
Tutoriel : Comment pré-entraîner ELECTRA à l'espagnol à partir de zéro



Tutoriel : Comment pré-entraîner ELECTRA à l'espagnol à partir de zéro
Publié à l'origine par Chris Tran, chercheur en apprentissage automatique chez Skim AI.![]()
Introduction
Cet article explique comment pré-entraîner ELECTRA, un autre membre de la famille des méthodes de pré-entraînement Transformer, pour l'espagnol afin d'obtenir des résultats de pointe dans les benchmarks de traitement du langage naturel. Il s'agit de la troisième partie d'une série sur l'entraînement des modèles linguistiques personnalisés de BERT pour l'espagnol pour une variété de cas d'utilisation :
- Partie I : Comment former un modèle linguistique RoBERTa pour l'espagnol à partir de zéro
- Partie II : Comment former un modèle de langue espagnole SpanBERTa pour la reconnaissance d'entités nommées (NER)
1. Introduction
À l'occasion de l'ICLR 2020, ELECTRA : Pré-entraînement d'encodeurs de texte en tant que discriminateurs plutôt que générateursELECTRA, une nouvelle méthode d'apprentissage auto-supervisé de la représentation du langage, a été présentée. ELECTRA est un autre membre de la famille des méthodes de pré-entraînement Transformer, dont les membres précédents tels que BERT, GPT-2, RoBERTa ont obtenu de nombreux résultats de pointe dans les tests de référence du traitement du langage naturel.
Contrairement à d'autres méthodes de modélisation du langage masqué, ELECTRA est une tâche de pré-entraînement plus efficace en termes d'échantillons, appelée détection de jetons remplacés. À petite échelle, ELECTRA-small peut être entraîné sur un seul GPU pendant 4 jours pour surpasser les performances d'ELECTRA-small. GPT (Radford et al., 2018) (formé en utilisant 30x plus de calcul) sur le benchmark GLUE. À grande échelle, ELECTRA-large surpasse les performances de ALBERT (Lan et al., 2019) sur GLUE et établit un nouvel état de l'art pour SQuAD 2.0.

ELECTRA surpasse systématiquement les approches de pré-entraînement de modèles de langage masqués.
{ : .text-center}
2. La méthode
Méthodes de pré-entraînement de la modélisation du langage masqué telles que BERT (Devlin et al., 2019) corrompre l'entrée en remplaçant certains tokens (typiquement 15% de l'entrée) par [MASQUE] puis former un modèle pour reconstruire les jetons originaux.
Au lieu de masquer, ELECTRA corrompt l'entrée en remplaçant certains tokens par des échantillons des sorties d'un modèle de langage masqué réduit. Ensuite, un modèle discriminant est entraîné pour prédire si chaque jeton est un original ou un remplacement. Après le pré-entraînement, le générateur est rejeté et le discriminateur est affiné sur des tâches en aval.
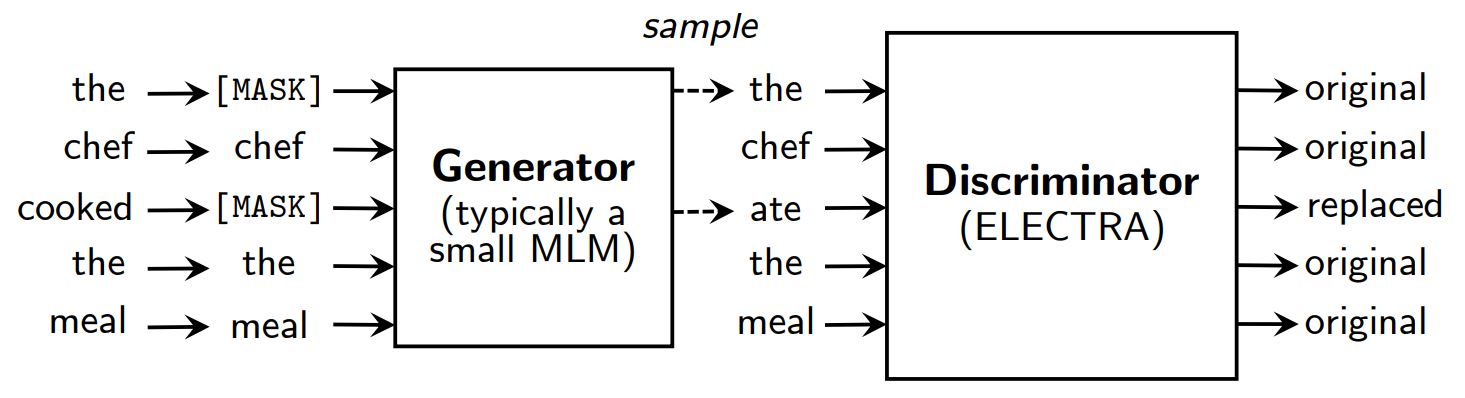
Une vue d'ensemble d'ELECTRA.
