
튜토리얼: 네임드 엔티티 인식(NER)을 위해 BERT를 미세 조정하는 방법



튜토리얼: NER용 BERT를 미세 조정하는 방법
Skim AI의 머신러닝 연구원 크리스 트란이 처음 게시했습니다.![]()
소개
이 문서에서는 네임드 엔티티 인식(NER)을 위해 BERT를 미세 조정하는 방법에 대해 설명합니다. 특히, NER을 위해 BERT 변형인 SpanBERTa를 훈련하는 방법에 대해 설명합니다. 다양한 사용 사례를 위한 스페인어용 사용자 지정 BERT 언어 모델 훈련에 대한 시리즈 3부 중 2부입니다:
이전 블로그 게시물에서 저희 팀이 스페인어용 트랜스포머 언어 모델인 SpanBERTa를 처음부터 대규모 말뭉치에 대해 사전 학습시킨 방법에 대해 설명한 바 있습니다. 이 모델은 문맥에 따라 시퀀스에서 마스킹된 단어를 정확하게 예측할 수 있는 것으로 나타났습니다. 이 블로그 게시물에서는 트랜스포머 모델의 성능을 실제로 활용하기 위해 명명된 엔티티 인식 작업을 위해 SpanBERTa를 미세 조정해 보겠습니다.
의 정의에 따르면 Wikipedia엔티티 식별, 엔티티 청킹, 엔티티 추출이라고도 하는 명명된 엔티티 인식(NER)은 비정형 텍스트에 언급된 명명된 엔티티를 찾아서 사람 이름, 조직, 위치, 의료 코드, 시간 표현, 수량, 화폐 가치, 백분율 등과 같은 사전 정의된 카테고리로 분류하는 정보 추출의 하위 작업입니다.
스크립트를 사용합니다. run_ner.py 허깅 페이스와 CoNLL-2002 데이터 세트 를 사용하여 SpanBERTa를 미세 조정할 수 있습니다.
설정
다운로드 트랜스포머 를 클릭하고 필요한 패키지를 설치합니다.
%%capture
!git clone https://github.com/huggingface/transformers
%cd transformers
!pip install .
!pip install -r ./examples/requirements.txt
%cd ..
데이터
1. 데이터 세트 다운로드
아래 명령은 데이터 세트를 다운로드하고 압축을 해제합니다. 파일에는 다음 세 가지 부분에 대한 훈련 및 테스트 데이터가 포함되어 있습니다. CoNLL-2002 공유 작업:
- esp.testa: 개발 단계를 위한 스페인어 테스트 데이터
- esp.testb: 스페인어 테스트 데이터
- esp.train: 스페인 열차 데이터
%pture
!wget -O 'conll2002.zip' 'https://drive.google.com/uc?export=download&id=1Wrl1b39ZXgKqCeAFNM9EoXtA1kzwNhCe'
!.unzip 'conll2002.zip'
각 데이터 집합의 크기입니다:
!wc -l conll2002/esp.train
!wc -l conll2002/esp.testa
!wc -l conll2002/esp.testb
273038 conll2002/esp.train
54838 conll2002/esp.testa
53050 conll2002/esp.testb
모든 데이터 파일에는 단어, 관련 품사 태그, IOB2 형식의 명명된 엔티티 태그의 세 가지 열이 있습니다. 문장 나누기는 빈 줄로 인코딩됩니다.
!head -n20 conll2002/esp.train
멜버른 NP B-LOC
( Fpa O
호주 NP B-LOC
) Fpt O
, Fc O
25 Z O
may NC O
( Fpa O
EFE NC B-ORG
) Fpt O
. Fp O
- Fg O
El DA O
Abogado NC B-PER
일반 AQ I-PER
델 SP I-PER
NC 상태 I-PER
, Fc O
훈련, 개발 및 테스트 데이터 세트의 경우 단어 열과 명명된 엔티티 태그 열만 유지합니다.
!cat conll2002/esp.train | cut -d " " -f 1,3 > train_temp.txt
!cat conll2002/esp.testa | cut -d " " -f 1,3 > dev_temp.txt
!cat conll2002/esp.testb | cut -d " " -f 1,3 > test_temp.txt
2. 전처리
추가 전처리 단계와 모델 학습에 필요한 몇 가지 변수를 정의해 보겠습니다:
MAX_LENGTH = 120 #@param {type: "정수"}
MODEL = "chriskhanhtran/spanberta" #@param ["chriskhanhtran/spanberta", "bert-base-multilingual-cased"]
아래 스크립트는 다음보다 긴 문장을 분할합니다. MAX_LENGTH (토큰 기준)을 작은 토큰으로 줄여야 합니다. 그렇지 않으면 토큰화할 때 긴 문장이 잘려서 학습 데이터가 손실되고 테스트 세트의 일부 토큰이 예측되지 않을 수 있습니다.
