SEED = 42 #@param {type: "integer"}
Vamos começar a treinar.
!python3 run_ner.py
--data_dir ./
--model_type bert
--labels ./labels.txt
--nome_do_modelo_ou_caminho $MODEL
--output_dir $OUTPUT_DIR
--max_seq_length $MAX_LENGTH
--num_train_epochs $NUM_EPOCHS
--por_gpu_train_batch_size $BATCH_SIZE
--save_steps $SAVE_STEPS
--logging_steps $LOGGING_STEPS
-seed $SEED
--do_train
--do_eval
--do_predict
--overwrite_output_dir
Desempenho no conjunto de desenvolvimento:
04/21/2020 02:24:31 - INFO - __main__ - ***** Resultados da avaliação *****
21/04/2020 02:24:31 - INFO - __main__ - f1 = 0.831027443864822
21/04/2020 02:24:31 - INFO - __main__ - perda = 0.1004064822183894
21/04/2020 02:24:31 - INFO - __main__ - precisão = 0.8207885304659498
21/04/2020 02:24:31 - INFO - __main__ - recall = 0.8415250344510795
Desempenho no conjunto de teste:
21/04/2020 02:24:48 - INFO - __main__ - ***** Resultados da avaliação *****
21/04/2020 02:24:48 - INFO - __main__ - f1 = 0.8559533721898419
21/04/2020 02:24:48 - INFO - __main__ - perda = 0.06848683688204177
21/04/2020 02:24:48 - INFO - __main__ - precisão = 0.845858475041141
21/04/2020 02:24:48 - INFO - __main__ - recall = 0.8662921348314607
Aqui estão os quadros tensoriais de afinação Spanberta e bert-base-multilingual-cased para 5 épocas. Podemos ver que os modelos se ajustam demasiado aos dados de treino após 3 épocas.
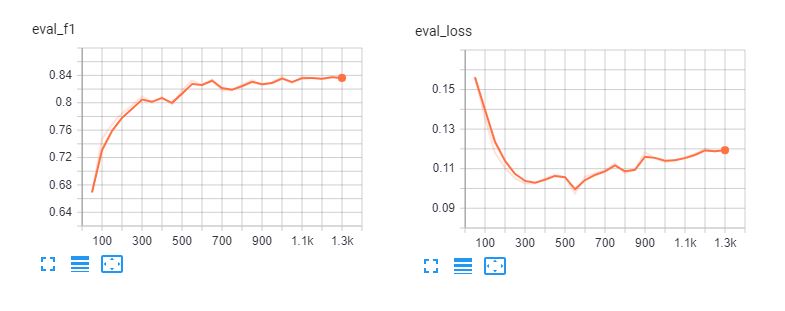
Relatório de classificação
Para compreender o desempenho efetivo do nosso modelo, vamos carregar as suas previsões e examinar o relatório de classificação.
def read_examples_from_file(file_path):
"""Ler palavras e etiquetas de um ficheiro de dados CoNLL-2002/2003.
Args:
file_path (str): caminho para o ficheiro de dados NER.
Retorna:
examples (dict): um dicionário com duas chaves: palavras (lista de listas)
com palavras em cada sequência, e rótulos (lista de listas) com
etiquetas correspondentes.
"""
com open(file_path, encoding="utf-8") as f:
examples = {"words": [], "labels": []}
palavras = []
etiquetas = []
para linha em f:
se line.startswith("-DOCSTART-") ou line == "" ou line == "\n":
if palavras:
exemplos["palavras"].append(palavras)
exemplos["etiquetas"].append(etiquetas)
palavras = []
etiquetas = []
else:
splits = line.split(" ")
palavras.append(divisões[0])
se len(parciais) > 1:
labels.append(splits[-1].replace("\n", ""))
else:
# Os exemplos não podem ter etiqueta para mode = "test"
etiquetas.append("O")
devolver exemplos
Ler dados e etiquetas dos ficheiros de texto em bruto:
y_true = read_examples_from_file("test.txt")["labels"]
y_pred = read_examples_from_file("spanberta-ner/test_predictions.txt")["labels"]
Imprimir o relatório de classificação:
from seqeval.metrics import classification_report as classification_report_seqeval
print(classification_report_seqeval(y_true, y_pred))
precisão recordação pontuação f1 apoio
LOC 0.87 0.84 0.85 1084
ORG 0.82 0.87 0.85 1401
MISC 0,63 0,66 0,65 340
POR 0,94 0,96 0,95 735
micro avg 0.84 0.86 0.85 3560
macro avg 0.84 0.86 0.85 3560
As métricas que vemos neste relatório foram concebidas especificamente para tarefas de PNL, como NER e marcação POS, em que todas as palavras de uma entidade têm de ser previstas corretamente para serem contadas como uma previsão correcta. Por conseguinte, as métricas neste relatório de classificação são muito inferiores às do relatório relatório de classificação do scikit-learn.
