
Tutorial: Feinabstimmung von BERT für die Erkennung von benannten Entitäten (NER)



Anleitung: Wie man BERT für NER fein abstimmt
Ursprünglich veröffentlicht von Skim AI's Machine Learning Researcher, Chris Tran.![]()
Einführung
Dieser Artikel befasst sich mit der Feinabstimmung von BERT für die Erkennung von benannten Entitäten (NER). Genauer gesagt, wie man eine BERT-Variante, SpanBERTa, für NER trainiert. Es ist Teil II von III in einer Serie über das Training von benutzerdefinierten BERT-Sprachmodellen für Spanisch für eine Vielzahl von Anwendungsfällen:
- Teil I: Wie man ein RoBERTa-Sprachmodell für Spanisch von Grund auf trainiert
- Teil III: Wie man ein ELECTRA-Sprachmodell für Spanisch von Grund auf trainiert
In meinem letzten Blogbeitrag haben wir erörtert, wie mein Team SpanBERTa, ein Transformer-Sprachmodell für Spanisch, auf einem großen Korpus von Grund auf trainiert hat. Das Modell hat gezeigt, dass es in der Lage ist, korrekt maskierte Wörter in einer Sequenz auf der Grundlage ihres Kontexts vorherzusagen. In diesem Blog-Beitrag werden wir SpanBERTa für eine Aufgabe zur Erkennung von Namen abstimmen, um die Leistung von Transformatormodellen wirklich zu nutzen.
Gemäß seiner Definition auf WikipediaDie Erkennung von benannten Entitäten (NER) (auch bekannt als Entity Identification, Entity Chunking und Entity Extraction) ist eine Teilaufgabe der Informationsextraktion, die darauf abzielt, benannte Entitäten, die in unstrukturiertem Text erwähnt werden, zu finden und in vordefinierte Kategorien wie Personennamen, Organisationen, Orte, medizinische Codes, Zeitangaben, Mengen, Geldwerte, Prozentsätze usw. einzuordnen.
Wir werden das Skript verwenden run_ner.py von Hugging Face und CoNLL-2002-Datensatz zur Feinabstimmung von SpanBERTa.
Einrichtung
Herunterladen Transformatoren und installieren Sie die erforderlichen Pakete.
%%capture
!git clone https://github.com/huggingface/transformers
%cd transformers
!pip install .
!pip install -r ./examples/requirements.txt
%cd ..
Daten
1. Datensätze herunterladen
Mit dem folgenden Befehl wird der Datensatz heruntergeladen und entpackt. Die Dateien enthalten die Trainings- und Testdaten für drei Teile des CoNLL-2002 gemeinsame Aufgabe:
- esp.testa: Spanische Testdaten für die Entwicklungsphase
- esp.testb: Spanische Testdaten
- esp.train: Spanische Zugdaten
%pture
!wget -O 'conll2002.zip' 'https://drive.google.com/uc?export=download&id=1Wrl1b39ZXgKqCeAFNM9EoXtA1kzwNhCe'
!unzip 'conll2002.zip'
Die Größe der einzelnen Datensätze:
!wc -l conll2002/esp.train
!wc -l conll2002/esp.testa
!wc -l conll2002/esp.testb
273038 conll2002/esp.train
54838 conll2002/esp.testa
53050 conll2002/esp.testb
Alle Datendateien haben drei Spalten: Wörter, zugehörige Part-of-Speech-Tags und Named-Entity-Tags im IOB2-Format. Satzumbrüche werden durch Leerzeilen kodiert.
!head -n20 conll2002/esp.train
Melbourne NP B-LOC
( Fpa O
Australien NP B-LOC
) Fpt O
, Fc O
25 Z O
kann NC O
( Fpa O
EFE NC B-ORG
) Fpt O
. Fp O
- Fg O
El DA O
Abogado NC B-PER
Allgemein AQ I-PER
del SP I-PER
Estado NC I-PER
Fc O
Wir werden nur die Wortspalte und die Named-Entity-Tag-Spalte für unsere Trainings-, Entwicklungs- und Testdatensätze beibehalten.