%pture
!.wget "https://raw.githubusercontent.com/stefan-it/fine-tuned-berts-seq/master/scripts/preprocess.py"
!python3 preprocess.py train_temp.txt $MODEL $MAX_LENGTH > train.txt
!python3 preprocess.py dev_temp.txt $MODEL $MAX_LENGTH > dev.txt
!python3 preprocess.py test_temp.txt $MODEL $MAX_LENGTH > test.txt
2020-04-22 23:02:05.747294: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] 동적 라이브러리 libcudart.so.10.1을 성공적으로 열었습니다.
다운로드 중입니다: 100% 1.03k/1.03k [00:00<00:00, 704kB/s]
다운로드 중입니다: 100% 954k/954k [00:00<00:00, 1.89MB/s]
다운로드 중: 100% 512k/512k [00:00<00:00, 1.19MB/s]
다운로드 중: 100% 16.0/16.0 [00:00<00:00, 12.6kB/s]
2020-04-22 23:02:23.409488: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] 동적 라이브러리 libcudart.so.10.1을 성공적으로 열었습니다.
2020-04-22 23:02:31.168967: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] 동적 라이브러리 libcudart.so.10.1을 성공적으로 열었습니다.
3. 라벨
CoNLL-2002/2003 데이터 세트에는 9가지 클래스의 NER 태그가 있습니다:
- O, 명명된 엔티티 외부
- B-MIS, 다른 기타 법인 바로 뒤의 기타 법인 시작
- I-MIS, 기타 법인
- B-PER, 다른 사람 이름 바로 뒤의 이름 시작 부분
- I-PER, 개인 이름
- B-ORG, 다른 조직의 바로 뒤에서 시작되는 조직의 시작
- I-ORG, 조직
- B-LOC, 다른 위치 바로 뒤에 있는 위치의 시작점
- I-LOC, 위치
데이터 집합에 CoNLL-2002/2003 데이터 집합과 다른 레이블이 있거나 더 많은 레이블이 있는 경우 아래 줄을 실행하여 데이터에서 고유 레이블을 가져와서 다음 위치에 저장합니다. labels.txt. 이 파일은 모델 미세 조정을 시작할 때 사용됩니다.
!cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
미세 조정 모델
다음은 다음의 예제 스크립트입니다. 트랜스포머의 저장소에서 NER용 모델을 미세 조정하는 데 사용할 것입니다. 2020년 4월 21일 이후 Hugging Face는 예제 스크립트를 업데이트하여 새로운 트레이너 클래스를 사용하세요. 향후 충돌을 방지하려면 이러한 업데이트 이전 버전을 사용하세요.
%pture
!wget "https://raw.githubusercontent.com/chriskhanhtran/spanish-bert/master/ner/run_ner.py"
!wget "https://raw.githubusercontent.com/chriskhanhtran/spanish-bert/master/ner/utils_ner.py"
이제 이전 학습을 할 차례입니다. 내 이전 블로그 게시물저는 대규모 스페인어 말뭉치에 대해 RoBERTa 언어 모델을 사전 학습시켜 문맥에 따라 마스크된 단어를 예측했습니다. 이를 통해 모델은 언어의 고유한 속성을 학습했습니다. 사전 학습된 모델을 허깅 페이스의 서버에 업로드했습니다. 이제 모델을 로드하고 NER 작업에 맞게 미세 조정을 시작하겠습니다.
아래는 트레이닝 하이퍼파라미터입니다.
MAX_LENGTH = 128 #@param {type: "정수"}
MODEL = "chriskhanhtran/spanberta" #@param ["chriskhanhtran/spanberta", "bert-base-multilingual-cased"]
OUTPUT_DIR = "spanberta-ner" #@param ["spanberta-ner", "bert-base-ml-ner"]
BATCH_SIZE = 32 #@param {type: "정수"}
NUM_EPOCHS = 3 #@param {type: "정수"}
SAVE_STEPS = 100 #@param {type: "integer"}
LOGGING_STEPS = 100 #@param {type: "정수"}
SEED = 42 #@param {type: "integer"}
교육을 시작하겠습니다.
