
Tutoriel : Comment affiner l'ORET pour la reconnaissance d'entités nommées (NER)



Tutoriel : Comment affiner le BERT pour le NER
Publié à l'origine par Chris Tran, chercheur en apprentissage automatique chez Skim AI.![]()
Introduction
Cet article traite de l'optimisation de l'ORET pour la reconnaissance d'entités nommées (NER). Plus précisément, comment former une variante de l'ORET, SpanBERTa, pour la NER. Il s'agit de la partie II de III d'une série sur la formation de modèles linguistiques BERT personnalisés pour l'espagnol pour une variété de cas d'utilisation :
- Partie I : Comment former un modèle linguistique RoBERTa pour l'espagnol à partir de zéro
- Partie III : Comment former un modèle linguistique ELECTRA pour l'espagnol à partir de zéro
Dans mon précédent article de blog, nous avons expliqué comment mon équipe a pré-entraîné SpanBERTa, un modèle de langage transformateur pour l'espagnol, sur un grand corpus à partir de zéro. Le modèle s'est avéré capable de prédire correctement les mots masqués dans une séquence en fonction de son contexte. Dans cet article de blog, afin d'exploiter au mieux la puissance des modèles transformateurs, nous allons affiner SpanBERTa pour une tâche de reconnaissance d'entités nommées.
Selon sa définition sur Wikipedia (en anglais)La reconnaissance des entités nommées (NER) (également connue sous le nom d'identification d'entités, de regroupement d'entités et d'extraction d'entités) est une tâche secondaire de l'extraction d'informations qui vise à localiser et à classer les entités nommées mentionnées dans un texte non structuré dans des catégories prédéfinies telles que les noms de personnes, les organisations, les lieux, les codes médicaux, les expressions temporelles, les quantités, les valeurs monétaires, les pourcentages, etc.
Nous utiliserons le script run_ner.py par Hugging Face et Ensemble de données CoNLL-2002 pour affiner SpanBERTa.
Mise en place
Télécharger transformateurs et installer les paquets nécessaires.
%%capture
!git clone https://github.com/huggingface/transformers
%cd transformers
!pip install .
!pip install -r ./examples/requirements.txt
%cd ..
Données
1. Télécharger les ensembles de données
La commande ci-dessous télécharge et décompresse l'ensemble de données. Les fichiers contiennent les données d'entraînement et de test pour les trois parties de l'enquête. CoNLL-2002 tâche partagée :
- esp.testa : Données d'essai espagnoles pour la phase de développement
- esp.testb : données de test espagnoles
- esp.train : Données sur les trains espagnols
%pture
!wget -O 'conll2002.zip' 'https://drive.google.com/uc?export=download&id=1Wrl1b39ZXgKqCeAFNM9EoXtA1kzwNhCe'
!unzip 'conll2002.zip'
La taille de chaque ensemble de données :
!wc -l conll2002/esp.train
!wc -l conll2002/esp.testa
!wc -l conll2002/esp.testb
273038 conll2002/esp.train
54838 conll2002/esp.testa
53050 conll2002/esp.testb
Tous les fichiers de données comportent trois colonnes : les mots, les balises de parties du discours associées et les balises d'entités nommées dans le format IOB2. Les coupures de phrases sont codées par des lignes vides.
!head -n20 conll2002/esp.train
Melbourne NP B-LOC
( Fpa O
Australie NP B-LOC
) Fpt O
Fc O
25 Z O
peut NC O
( Fpa O
EFE NC B-ORG
) Fpt O
. Fp O
- Fg O
El DA O
Abogado NC B-PER
Général AQ I-PER
del SP I-PER
État NC I-PER
Fc O
Nous ne conserverons que la colonne des mots et la colonne des étiquettes des entités nommées pour nos ensembles de données de formation, de développement et de test.
!cat conll2002/esp.train | cut -d " " -f 1,3 > train_temp.txt
!cat conll2002/esp.testa | cut -d " " -f 1,3 > dev_temp.txt
!cat conll2002/esp.testb | cut -d " " -f 1,3 > test_temp.txt
2. Prétraitement
Définissons quelques variables dont nous avons besoin pour les étapes de prétraitement ultérieures et l'entraînement du modèle :
MAX_LENGTH = 120 #@param {type : "integer"}
MODEL = "chriskhanhtran/spanberta" #@param ["chriskhanhtran/spanberta", "bert-base-multilingual-cased"]
Le script ci-dessous scindera les phrases plus longues que MAX_LENGTH (en termes de jetons) en petites phrases. Dans le cas contraire, les phrases longues seront tronquées lors de la tokenisation, ce qui entraînera la perte de données d'apprentissage et l'impossibilité de prédire certains tokens dans l'ensemble de test.