{ : .text-center}
Bien que disposant d'un générateur et d'un discriminateur comme le GAN, ELECTRA n'est pas antagoniste dans la mesure où le générateur produisant des jetons corrompus est entraîné avec le maximum de vraisemblance plutôt que d'être entraîné pour tromper le discriminateur.
Pourquoi ELECTRA est-il si efficace ?
Avec un nouvel objectif de formation, ELECTRA peut atteindre des performances comparables à celles de modèles puissants tels que RoBERTa (Liu et al., (2019) qui a plus de paramètres et nécessite 4x plus de calcul pour la formation. Dans ce document, une analyse a été menée pour comprendre ce qui contribue réellement à l'efficacité d'ELECTRA. Les principales conclusions sont les suivantes :
- ELECTRA bénéficie grandement de l'existence d'une perte définie sur tous les tokens de l'entrée plutôt que sur un sous-ensemble seulement. Plus précisément, dans ELECTRA, le discriminateur prédit sur chaque token de l'entrée, alors que dans BERT, le générateur ne prédit que 15% tokens masqués de l'entrée.
- Les performances de l'ORET sont légèrement affectées car, dans la phase de pré-entraînement, le modèle voit les éléments suivants
[MASQUE]alors que ce n'est pas le cas dans la phase de réglage fin.
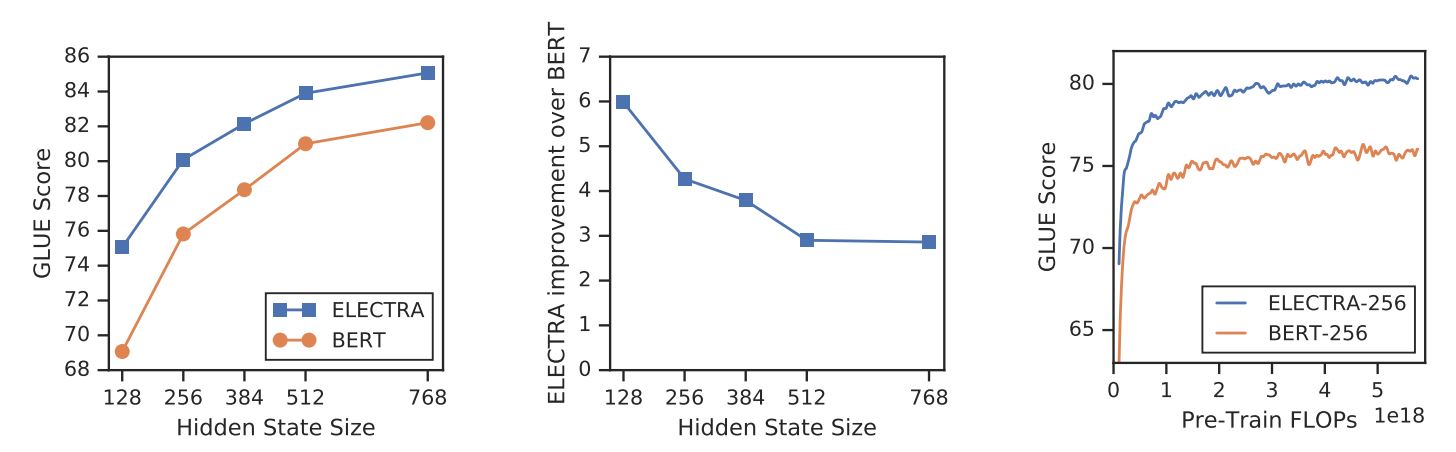
ELECTRA vs. BERT
{ : .text-center}
3. Pré-entraînement d'ELECTRA
Dans cette section, nous allons entraîner ELECTRA à partir de zéro avec TensorFlow en utilisant des scripts fournis par les auteurs d'ELECTRA dans le document google-research/electra. Nous convertirons ensuite le modèle en point de contrôle PyTorch, qui peut être facilement affiné sur les tâches en aval à l'aide de la fonction Hugging Face. transformateurs bibliothèque.
