
Tutorial: Feinabstimmung von BERT für die extraktive Verdichtung



Tutorial: Feinabstimmung von BERT für die extraktive Verdichtung
Ursprünglich veröffentlicht von Skim AI's Machine Learning Researcher, Chris Tran![]()
1. Einleitung
Die Zusammenfassung ist seit langem eine Herausforderung in der natürlichen Sprachverarbeitung. Um eine kurze Version eines Dokuments zu erstellen und dabei die wichtigsten Informationen beizubehalten, benötigen wir ein Modell, das in der Lage ist, die wichtigsten Punkte genau zu extrahieren und gleichzeitig wiederholte Informationen zu vermeiden. Erfreulicherweise haben die jüngsten Arbeiten im Bereich der NLP, wie z. B. Transformer-Modelle und das Vortraining von Sprachmodellen, den Stand der Technik bei der Zusammenfassung verbessert.
In diesem Artikel werden wir BERTSUM, eine einfache Variante von BERT, für die extraktive Zusammenfassung von Textzusammenfassung mit vortrainierten Kodierern (Liu et al., 2019). In dem Bemühen, die extraktive Zusammenfassung für Geräte mit geringen Ressourcen noch schneller und kleiner zu machen, werden wir DistilBERT feinabstimmen (Sanh et al. (2019)) und MobileBERT (Sun et al. (2019).), zwei aktuelle Lite-Versionen von BERT, und diskutieren unsere Ergebnisse.
2. Extraktive Zusammenfassungen
Es gibt zwei Arten der Verdichtung: abstrakt und extraktive Verdichtung. Bei der abstrakten Zusammenfassung werden die wichtigsten Punkte neu geschrieben, während bei der extraktiven Zusammenfassung die wichtigsten Abschnitte/Sätze direkt aus einem Dokument kopiert werden.
Abstrakte Zusammenfassungen sind für Menschen anspruchsvoller und für Maschinen rechenintensiver. Welche Zusammenfassung besser ist, hängt jedoch vom Zweck des Endnutzers ab. Wenn Sie einen Aufsatz schreiben, ist die abstrakte Zusammenfassung vielleicht die bessere Wahl. Wenn Sie hingegen recherchieren und eine schnelle Zusammenfassung des Gelesenen benötigen, wäre die extraktive Zusammenfassung hilfreicher.
In diesem Abschnitt werden wir die Architektur unseres extraktiven Zusammenfassungsmodells untersuchen. Die BERT-Zusammenfassung besteht aus zwei Teilen: einem BERT-Encoder und einem Zusammenfassungsklassifikator.
BERT-Encoder

Die Übersichtsarchitektur von BERTSUM
Unser BERT-Encoder ist der vortrainierte BERT-Basis-Encoder aus der maskierten Sprachmodellierungsaufgabe (Devlin et at., 2018). Die Aufgabe der extraktiven Zusammenfassung ist ein binäres Klassifikationsproblem auf Satzebene. Wir wollen jedem Satz ein Label $y_i \in {0, 1}$ zuweisen, das angibt, ob der Satz in die endgültige Zusammenfassung aufgenommen werden soll. Daher müssen wir ein Token hinzufügen [CLS] vor jedem Satz. Nach einem Vorwärtsdurchlauf durch den Encoder wird die letzte versteckte Schicht dieser [CLS] Token werden als Repräsentanten für unsere Sätze verwendet.
Zusammenfassender Klassifikator
Nachdem wir die Vektordarstellung jedes Satzes erhalten haben, können wir eine einfache Feed-Forward-Schicht als unseren Klassifikator verwenden, um eine Punktzahl für jeden Satz zu erhalten. In der Arbeit experimentierte der Autor mit einem einfachen linearen Klassifikator, einem rekurrenten neuronalen Netz und einem kleinen Transformer-Modell mit 3 Schichten. Der Transformer-Klassifikator liefert die besten Ergebnisse und zeigt, dass die Interaktion zwischen den Sätzen durch den Mechanismus der Selbstbeobachtung wichtig für die Auswahl der wichtigsten Sätze ist.
Im Encoder lernen wir also die Interaktionen zwischen den Token in unserem Dokument, während wir im Zusammenfassungsklassifikator die Interaktionen zwischen den Sätzen lernen.