!cat conll2002/esp.train | cut -d " " -f 1,3 > train_temp.txt
!cat conll2002/esp.testa | cut -d " " -f 1,3 > dev_temp.txt
!cat conll2002/esp.testb | cut -d " " -f 1,3 > test_temp.txt
2. Vorverarbeitung
Lassen Sie uns einige Variablen definieren, die wir für weitere Vorverarbeitungsschritte und das Training des Modells benötigen:
MAX_LENGTH = 120 #@param {type: "integer"}
MODELL = "chriskhanhtran/spanberta" #@param ["chriskhanhtran/spanberta", "bert-base-multilingual-cased"]
Das folgende Skript trennt Sätze, die länger als MAX_LÄNGE (in Form von Token) in kleine Sätze zerlegen. Andernfalls werden lange Sätze bei der Tokenisierung abgeschnitten, wodurch Trainingsdaten verloren gehen und einige Token im Testsatz nicht vorhergesagt werden können.
%pture
!wget "https://raw.githubusercontent.com/stefan-it/fine-tuned-berts-seq/master/scripts/preprocess.py"
!python3 preprocess.py train_temp.txt $MODEL $MAX_LENGTH > train.txt
!python3 preprocess.py dev_temp.txt $MODEL $MAX_LENGTH > dev.txt
!python3 preprocess.py test_temp.txt $MODEL $MAX_LENGTH > test.txt
2020-04-22 23:02:05.747294: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Erfolgreich geöffnete dynamische Bibliothek libcudart.so.10.1
Wird heruntergeladen: 100% 1.03k/1.03k [00:00<00:00, 704kB/s]
Herunterladen: 100% 954k/954k [00:00<00:00, 1.89MB/s]
Herunterladen: 100% 512k/512k [00:00<00:00, 1.19MB/s]
Herunterladen: 100% 16.0/16.0 [00:00<00:00, 12.6kB/s]
2020-04-22 23:02:23.409488: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Erfolgreich geöffnete dynamische Bibliothek libcudart.so.10.1
2020-04-22 23:02:31.168967: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Erfolgreich geöffnete dynamische Bibliothek libcudart.so.10.1
3. Etiketten
In den CoNLL-2002/2003-Datensätzen gibt es 9 Klassen von NER-Tags:
- O, Außerhalb einer benannten Entität
- B-MIS, Beginn einer gemischten Einheit direkt nach einer anderen gemischten Einheit
- I-MIS, Sonstiges Unternehmen
- B-PER, Beginn des Namens einer Person direkt nach dem Namen einer anderen Person
- I-PER, Name der Person
- B-ORG, Beginn einer Organisation direkt nach einer anderen Organisation
- I-ORG, Organisation
- B-LOC, Beginn eines Ortes direkt nach einem anderen Ort
- I-LOC, Standort
Wenn Ihr Datensatz andere Beschriftungen oder mehr Beschriftungen als die CoNLL-2002/2003-Datensätze hat, führen Sie die folgende Zeile aus, um eindeutige Beschriftungen aus Ihren Daten zu erhalten und speichern Sie sie in kennzeichnungen.txt. Diese Datei wird verwendet, wenn wir mit der Feinabstimmung unseres Modells beginnen.
!cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
Feinabstimmung Modell
Dies sind die Beispielskripte aus Transformatorendie wir für die Feinabstimmung unseres Modells für NER verwenden werden. Nach dem 21.04.2020 hat Hugging Face seine Beispielskripte aktualisiert, um eine neue Trainer Klasse. Um künftige Konflikte zu vermeiden, sollten wir die Version vor diesen Aktualisierungen verwenden.