%pture
!wget "https://raw.githubusercontent.com/stefan-it/fine-tuned-berts-seq/master/scripts/preprocess.py"
!python3 preprocess.py train_temp.txt $MODEL $MAX_LENGTH > train.txt
!python3 preprocess.py dev_temp.txt $MODEL $MAX_LENGTH > dev.txt
!python3 preprocess.py test_temp.txt $MODEL $MAX_LENGTH > test.txt
2020-04-22 23:02:05.747294 : I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1
Téléchargement : 100% 1.03k/1.03k [00:00<00:00, 704kB/s]
Téléchargement : 100% 954k/954k [00:00<00:00, 1.89MB/s]
Téléchargement : 100% 512k/512k [00:00<00:00, 1.19MB/s]
Téléchargement : 100% 16.0/16.0 [00:00<00:00, 12.6kB/s]
2020-04-22 23:02:23.409488: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1
2020-04-22 23:02:31.168967 : I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1
3. Étiquettes
Dans les ensembles de données CoNLL-2002/2003, il y a 9 classes d'étiquettes NER :
- O, En dehors d'une entité nommée
- B-MIS, Début d'une entité diverse juste après une autre entité diverse
- I-MIS, entités diverses
- B-PER, Début du nom d'une personne juste après le nom d'une autre personne
- I-PER, Nom de la personne
- B-ORG, début d'une organisation juste après une autre organisation
- I-ORG, Organisation
- B-LOC, début d'un lieu juste après un autre lieu
- I-LOC, Localisation
Si votre jeu de données a des étiquettes différentes ou plus d'étiquettes que les jeux de données CoNLL-2002/2003, exécutez la ligne ci-dessous pour obtenir des étiquettes uniques à partir de vos données et les enregistrer dans le fichier étiquettes.txt. Ce fichier sera utilisé lorsque nous commencerons à affiner notre modèle.
!cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
Modèle de réglage fin
Voici les scripts d'exemple de transformateursque nous utiliserons pour affiner notre modèle pour le NER. Après le 21/04/2020, Hugging Face a mis à jour ses scripts d'exemple pour utiliser un nouveau fichier Formateur classe. Pour éviter tout conflit futur, utilisons la version antérieure à ces mises à jour.
%pture
!wget "https://raw.githubusercontent.com/chriskhanhtran/spanish-bert/master/ner/run_ner.py"
!wget "https://raw.githubusercontent.com/chriskhanhtran/spanish-bert/master/ner/utils_ner.py"
Il est maintenant temps de passer à l'apprentissage par transfert. Dans mon article de blog précédentPour ce faire, j'ai pré-entraîné un modèle de langage RoBERTa sur un très grand corpus espagnol afin de prédire les mots masqués en fonction du contexte dans lequel ils se trouvent. Ce faisant, le modèle a appris des propriétés inhérentes à la langue. J'ai téléchargé le modèle pré-entraîné sur le serveur de Hugging Face. Nous allons maintenant charger le modèle et commencer à le peaufiner pour la tâche NER.
Les hyperparamètres d'apprentissage sont présentés ci-dessous.
MAX_LENGTH = 128 #@param {type : "integer"}
MODEL = "chriskhanhtran/spanberta" #@param ["chriskhanhtran/spanberta", "bert-base-multilingual-cased"]
OUTPUT_DIR = "spanberta-ner" #@param ["spanberta-ner", "bert-base-ml-ner"]
BATCH_SIZE = 32 #@param {type : "integer"}
NUM_EPOCHS = 3 #@param {type : "integer"}
SAVE_STEPS = 100 #@param {type : "integer"}
LOGGING_STEPS = 100 #@param {type : "integer"} #@param {type : "integer"}
SEED = 42 #@param {type : "integer" } SEED = 42 #@param {type : "integer"}
Commençons la formation.