3. Noch schnelleres Zusammenfassen
Transformer-Modelle erreichen in den meisten NLP-Bechmarks Spitzenleistungen; das Training und die Erstellung von Vorhersagen auf der Grundlage dieser Modelle sind jedoch sehr rechenintensiv. In dem Bemühen, die Zusammenfassung leichter und schneller zu machen, damit sie auf Geräten mit geringen Ressourcen eingesetzt werden kann, habe ich die Quellcodes von den Autoren von BERTSUM zur Verfügung gestellt, um den BERT-Encoder durch DistilBERT und MobileBERT zu ersetzen. Die zusammenfassenden Schichten werden unverändert beibehalten.
Hier sind die Trainingsverluste dieser 3 Varianten: TensorBoard

Obwohl DistilBERT 40% kleiner ist als BERT-base, hat es die gleichen Trainingsverluste wie BERT-base, während MobileBERT etwas schlechter abschneidet. Die folgende Tabelle zeigt die Leistung der beiden Verfahren für den CNN/DailyMail-Datensatz, die Größe und die Laufzeit eines Vorwärtsdurchlaufs:
| Modelle | ROUGE-1 | ROUGE-2 | ROUGE-L | Inferenzzeit* | Größe | Params |
|---|---|---|---|---|---|---|
| bert-base | 43.23 | 20.24 | 39.63 | 1.65 s | 475 MB | 120.5 M |
| destilliert | 42.84 | 20.04 | 39.31 | 925 ms | 310 MB | 77.4 M |
| mobilebert | 40.59 | 17.98 | 36.99 | 609 ms | 128 MB | 30.8 M |
*Durchschnittliche Laufzeit eines Vorwärtsdurchlaufs auf einer einzelnen GPU auf einem Standard-Google-Colab-Notebook
DistilBERT ist 45% schneller und hat damit fast die gleiche Leistung wie BERT-base. MobileBERT behält die 94% Leistung von BERT-base bei, ist aber 4x kleiner als BERT-base und 2,5x kleiner als DistilBERT. Im MobileBERT-Papier wird gezeigt, dass MobileBERT DistilBERT bei SQuAD v1.1 signifikant übertrifft, was jedoch nicht für die extraktive Zusammenfassung gilt. Aber das ist immer noch ein beeindruckendes Ergebnis für MobileBERT mit einer Plattengröße von nur 128 MB.