%pture
!wget "https://raw.githubusercontent.com/chriskhanhtran/spanish-bert/master/ner/run_ner.py"
!wget "https://raw.githubusercontent.com/chriskhanhtran/spanish-bert/master/ner/utils_ner.py"
Jetzt ist es Zeit für den Lerntransfer. In meinem vorheriger BlogeintragIch habe ein RoBERTa-Sprachmodell auf einem sehr großen spanischen Korpus vortrainiert, um maskierte Wörter auf der Grundlage des Kontexts, in dem sie stehen, vorherzusagen. Auf diese Weise hat das Modell inhärente Eigenschaften der Sprache gelernt. Ich habe das trainierte Modell auf den Server von Hugging Face hochgeladen. Jetzt werden wir das Modell laden und mit der Feinabstimmung für die NER-Aufgabe beginnen.
Nachfolgend sind unsere Trainings-Hyperparameter aufgeführt.
MAX_LENGTH = 128 #@param {type: "integer"}
MODELL = "chriskhanhtran/spanberta" #@param ["chriskhanhtran/spanberta", "bert-base-multilingual-cased"]
OUTPUT_DIR = "spanberta-ner" #@param ["spanberta-ner", "bert-base-ml-ner"]
BATCH_SIZE = 32 #@param {type: "integer"}
NUM_EPOCHS = 3 #@param {Typ: "integer"}
SAVE_STEPS = 100 #@param {Typ: "integer"}
LOGGING_STEPS = 100 #@param {Typ: "integer"}
SEED = 42 #@param {Typ: "integer"}
Beginnen wir mit der Ausbildung.
!python3 run_ner.py
--data_dir ./
--model_type bert
--Labels ./labels.txt
--modell_name_oder_pfad $MODEL
--output_dir $OUTPUT_DIR
--max_seq_length $MAX_LENGTH
--num_train_epochs $NUM_EPOCHS
--pro_gpu_train_batch_size $BATCH_SIZE
--Speicher-Schritte $SAVE_STEPS
--Protokollierung_Schritte $LOGGING_STEPS
--Saatgut $SEED
--do_train
--do_eval
--do_predict
--overwrite_output_dir
Leistung auf dem Dev-Set:
21.04.2020 02:24:31 - INFO - __main__ - ***** Auswertungsergebnisse *****
21.04.20 02:24:31 - INFO - __main__ - f1 = 0.831027443864822
21.04.20 02:24:31 - INFO - __main__ - Verlust = 0.1004064822183894
21.04.20 02:24:31 - INFO - __main__ - Genauigkeit = 0.8207885304659498
21.04.2020 02:24:31 - INFO - __main__ - recall = 0.8415250344510795
Leistung auf dem Testsatz:
21.04.2020 02:24:48 - INFO - __main__ - ***** Auswertungsergebnisse *****
21.04.2020 02:24:48 - INFO - __main__ - f1 = 0.8559533721898419
21.04.20 02:24:48 - INFO - __main__ - Verlust = 0.06848683688204177
21.04.20 02:24:48 - INFO - __main__ - Genauigkeit = 0.845858475041141
21.04.2020 02:24:48 - INFO - __main__ - recall = 0.8662921348314607
Hier sind die Tensorboards der Feinabstimmung spanberta und bert-base-multilingual-cased für 5 Epochen. Wir können sehen, dass die Modelle die Trainingsdaten nach 3 Epochen übererfüllen.
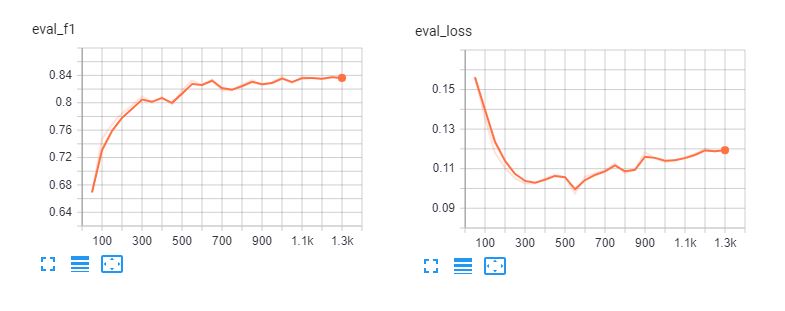
Klassifizierungsbericht
Um zu verstehen, wie gut unser Modell tatsächlich abschneidet, laden wir seine Vorhersagen und prüfen den Klassifizierungsbericht.