!python3 run_ner.py
--data_dir ./
--model_type bert
--labels ./labels.txt
--model_name_or_path $MODEL
--output_dir $OUTPUT_DIR
--max_seq_length $MAX_LENGTH
--num_train_epochs $NUM_EPOCHS
--per_gpu_train_batch_size $BATCH_SIZE
--save_steps $SAVE_STEPS
--logging_steps $LOGGING_STEPS
--seed $SEED
--do_train
--do_eval
--do_predict
--overwrite_output_dir
개발 세트에서의 성능:
04/21/2020 02:24:31 - INFO - __main__ - ***** 평가 결과 *****
04/21/2020 02:24:31 - INFO - __main__ - f1 = 0.831027443864822
04/21/2020 02:24:31 - INFO - __main__ - 손실 = 0.1004064822183894
04/21/2020 02:24:31 - INFO - __main__ - 정밀도 = 0.8207885304659498
04/21/2020 02:24:31 - INFO - __main__ - recall = 0.8415250344510795
테스트 세트에서의 성능:
04/21/2020 02:24:48 - INFO - __main__ - ***** 평가 결과 *****
04/21/2020 02:24:48 - INFO - __main__ - f1 = 0.8559533721898419
04/21/2020 02:24:48 - INFO - __main__ - 손실 = 0.06848683688204177
04/21/2020 02:24:48 - INFO - __main__ - 정밀도 = 0.845858475041141
04/21/2020 02:24:48 - INFO - __main__ - recall = 0.8662921348314607
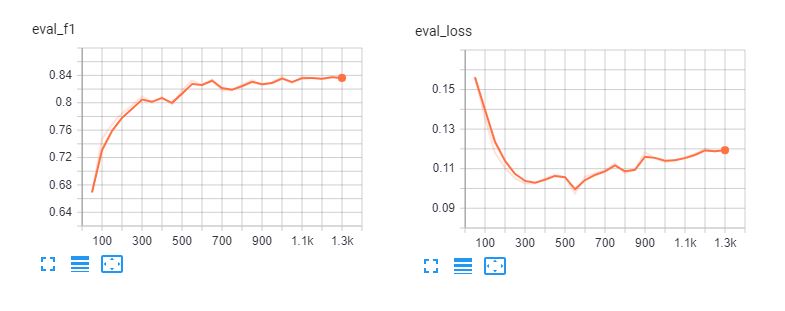
다음은 미세 조정의 텐서보드입니다. 스팬버타 및 bert-기반-다국어-케이스 를 5개의 에포크로 설정합니다. 3개의 에포크 이후에는 모델이 학습 데이터에 과도하게 적합하다는 것을 알 수 있습니다.
분류 보고서
모델이 실제로 얼마나 잘 작동하는지 이해하기 위해 예측을 로드하고 분류 보고서를 살펴 보겠습니다.
def read_examples_from_file(file_path):
"""CoNLL-2002/2003 데이터 파일에서 단어와 레이블을 읽습니다.
Args:
file_path (str): NER 데이터 파일의 경로.
반환합니다:
예시(딕셔너리): 두 개의 키가 있는 딕셔너리: words (목록 목록)
각 시퀀스에서 단어를 들고 레이블 (목록 목록) 보유
해당 레이블.
"""
열다(파일_경로, 인코딩="utf-8")를 f로 사용합니다:
examples = {"words": [], "labels": []}
words = []
labels = []
f의 줄에 대해
if line.startswith("-DOCSTART-") 또는 line == "" 또는 line == "\n":
if words:
examples["words"].append(words)
examples["labels"].append(labels)
words = []
labels = []
else:
splits = line.split(" ")
words.append(splits[0])
len(splits) > 1이면
labels.append(splits[-1].replace("\n", ""))
else:
# 예제에서는 mode = "test"에 대한 레이블이 없을 수 있습니다.
labels.append("O")
반환 예제
원시 텍스트 파일에서 데이터와 레이블을 읽습니다:
y_true = read_examples_from_file("test.txt")["labels"]
y_pred = read_examples_from_file("spanberta-ner/test_predictions.txt")["labels"]
분류 보고서를 인쇄합니다:
seqeval.metrics에서 classification_report를 classification_report_seqeval로 가져옵니다.
print(classification_report_seqeval(y_true, y_pred))
정밀 리콜 F1 점수 지원
LOC 0.87 0.84 0.85 1084
ORG 0.82 0.87 0.85 1401
기타 0.63 0.66 0.65 340
PER 0.94 0.96 0.95 735
마이크로 평균 0.84 0.86 0.85 3560
매크로 평균 0.84 0.86 0.85 3560
이 보고서에 표시되는 메트릭은 엔티티의 모든 단어가 정확하게 예측되어야 하나의 정확한 예측으로 계산되는 NER 및 POS 태깅과 같은 NLP 작업을 위해 특별히 설계되었습니다. 따라서 이 분류 보고서의 메트릭은 다음보다 훨씬 낮습니다. SCIKIT-Learn의 분류 보고서.
numpy를 np로 가져옵니다.