importar numpy as np
from sklearn.metrics import classification_report
print(relatório_classificação(np.concatenate(y_true), np.concatenate(y_pred)))
precisão recordação pontuação f1 apoio
B-LOC 0,88 0,85 0,86 1084
B-MISC 0.73 0.73 0.73 339
B-ORG 0.87 0.91 0.89 1400
B-PER 0.95 0.96 0.95 735
I-LOC 0.82 0.81 0.81 325
I-MISC 0.85 0.76 0.80 557
I-ORG 0.89 0.87 0.88 1104
I-PER 0.98 0.98 0.98 634
O 1.00 1.00 1.00 45355
precisão 0.98 51533
macro avg 0.89 0.87 0.88 51533
média ponderada 0.98 0.98 0.98 51533
A partir dos relatórios acima, o nosso modelo tem um bom desempenho na previsão da pessoa, localização e organização. Precisamos de mais dados para MISC entidades para melhorar o desempenho do nosso modelo nestas entidades.
Condutas
Depois de afinarmos os nossos modelos, podemos partilhá-los com a comunidade seguindo o tutorial neste página. Agora podemos começar a carregar o modelo ajustado do servidor da Hugging Face e utilizá-lo para prever entidades nomeadas em documentos espanhóis.
from transformers import pipeline, AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("skimai/spanberta-base-cased-ner-conll02")
tokenizer = AutoTokenizer.from_pretrained("skimai/spanberta-base-cased-ner-conll02")
ner_model = pipeline('ner', model=model, tokenizer=tokenizer)
O exemplo abaixo foi obtido de La Opinión e significa "A recuperação económica dos Estados Unidos após a pandemia do coronavírus será uma questão de meses, afirmou o Secretário do Tesouro, Steven Mnuchin."
sequence = "La recuperación económica de los Estados Unidos después de la " \
"pandemia do coronavírus será assunto de meses, afirmou o " \
"Secretário do Tesouro, Steven Mnuchin."
ner_model(sequência)
[{'entidade': 'B-ORG', 'pontuação': 0.9155661463737488, 'palavra': 'ĠEstados'},
{'entidade': 'I-ORG', 'pontuação': 0.800682544708252, 'palavra': 'ĠUnidos'},
{'entidade': 'I-MISC', 'pontuação': 0.5006815791130066, 'palavra': 'Ġcorona'},
{'entidade': 'I-MISC', 'score': 0.510674774646759, 'word': 'virus'},
{'entidade': 'B-PER', 'pontuação': 0.5558510422706604, 'palavra': 'ĠSecretario'},
{'entidade': 'I-PER', 'pontuação': 0.7758238315582275, 'palavra': 'Ġdel'},
{'entidade': 'I-PER', 'pontuação': 0.7096233367919922, 'palavra': 'ĠTesoro'},
{'entidade': 'B-PER', 'pontuação': 0.9940345883369446, 'palavra': 'ĠSteven'},
{'entidade': 'I-PER', 'pontuação': 0.9962581992149353, 'palavra': 'ĠM'},
{'entidade': 'I-PER', 'pontuação': 0.9918380379676819, 'palavra': 'n'},
{'entidade': 'I-PER', 'pontuação': 0.9848328828811646, 'palavra': 'uch'},
{'entidade': 'I-PER', 'pontuação': 0.8513168096542358, 'palavra': 'in'}]
Parece ótimo! O modelo ajustado reconhece com sucesso todas as entidades do nosso exemplo e até reconhece o "corona vírus".
Conclusão
O reconhecimento de identidades nomeadas pode ajudar-nos a extrair rapidamente informações importantes de textos. Por conseguinte, a sua aplicação no mundo dos negócios pode ter um impacto direto na melhoria da produtividade humana na leitura de contratos e documentos. No entanto, trata-se de uma tarefa de PNL difícil, porque o NER exige uma classificação exacta ao nível da palavra, o que faz com que abordagens simples, como o "bag-of-word", não consigam lidar com esta tarefa.
Explicámos como podemos tirar partido de um modelo BERT pré-treinado para obter rapidamente um excelente desempenho na tarefa NER para espanhol. O modelo SpanBERTa pré-treinado também pode ser ajustado para outras tarefas, como a classificação de documentos. Escrevi um tutorial detalhado para afinar o BERT para classificação de sequências e análise de sentimentos.
A próxima parte desta série é a Parte 3, na qual discutiremos como usar o ELECTRA, uma abordagem de pré-treinamento mais eficiente para modelos de transformadores que podem atingir rapidamente o desempenho mais avançado. Fique ligado!