Mise en place
!pip install tensorflow==1.15
!pip install transformers==2.8.0
!git clone https://github.com/google-research/electra.git
import os
import json
from transformers import AutoTokenizer
Données
Nous allons pré-entraîner ELECTRA sur un ensemble de données de sous-titres de films espagnols récupérés sur OpenSubtitles. Cet ensemble de données a une taille de 5,4 Go et nous l'entraînerons sur un petit sous-ensemble de ~30 Mo pour la présentation.
DATA_DIR = "./data" #@param {type : "string"}
TRAIN_SIZE = 1000000 #@param {type : "integer" }
MODEL_NAME = "electra-spanish" #@param {type : "string"}
# Télécharger et décompresser l'ensemble de données sur les substituts de films espagnols
if not os.path.exists(DATA_DIR) :
!mkdir -p $DATA_DIR
!wget "https://object.pouta.csc.fi/OPUS-OpenSubtitles/v2016/mono/es.txt.gz" -O $DATA_DIR/OpenSubtitles.txt.gz
!gzip -d $DATA_DIR/OpenSubtitles.txt.gz
!head -n $TRAIN_SIZE $DATA_DIR/OpenSubtitles.txt > $DATA_DIR/train_data.txt
!rm $DATA_DIR/OpenSubtitles.txt
Avant de construire l'ensemble de données de pré-entraînement, nous devons nous assurer que le corpus a le format suivant :
- chaque ligne est une phrase
- une ligne blanche sépare deux documents
Création d'un ensemble de données de pré-entraînement
Nous utiliserons le tokenizer de bert-base-multilingue-casé pour traiter des textes en espagnol.
# Sauvegarder le tokenizer WordPiece pré-entraîné pour obtenir vocab.txt
tokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
tokenizer.save_pretrained(DATA_DIR)
Nous utilisons build_pretraining_dataset.py pour créer un ensemble de données de pré-entraînement à partir d'un texte brut.
!python3 electra/build_pretraining_dataset.py \N- --corpus-dir $DATA_DIR
--corpus-dir $DATA_DIR \N- --vocab-file $DATA_DIR/vocab.txt
--vocab-file $DATA_DIR/vocab.txt \N--Corpus-dir $DATA_DIR
--output-dir $DATA_DIR/pretrain_tfrecords \N--max-seq-length 128
--max-seq-length 128 \N--max-seq-length 128 \N--max-seq-length 128
--blanks-separate-docs False \N- --no-lower-case \N--max-seq-length 128
--no-lower-case \N --num-processus 5
--num-processes 5
Commencer la formation
Nous utilisons run_pretraining.py pour pré-entraîner un modèle ELECTRA.
Pour entraîner un petit modèle ELECTRA pour 1 million de pas, exécuter :
python3 run_pretraining.py --data-dir $DATA_DIR --model-name electra_small
Cela prend un peu plus de 4 jours sur un GPU Tesla V100. Cependant, le modèle devrait obtenir des résultats décents après 200k étapes (10 heures d'entraînement sur le GPU v100).
Pour personnaliser la formation, créez un .json contenant les hyperparamètres. Veuillez vous référer à configure_pretraining.py pour les valeurs par défaut de tous les hyperparamètres.
Ci-dessous, nous définissons les hyperparamètres afin d'entraîner le modèle pour seulement 100 étapes.
hparams = {
"do_train" : "true",
"do_eval" : "false",
"model_size" : "small",
"do_lower_case" : "false",
"vocab_size" : 119547,
"num_train_steps" : 100,
"save_checkpoints_steps" : 100,
"train_batch_size" : 32,
}
avec open("hparams.json", "w") as f :
json.dump(hparams, f)
Commençons la formation :
!python3 electra/run_pretraining.py \N- --data-dir $DATA_DIR
--data-dir $DATA_DIR \N- --model-name $MODEL_NAME
--model-name $MODEL_NAME \N- --hparams "hparams.json" \N- --hparams.json
--hparams "hparams.json"
Si vous vous entraînez sur une machine virtuelle, exécutez les lignes suivantes dans le terminal pour surveiller le processus d'entraînement avec TensorBoard.
pip install -U tensorboard
tensorboard dev upload --logdir data/models/electra-spanish
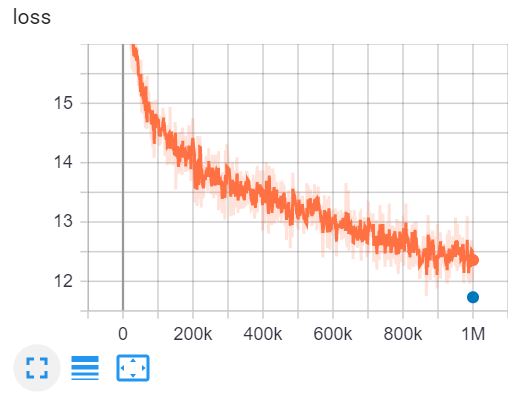
Il s'agit de la TensorBoard d'entraînement d'ELECTRA-small pour 1 million de pas en 4 jours sur un GPU V100.