def read_examples_from_file(file_path):
"""Liest Wörter und Bezeichnungen aus einer CoNLL-2002/2003-Datendatei.
Args:
file_path (str): Pfad zur NER-Datendatei.
Rückgabe:
examples (dict): ein Wörterbuch mit zwei Schlüsseln: Wörter (Liste von Listen)
die Wörter in jeder Sequenz enthalten, und Etiketten (Liste von Listen) mit
entsprechenden Etiketten.
"""
with open(file_path, encoding="utf-8") as f:
examples = {"words": [], "labels": []}
words = []
labels = []
for line in f:
if line.startswith("-DOCSTART-") oder line == "" oder line == "\n":
if words:
examples["words"].append(words)
examples["labels"].append(labels)
words = []
labels = []
sonst:
splits = line.split(" ")
words.append(splits[0])
if len(splits) > 1:
labels.append(splits[-1].replace("\n", ""))
sonst:
# Beispiele konnten keine Beschriftung für mode = "test" haben
labels.append("O")
Beispiele zurückgeben
Lesen von Daten und Beschriftungen aus den Rohtextdateien:
y_true = read_examples_from_file("test.txt")["labels"]
y_pred = read_examples_from_file("spanberta-ner/test_predictions.txt")["labels"]
Drucken Sie den Klassifizierungsbericht:
from seqeval.metrics import classification_report as classification_report_seqeval
print(classification_report_seqeval(y_true, y_pred))
Genauigkeit Rückruf f1-Score Unterstützung
LOC 0.87 0.84 0.85 1084
ORG 0.82 0.87 0.85 1401
MISC 0.63 0.66 0.65 340
PRO 0,94 0,96 0,95 735
Mikro-Durchschnittswert 0,84 0,86 0,85 3560
Makro-Durchschnittswert 0,84 0,86 0,85 3560
Die Metriken, die wir in diesem Bericht sehen, wurden speziell für NLP-Aufgaben wie NER und POS-Tagging entwickelt, bei denen alle Wörter einer Entität korrekt vorhergesagt werden müssen, um als eine korrekte Vorhersage gezählt zu werden. Daher sind die Metriken in diesem Klassifikationsbericht viel niedriger als in scikit-learns Klassifizierungsbericht.
import numpy as np
from sklearn.metrics import classification_report
print(classification_report(np.concatenate(y_true), np.concatenate(y_pred)))
Genauigkeit Rückruf f1-Score Unterstützung
B-LOC 0.88 0.85 0.86 1084
B-MISC 0.73 0.73 0.73 339
B-ORG 0.87 0.91 0.89 1400
B-PER 0,95 0,96 0,95 735
I-LOC 0,82 0,81 0,81 325
I-MISC 0,85 0,76 0,80 557
I-ORG 0,89 0,87 0,88 1104
I-PER 0,98 0,98 0,98 634
O 1.00 1.00 1.00 45355
Genauigkeit 0,98 51533
Makro-Durchschnittswert 0,89 0,87 0,88 51533
gewichteter Mittelwert 0,98 0,98 0,98 51533
Aus den obigen Berichten geht hervor, dass unser Modell eine gute Leistung bei der Vorhersage von Person, Ort und Organisation aufweist. Wir benötigen mehr Daten für MISC Entitäten, um die Leistung unseres Modells für diese Entitäten zu verbessern.