4. Fassen wir zusammen
Alle vortrainierten Checkpoints, Trainingsdetails und Einrichtungsanweisungen finden Sie unter dieses GitHub-Repository. Darüber hinaus habe ich eine Demo von BERTSUM mit dem MobileBERT-Encoder bereitgestellt.
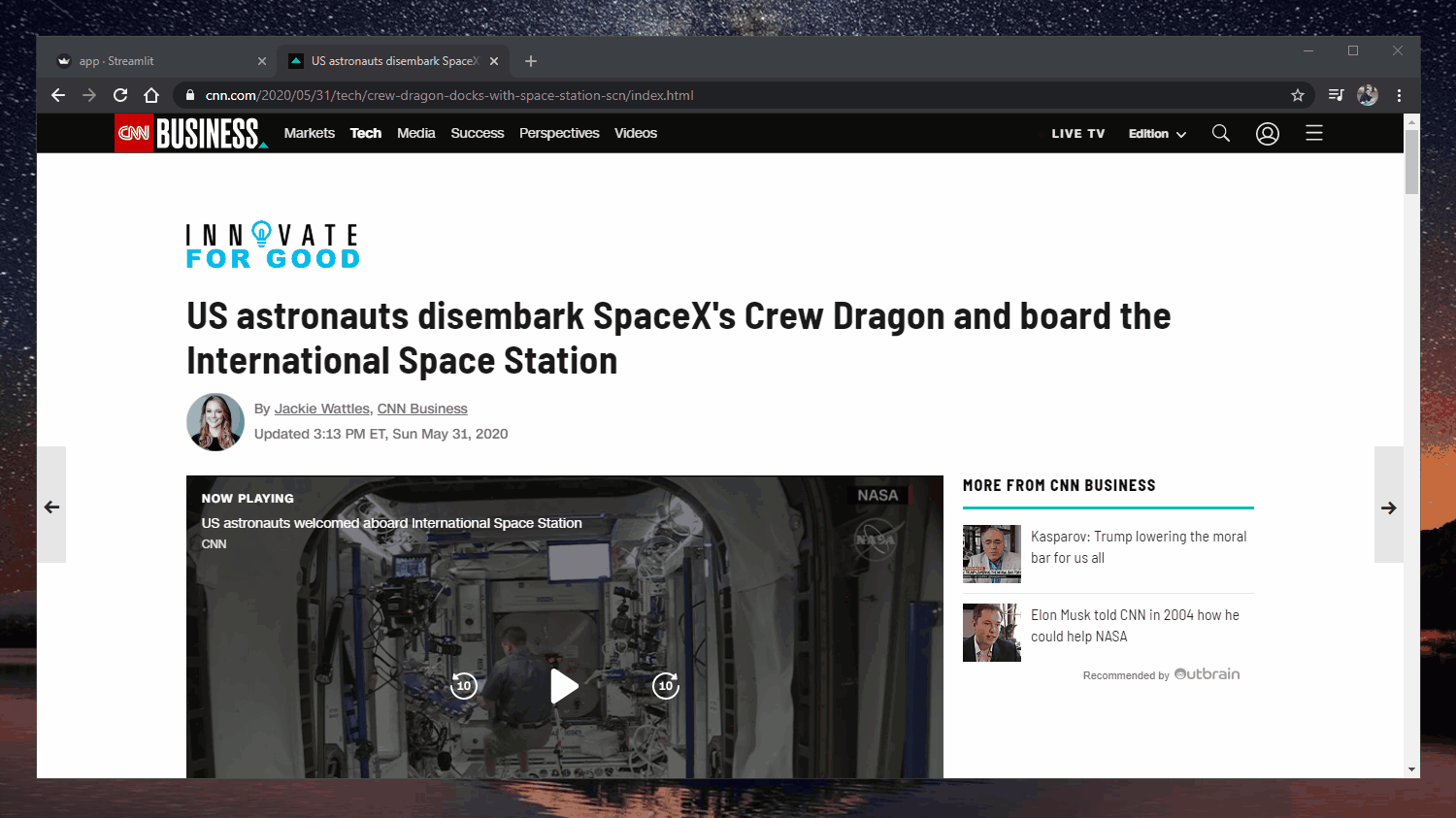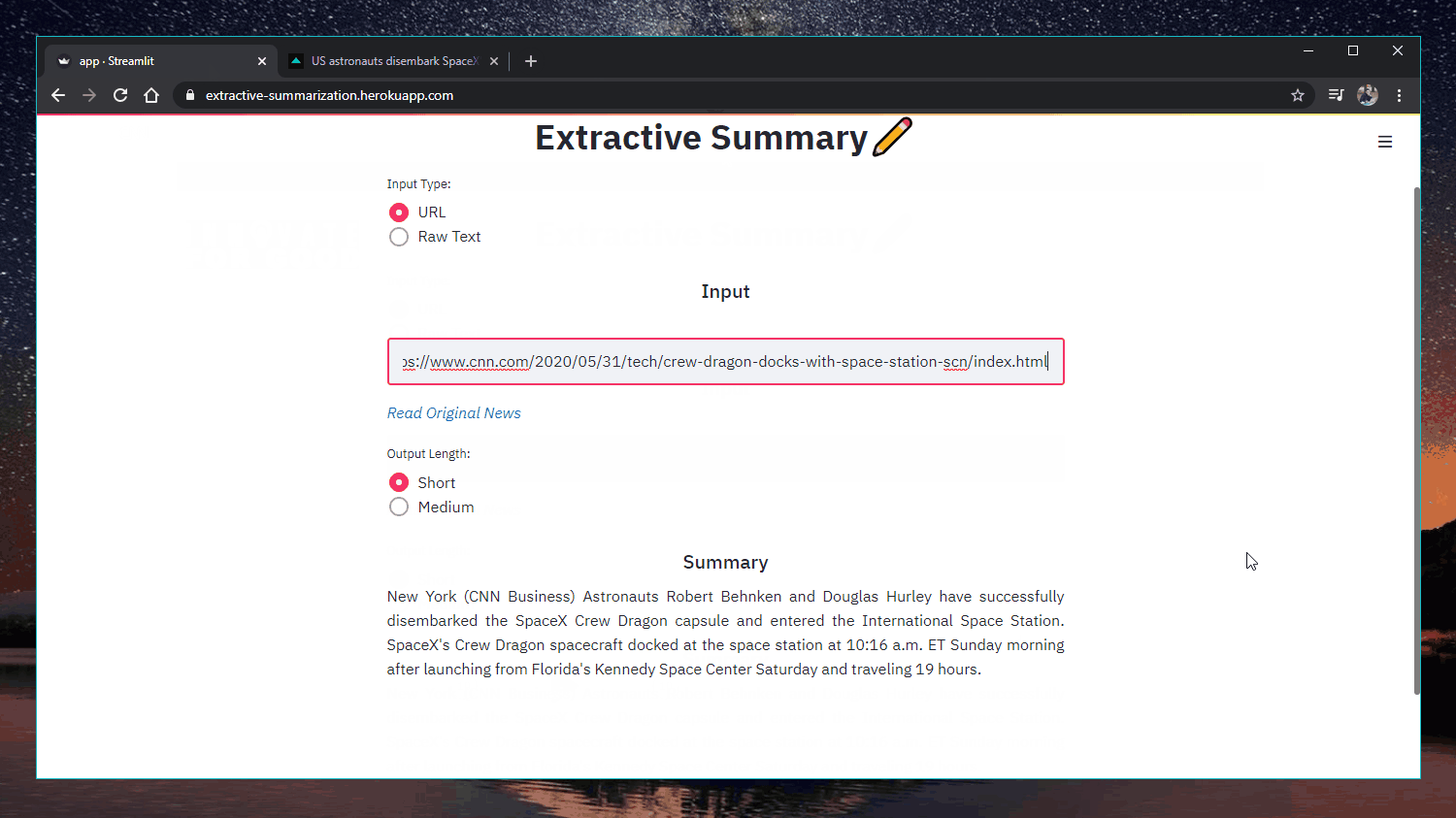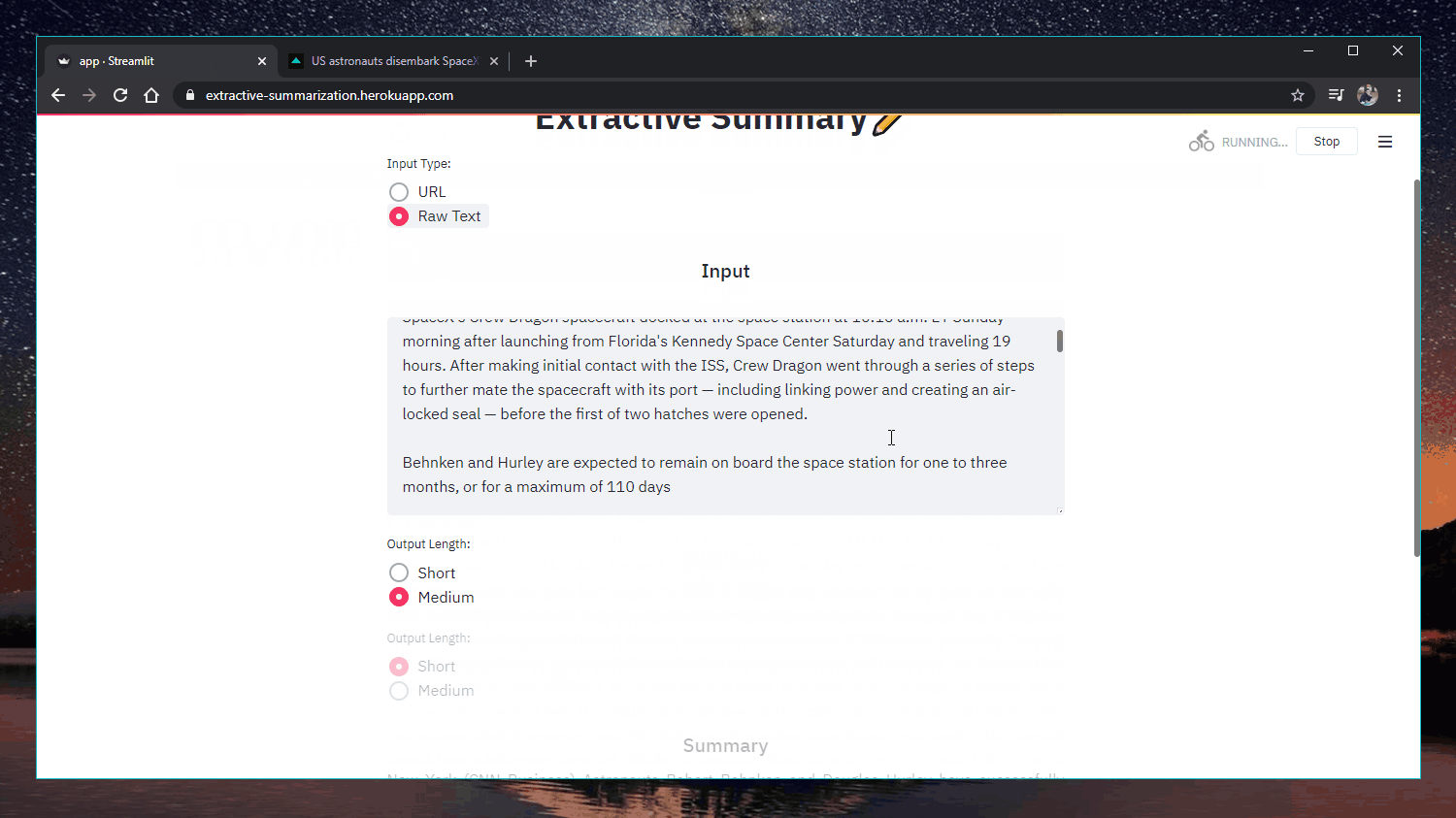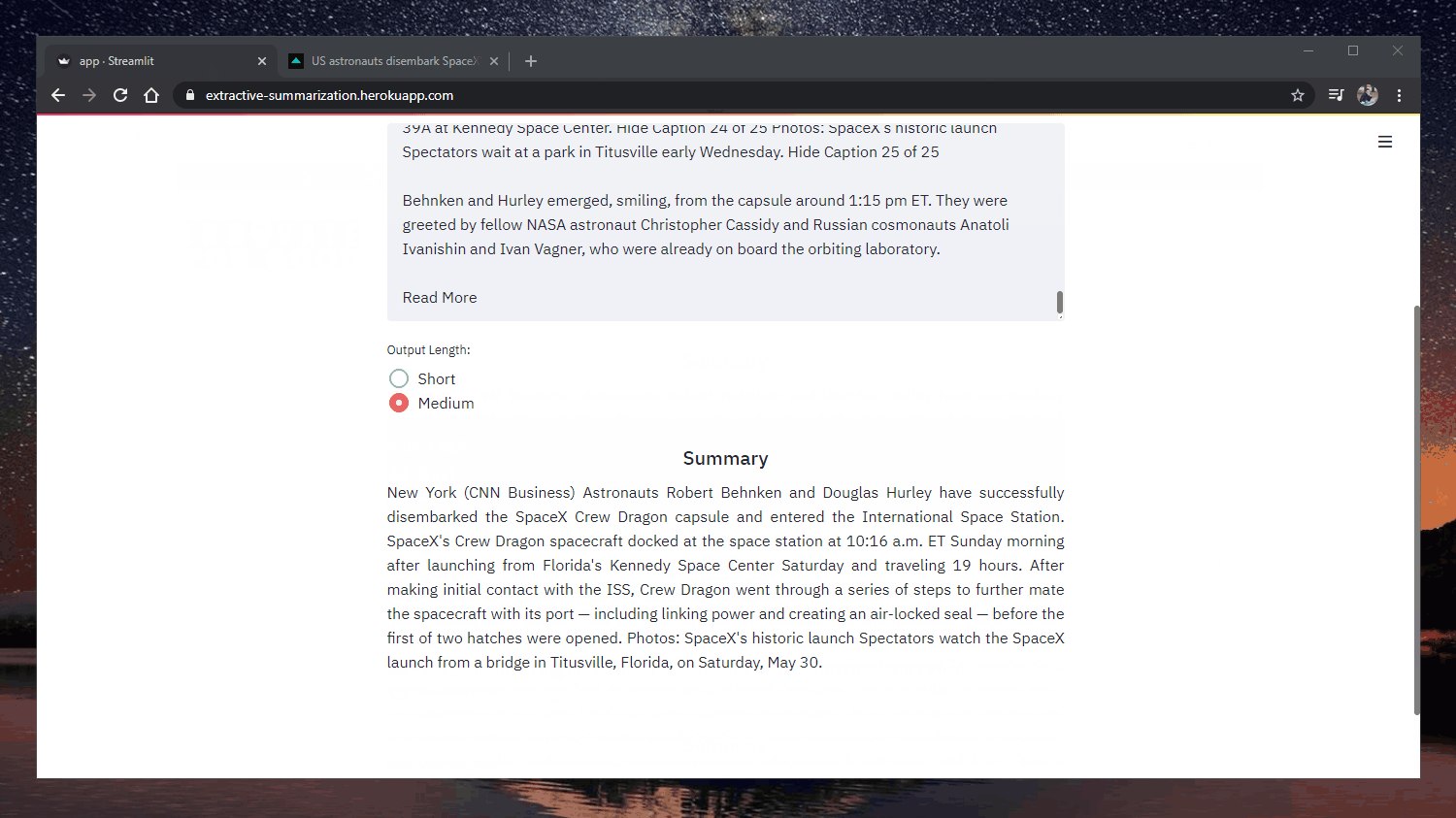
Web-App: https://extractive-summarization.herokuapp.com/
![]()
Code:
![]()
torch importieren
from models.model_builder import ExtSummarizer
from ext_sum importieren zusammenfassen
# Modell laden
model_type = 'mobilebert' #@param ['bertbase', 'distilbert', 'mobilebert']
checkpoint = torch.load(f'checkpoints/{model_type}_ext.pt', map_location='cpu')
model = ExtSummarizer(checkpoint=checkpoint, bert_type=model_type, device='cpu')