!python3 run_ner.py
--data_dir ./
--model_type bert
--labels ./labels.txt
--model_name_or_path $MODEL
--output_dir $OUTPUT_DIR
--max_seq_length $MAX_LENGTH
--num_train_epochs $NUM_EPOCHS
--per_gpu_train_batch_size $BATCH_SIZE
--save_steps $SAVE_STEPS
--logging_steps $LOGGING_STEPS
--seed $SEED
--do_train
--do_eval
--do_predict
--overwrite_output_dir
Performance sur le plateau de développement :
04/21/2020 02:24:31 - INFO - __main__ - ***** Résultats de l'évaluation *****
21/04/2020 02:24:31 - INFO - __main__ - f1 = 0.831027443864822
21/04/2020 02:24:31 - INFO - __main__ - perte = 0.1004064822183894
04/21/2020 02:24:31 - INFO - __main__ - precision = 0.8207885304659498
04/21/2020 02:24:31 - INFO - __main__ - recall = 0.8415250344510795
Performance sur l'ensemble de tests :
04/21/2020 02:24:48 - INFO - __main__ - ***** Résultats de l'évaluation *****
21/04/2020 02:24:48 - INFO - __main__ - f1 = 0.8559533721898419
21/04/2020 02:24:48 - INFO - __main__ - perte = 0.06848683688204177
04/21/2020 02:24:48 - INFO - __main__ - precision = 0.845858475041141
04/21/2020 02:24:48 - INFO - __main__ - recall = 0.8662921348314607
Voici les tableaux tensoriels du réglage fin spanberta et bert-base-multilingue-casé pour 5 épisodes. On constate que les modèles surajoutent les données d'apprentissage après 3 époques.
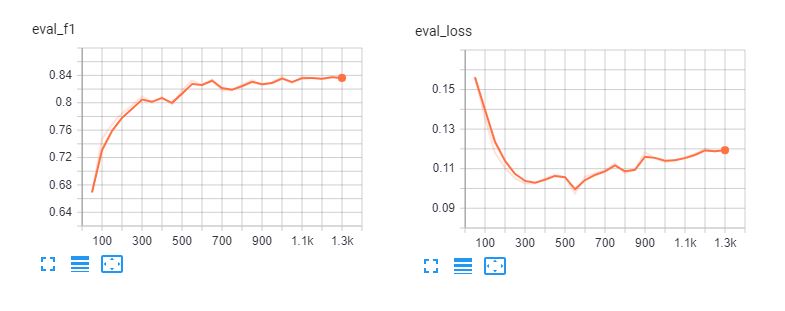
Rapport de classification
Pour comprendre les performances réelles de notre modèle, chargeons ses prédictions et examinons le rapport de classification.
def read_examples_from_file(file_path) :
"""Lire les mots et les étiquettes d'un fichier de données CoNLL-2002/2003.
Args :
file_path (str) : chemin vers le fichier de données NER.
Retourne :
exemples (dict) : un dictionnaire avec deux clés : mots (liste de listes)
en retenant les mots de chaque séquence, et étiquettes (liste de listes) contenant
des étiquettes correspondantes.
"""
avec open(file_path, encoding="utf-8") as f :
exemples = {"mots" : [], "étiquettes" : []}
mots = []
étiquettes = []
pour ligne dans f :
if line.startswith("-DOCSTART-") or line == "" or line == "\n" :
si mots :
exemples["mots"].append(mots)
exemples["étiquettes"].append(étiquettes)
mots = []
étiquettes = []
else :
splits = line.split(" ")
words.append(splits[0])
if len(splits) > 1 :
labels.append(splits[-1].replace("\n", ""))
else :
# Les exemples ne peuvent pas avoir d'étiquette pour le mode = "test"
labels.append("O")
Retourner les exemples
Lire les données et les étiquettes des fichiers texte bruts :
y_true = read_examples_from_file("test.txt")["labels"]
y_pred = read_examples_from_file("spanberta-ner/test_predictions.txt")["labels"]
Imprimer le rapport de classification :
from seqeval.metrics import classification_report as classification_report_seqeval
print(classification_report_seqeval(y_true, y_pred))
précision rappel f1-score soutien
LOC 0,87 0,84 0,85 1084
ORG 0.82 0.87 0.85 1401
DIVERS 0.63 0.66 0.65 340
PAR 0,94 0,96 0,95 735
micro avg 0,84 0,86 0,85 3560
macro avg 0,84 0,86 0,85 3560
Les mesures que nous voyons dans ce rapport sont conçues spécifiquement pour les tâches de NLP telles que le NER et l'étiquetage POS, dans lesquelles tous les mots d'une entité doivent être prédits correctement pour être comptés comme une prédiction correcte. Par conséquent, les mesures de ce rapport de classification sont beaucoup plus basses que celles des rapports de l Rapport de classification de scikit-learn.