sklearn.metrics에서 classification_report 가져오기
print(classification_report(np.concatenate(y_true), np.concatenate(y_pred)))
정밀 리콜 F1 점수 지원
B-LOC 0.88 0.85 0.86 1084
B-MISC 0.73 0.73 0.73 339
B-OG 0.87 0.91 0.89 1400
B-PER 0.95 0.96 0.95 735
I-LOC 0.82 0.81 0.81 325
I-MISC 0.85 0.76 0.80 557
I-OG 0.89 0.87 0.88 1104
I-PER 0.98 0.98 0.98 634
O 1.00 1.00 1.00 45355
정확도 0.98 51533
매크로 평균 0.89 0.87 0.88 51533
WEIGHTED AVG 0.98 0.98 0.98 51533
위의 보고서에서 볼 수 있듯이 저희 모델은 사람, 위치, 조직을 예측하는 데 좋은 성능을 보입니다. 다음을 위해 더 많은 데이터가 필요합니다. MISC 엔티티를 추가하여 이러한 엔티티에 대한 모델의 성능을 개선합니다.
파이프라인
모델을 미세 조정한 후에는 이 튜토리얼에 따라 커뮤니티와 공유할 수 있습니다. 페이지. 이제 Hugging Face의 서버에서 미세 조정된 모델을 로드하여 스페인어 문서에서 명명된 엔티티를 예측하는 데 사용할 수 있습니다.
트랜스포머에서 가져오기 파이프라인, 자동 모델 포 토큰 분류, 자동 토큰 화기
model = AutoModelForTokenClassification.from_pretrained("skimai/spanberta-base-cased-ner-conll02")
토큰화기 = AutoTokenizer.from_pretrained("skimai/spanberta-base-cased-ner-conll02")
ner_model = 파이프라인('ner', 모델=모델, 토큰화기=토큰화기)
아래 예는 다음에서 가져온 것입니다. 의견 그리고 "스티븐 므누신 재무장관은 코로나19 팬데믹 이후 미국의 경제 회복은 수개월이 걸릴 것이라고 말했습니다."
시퀀스 = "La recuperación económica de los Estados United States después de la " \
"코로나 바이러스 팬데믹은 몇 달 안에 끝날 것이라고 " \
"스티븐 므누신 재무장관."
ner_model(시퀀스)
[{'entity': 'B-ORG', 'score': 0.9155661463737488, 'word': 'ĠEstados'},
{'entity': 'I-ORG', 'score': 0.800682544708252, 'word': 'ĠUnidos'},
{'entity': 'I-MISC', 'score': 0.5006815791130066, 'word': 'Ġcorona'},
{'entity': 'I-MISC', 'score': 0.510674774646759, 'word': 'virus'},
{'entity': 'B-PER', 'score': 0.5558510422706604, 'word': 'ĠSecretario'},
{'entity': 'I-PER', 'score': 0.7758238315582275, 'word': 'Ġdel'},
{'entity': 'I-PER', 'score': 0.7096233367919922, 'word': 'ĠTesoro'},
{'entity': 'B-PER', 'score': 0.9940345883369446, 'word': 'ĠSteven'},
{'entity': 'I-PER', 'score': 0.9962581992149353, 'word': 'ĠM'},
{'entity': 'I-PER', 'score': 0.9918380379676819, 'word': 'n'},
{'entity': 'I-PER', 'score': 0.9848328828811646, 'word': 'uch'},
{'entity': 'I-PER', 'score': 0.8513168096542358, 'word': 'in'}]
멋지네요! 미세 조정된 모델은 예제에서 모든 엔티티를 성공적으로 인식하고 심지어 "코로나 바이러스"도 인식합니다.
결론
명명된 개체 인식은 텍스트에서 중요한 정보를 빠르게 추출하는 데 도움이 될 수 있습니다. 따라서 비즈니스에 적용하면 계약서나 문서를 읽는 사람의 생산성 향상에 직접적인 영향을 미칠 수 있습니다. 그러나 NER은 단어 수준에서 정확한 분류가 필요하기 때문에 백오브워드와 같은 단순한 접근 방식으로는 이 작업을 처리할 수 없기 때문에 까다로운 NLP 작업입니다.
사전 학습된 BERT 모델을 활용하여 스페인어에 대한 NER 작업에서 우수한 성능을 빠르게 얻을 수 있는 방법을 살펴보았습니다. 사전 훈련된 SpanBERTa 모델은 문서 분류와 같은 다른 작업에도 미세 조정할 수 있습니다. 시퀀스 분류 및 감정 분석을 위해 BERT를 미세 조정하는 자세한 튜토리얼을 작성했습니다.
이 시리즈의 다음 3부에서는 최신 성능을 빠르게 달성할 수 있는 변압기 모델에 대한 보다 효율적인 사전 교육 접근 방식인 ELECTRA를 사용하는 방법에 대해 설명합니다. 기대해주세요!