# Laufende Verdichtung
eingabe_fp = 'rohe_daten/eingabe.txt'
result_fp = 'ergebnisse/zusammenfassung.txt'
Zusammenfassung = zusammenfassen(eingabe_fp, ergebnis_fp, modell, max_length=3)
print(Zusammenfassung)
Zusammenfassende Probe
Original: https://www.cnn.com/2020/05/22/business/hertz-bankruptcy/index.html
Mit der Anmeldung des Konkurses will Hertz nach eigenen Angaben den Geschäftsbetrieb aufrechterhalten, seine Schulden umstrukturieren und als
finanziell gesünderes Unternehmen. Das Unternehmen vermietet seit 1918 Autos, als es sich mit einem Dutzend Ford Model Ts niederließ.
Es hat die Große Depression, die Einstellung der US-Autoproduktion während des Zweiten Weltkriegs
und zahlreiche Ölpreisschocks. "Die Auswirkungen von Covid-19 auf die Reisenachfrage waren plötzlich und dramatisch und verursachten einen
abrupter Rückgang der Einnahmen des Unternehmens und künftiger Buchungen", heißt es in der Erklärung des Unternehmens.
5. Schlussfolgerung
In diesem Artikel haben wir BERTSUM, eine einfache Variante von BERT, für die extraktive Zusammenfassung von Papieren untersucht Textzusammenfassung mit vortrainierten Kodierern (Liu et al., 2019). Um die extraktive Zusammenfassung für Geräte mit geringen Ressourcen noch schneller und kleiner zu machen, haben wir DistilBERT (Sanh et al., 2019) und MobileBERT (Sun et al., 2019) auf CNN/DailyMail-Datensätzen feinabgestimmt.
DistilBERT behält die Leistung von BERT-base bei der extraktiven Zusammenfassung bei, ist aber 45% kleiner. MobileBERT ist 4x kleiner und 2,7x schneller als BERT-base, behält aber 94% seiner Leistung bei.
Schließlich haben wir eine Web-App-Demo von MobileBERT für extraktive Zusammenfassungen auf https://extractive-summarization.herokuapp.com/.