import numpy as np
from sklearn.metrics import classification_report
print(rapport_classification(np.concatenate(y_true), np.concatenate(y_pred)))
précision rappel f1-score soutien
B-LOC 0,88 0,85 0,86 1084
B-MISC 0,73 0,73 0,73 339
B-ORG 0.87 0.91 0.89 1400
B-PER 0,95 0,96 0,95 735
I-LOC 0,82 0,81 0,81 325
I-MISC 0,85 0,76 0,80 557
I-ORG 0.89 0.87 0.88 1104
I-PER 0,98 0,98 0,98 634
O 1.00 1.00 1.00 45355
précision 0,98 51533
moyenne macro 0,89 0,87 0,88 51533
moyenne pondérée 0,98 0,98 0,98 51533
D'après les rapports ci-dessus, notre modèle a de bonnes performances pour prédire la personne, le lieu et l'organisation. Nous aurons besoin de plus de données pour DIVERS afin d'améliorer les performances de notre modèle sur ces entités.
Pipeline
Après avoir peaufiné nos modèles, nous pouvons les partager avec la communauté en suivant le tutoriel de cette page. page. Nous pouvons maintenant commencer à charger le modèle affiné à partir du serveur de Hugging Face et l'utiliser pour prédire les entités nommées dans les documents espagnols.
from transformers import pipeline, AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("skimai/spanberta-base-cased-ner-conll02")
tokenizer = AutoTokenizer.from_pretrained("skimai/spanberta-base-cased-ner-conll02")
ner_model = pipeline('ner', model=model, tokenizer=tokenizer)
L'exemple ci-dessous est tiré de La Opinión et signifie "La reprise économique des États-Unis après la pandémie de coronavirus sera une question de mois, a déclaré le secrétaire au Trésor Steven Mnuchin."
sequence = "La recuperación económica de los Estados Unidos después de la " \Npandia del coronavirus será cuestión de meses
"pandemia del coronavirus será cuestión de meses, afirmó el " \N- "Secretario del Tesoro, Steven Mnuchin.
"Secretario del Tesoro, Steven Mnuchin."
ner_model(sequence)
[{'entity' : 'B-ORG', 'score' : 0.9155661463737488, 'mot' : 'ĠEstados'},
{'entité' : 'I-ORG', 'score' : 0.800682544708252, 'mot' : 'ĠUnidos'},
{'entité' : 'I-MISC', 'score' : 0.5006815791130066, 'word' : 'Ġcorona'},
{'entité' : 'I-MISC', 'score' : 0.510674774646759, 'word' : 'virus'},
{'entité' : 'B-PER', 'score' : 0.5558510422706604, 'word' : 'ĠSecretario'},
{'entité' : 'I-PER', 'score' : 0.7758238315582275, 'word' : 'Ġdel'},
{'entité' : 'I-PER', 'score' : 0.7096233367919922, 'word' : 'ĠTesoro'},
{'entité' : 'B-PER', 'score' : 0.9940345883369446, 'mot' : 'ĠSteven'},
{'entité' : 'I-PER', 'score' : 0.9962581992149353, 'word' : 'ĠM'},
{'entité' : 'I-PER', 'score' : 0.9918380379676819, 'word' : 'n'},
{'entité' : 'I-PER', 'score' : 0.9848328828811646, 'word' : 'uch'},
{'entité' : 'I-PER', 'score' : 0.8513168096542358, 'word' : 'in'}]
C'est parfait ! Le modèle affiné reconnaît avec succès toutes les entités de notre exemple, et même le "corona virus".
Conclusion
La reconnaissance des entités nommées peut nous aider à extraire rapidement les informations importantes des textes. Par conséquent, son application dans le monde des affaires peut avoir un impact direct sur l'amélioration de la productivité humaine dans la lecture des contrats et des documents. Cependant, il s'agit d'une tâche NLP difficile car la reconnaissance des entités nommées nécessite une classification précise au niveau des mots, ce qui rend les approches simples telles que les sacs de mots impossibles à traiter.
Nous avons expliqué comment tirer parti d'un modèle BERT pré-entraîné pour obtenir rapidement d'excellentes performances dans la tâche NER pour l'espagnol. Le modèle SpanBERTa pré-entraîné peut également être affiné pour d'autres tâches telles que la classification de documents. J'ai écrit un tutoriel détaillé pour affiner le BERT pour la classification de séquences et l'analyse de sentiments.
Dans la prochaine partie de cette série, la partie 3, nous verrons comment utiliser ELECTRA, une approche de pré-entraînement plus efficace pour les modèles de transformateurs, qui permet d'atteindre rapidement des performances de pointe. Restez à l'écoute !