 { : .align-center}
{ : .align-center}
4. Convertir les points de contrôle Tensorflow au format PyTorch
Le visage de l'étreinte a un outil pour convertir les points de contrôle de Tensorflow en PyTorch. Cependant, cet outil n'a pas encore été mis à jour pour ELECTRA. Heureusement, j'ai trouvé un repo GitHub par @lonePatient qui peut nous aider dans cette tâche.
!git clone https://github.com/lonePatient/electra_pytorch.git
MODEL_DIR = "data/models/electra-spanish/"
config = {
"vocab_size" : 119547,
"embedding_size" : 128,
"hidden_size" : 256,
"num_hidden_layers" : 12,
"num_attention_heads" : 4,
"taille_intermédiaire" : 1024,
"generator_size":"0.25",
"hidden_act" : "gelu",
"hidden_dropout_prob" : 0.1,
"attention_probs_dropout_prob" : 0.1,
"max_position_embeddings" : 512,
"type_vocab_size" : 2,
"initializer_range" : 0.02
}
with open(MODEL_DIR + "config.json", "w") as f :
json.dump(config, f)
!python electra_pytorch/convert_electra_tf_checkpoint_to_pytorch.py \N- --tf_checkpoint_path=$MODEL_DIR
--tf_checkpoint_path=$MODEL_DIR \N- --electra_config_file=$MODEL_DIR
--electra_config_file=$MODEL_DIR/config.json \N- --pytorch_dump_pytorch_f_checkpoint_to_pytorch py
--pytorch_dump_path=$MODEL_DIR/pytorch_model.bin
Utiliser ELECTRA avec transformateurs
Après avoir converti le point de contrôle du modèle au format PyTorch, nous pouvons commencer à utiliser notre modèle ELECTRA pré-entraîné sur des tâches en aval avec la commande transformateurs bibliothèque.
import torch
from transformers import ElectraForPreTraining, ElectraTokenizerFast
discriminateur = ElectraForPreTraining.from_pretrained(MODEL_DIR)
tokenizer = ElectraTokenizerFast.from_pretrained(DATA_DIR, do_lower_case=False)
sentence = "Los pájaros están cantando" # Les oiseaux chantent
fake_sentence = "Los pájaros están hablando" # Les oiseaux parlent
fake_tokens = tokenizer.tokenize(fake_sentence, add_special_tokens=True)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
discriminator_outputs = discriminateur(fake_inputs)
predictions = discriminator_outputs[0] > 0
[print("%7s" % token, end="") for token in fake_tokens]
print("\n")
[print("%7s" % int(prediction), end="") for prediction in predictions.tolist()] ;
[CLS] Los paj ##aros estan habla ##ndo [SEP]
1 0 0 0 0 0 0 0
Notre modèle n'a été entraîné que pour 100 étapes, les prédictions ne sont donc pas précises. Le modèle ELECTRA-small pour l'espagnol, entièrement entraîné, peut être chargé comme suit :
discriminateur = ElectraForPreTraining.from_pretrained("skimai/electra-small-spanish")
tokenizer = ElectraTokenizerFast.from_pretrained("skimai/electra-small-spanish", do_lower_case=False)
5. Conclusion
Dans cet article, nous avons parcouru le document ELECTRA pour comprendre pourquoi ELECTRA est l'approche de pré-entraînement des transformateurs la plus efficace à l'heure actuelle. À petite échelle, ELECTRA-small peut être entraîné sur un GPU pendant 4 jours pour surpasser GPT sur le benchmark GLUE. À grande échelle, ELECTRA-large établit un nouvel état de l'art pour SQuAD 2.0.
Nous entraînons ensuite un modèle ELECTRA sur des textes espagnols, puis nous convertissons le point de contrôle Tensorflow en PyTorch et nous utilisons le modèle avec l'application transformateurs bibliothèque.
Références
- [1] ELECTRA : Pré-entraînement d'encodeurs de texte en tant que discriminateurs plutôt que générateurs
- [2] google-research/electra - le dépôt officiel GitHub de l'article original
- [3] electra_pytorch - une implémentation PyTorch d'ELECTRA