Pipeline
Nach der Feinabstimmung unserer Modelle können wir sie mit der Gemeinschaft teilen, indem wir die Anleitung in diesem Seite. Jetzt können wir damit beginnen, das fein abgestimmte Modell vom Hugging Face-Server zu laden und es zur Vorhersage von benannten Entitäten in spanischen Dokumenten zu verwenden.
from transformers import pipeline, AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("skimai/spanberta-base-cased-ner-conll02")
tokenizer = AutoTokenizer.from_pretrained("skimai/spanberta-base-cased-ner-conll02")
ner_model = pipeline('ner', model=model, tokenizer=tokenizer)
Das folgende Beispiel stammt aus La Opinión und bedeutet "Die wirtschaftliche Erholung der Vereinigten Staaten nach der Coronavirus-Pandemie wird eine Frage von Monaten sein, sagte Finanzminister Steven Mnuchin."
sequence = "La recuperación económica de los Estados Unidos después de la " \
"pandemia del coronavirus será cuestión de meses, afirmó el " \
"Secretario del Tesoro, Steven Mnuchin."
ner_model(sequence)
[{'entity': 'B-ORG', 'score': 0.9155661463737488, 'word': 'ĠEstados'},
{'entity': 'I-ORG', 'Punktzahl': 0.800682544708252, 'Wort': 'ĠUnidos'},
{'entity': 'I-MISC', 'Punktzahl': 0.5006815791130066, 'Wort': 'Ġcorona'},
{'entity': 'I-MISC', 'Punktzahl': 0.510674774646759, 'Wort': 'Virus'},
{'entity': 'B-PER', 'Punktzahl': 0.5558510422706604, 'Wort': 'ĠSecretario'},
{'entity': 'I-PER', 'Punktzahl': 0.7758238315582275, 'Wort': 'Ġdel'},
{'entity': 'I-PER', 'Punktzahl': 0.7096233367919922, 'Wort': 'ĠTesoro'},
{'entity': 'B-PER', 'Punktzahl': 0.9940345883369446, 'Wort': 'ĠSteven'},
{'entity': 'I-PER', 'Punktzahl': 0.9962581992149353, 'Wort': 'ĠM'},
{'entity': 'I-PER', 'Punktzahl': 0.9918380379676819, 'Wort': 'n'},
{'entity': 'I-PER', 'Punktzahl': 0.9848328828811646, 'Wort': 'uch'},
{'entity': 'I-PER', 'Punktzahl': 0.8513168096542358, 'Wort': 'in'}]
Sieht toll aus! Das fein abgestimmte Modell erkennt erfolgreich alle Entitäten in unserem Beispiel und erkennt sogar den "Coronavirus".
Schlussfolgerung
Die Erkennung von Namen kann uns helfen, schnell wichtige Informationen aus Texten zu extrahieren. Daher kann ihre Anwendung im Geschäftsleben einen direkten Einfluss auf die Verbesserung der menschlichen Produktivität beim Lesen von Verträgen und Dokumenten haben. Es handelt sich jedoch um eine anspruchsvolle NLP-Aufgabe, da die NER eine genaue Klassifizierung auf Wortebene erfordert, so dass einfache Ansätze wie Bag-of-Word diese Aufgabe nicht bewältigen können.
Wir haben uns angeschaut, wie wir ein vortrainiertes BERT-Modell nutzen können, um schnell eine hervorragende Leistung bei der NER-Aufgabe für Spanisch zu erzielen. Das vortrainierte SpanBERTa-Modell kann auch für andere Aufgaben wie die Dokumentenklassifikation feinabgestimmt werden. Ich habe ein detailliertes Tutorial zur Feinabstimmung von BERT für Sequenzklassifikation und Sentimentanalyse geschrieben.
Der nächste Teil dieser Serie ist Teil 3, in dem wir die Verwendung von ELECTRA erörtern, einem effizienteren Pre-Training-Ansatz für Transformatormodelle, mit dem sich schnell modernste Leistungen erzielen lassen. Bleiben Sie dran!


