
Tutorial: How to pre-train ELECTRA for Spanish from Scratch



Tutorial: How to pre-train ELECTRA for Spanish from Scratch
Originally published by Skim AI's Machine Learning Researcher, Chris Tran.![]()
Introduction
This article is on how pre-train ELECTRA, another member of the Transformer pre-training method family, for Spanish to achieve state-of-the-art results in Natural Language Processing benchmarks. It is Part III in a series on training custom BERT Language Models for Spanish for a variety of use cases:
- Part I: How to Train a RoBERTa Language Model for Spanish from Scratch
- Part II: How to Train a SpanBERTa Spanish Language Model for Named Entity Recognition (NER)
1. Introduction
At ICLR 2020, ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators, a new method for self-supervised language representation learning, was introduced. ELECTRA is another member of the Transformer pre-training method family, whose previous members such as BERT, GPT-2, RoBERTa have achieved many state-of-the-art results in Natural Language Processing benchmarks.
Different from other masked language modeling methods, ELECTRA is a more sample-efficient pre-training task called replaced token detection. At a small scale, ELECTRA-small can be trained on a single GPU for 4 days to outperform GPT (Radford et al., 2018) (trained using 30x more compute) on the GLUE benchmark. At a large scale, ELECTRA-large outperforms ALBERT (Lan et al., 2019) on GLUE and sets a new state-of-the-art for SQuAD 2.0.

ELECTRA consistently outperforms masked language model pre-training approaches.
{: .text-center}
2. Method
Masked language modeling pre-training methods such as BERT (Devlin et al., 2019) corrupt the input by replacing some tokens (typically 15% of the input) with [MASK] and then train a model to re-construct the original tokens.
Instead of masking, ELECTRA corrupts the input by replacing some tokens with samples from the outputs of a smalled masked language model. Then, a discriminative model is trained to predict whether each token was an original or a replacement. After pre-training, the generator is thrown out and the discriminator is fine-tuned on downstream tasks.
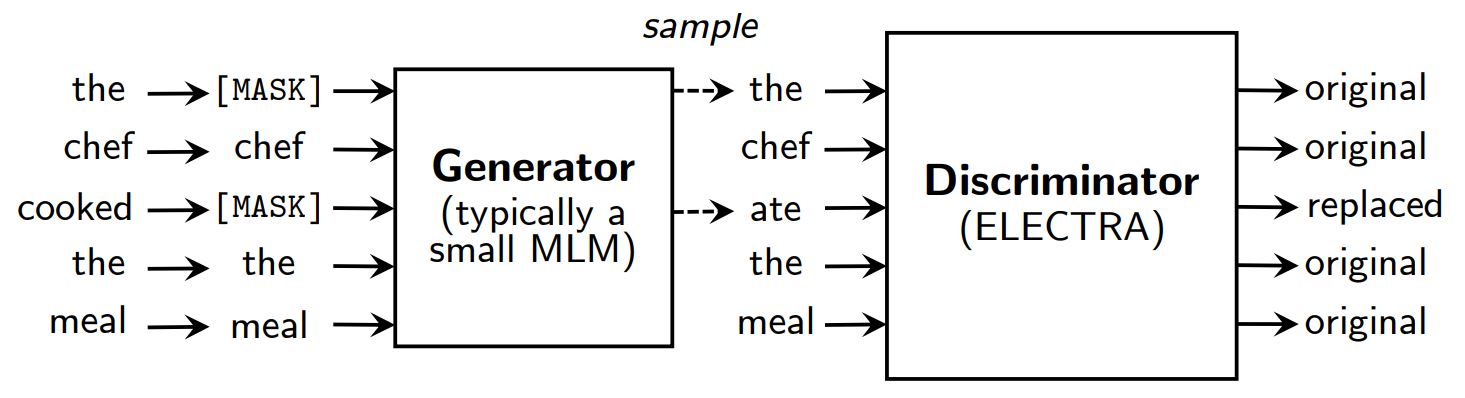
An overview of ELECTRA.
{: .text-center}
Although having a generator and a discriminator like GAN, ELECTRA is not adversarial in that the generator producing corrupted tokens is trained with maximum likelihood rather than being trained to fool the discriminator.
Why is ELECTRA so efficient?
With a new training objective, ELECTRA can achieve comparable performance to strong models such as RoBERTa (Liu et al., (2019) which has more parameters and needs 4x more compute for training. In the paper, an analysis was conducted to understand what really contribute to ELECTRA’s efficiency. The key findings are:
- ELECTRA is greatly benefiting from having a loss defined over all input tokens rather than just a subset. More specifically, in ELECTRA, the discriminator predicts on every token in the input, while in BERT, the generator only predicts 15% masked tokens of the input.
- BERT’s performance is slightly harmed because in the pre-training phase, the model sees
[MASK]tokens, while it is not the case in the fine-tuning phase.
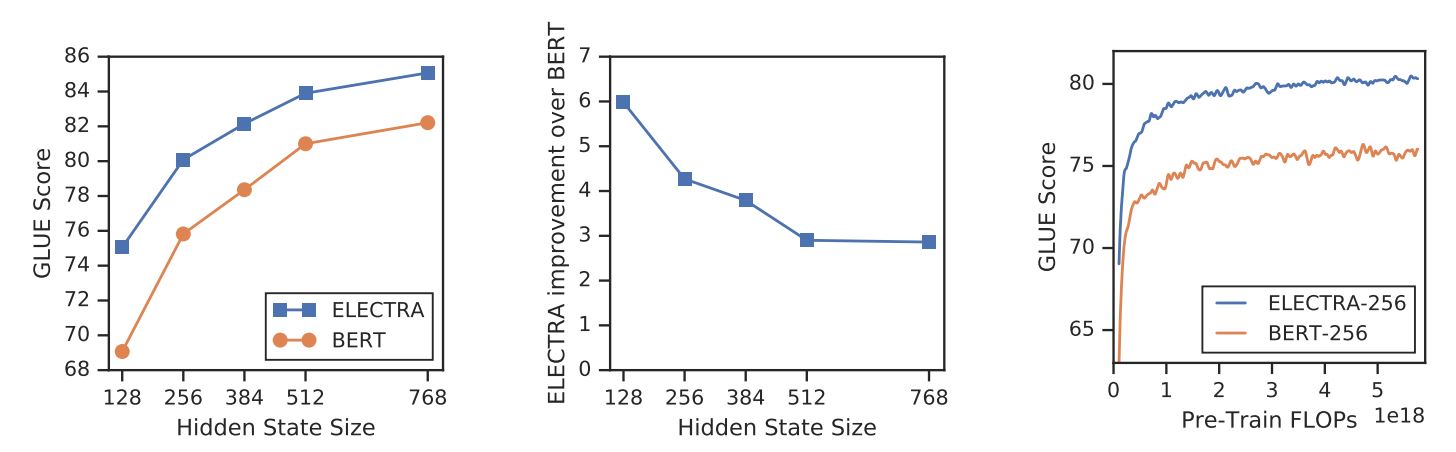
ELECTRA vs. BERT
{: .text-center}
3. Pre-train ELECTRA
In this section, we will train ELECTRA from scratch with TensorFlow using scripts provided by ELECTRA’s authors in google-research/electra. Then we will convert the model to PyTorch’s checkpoint, which can be easily fine-tuned on downstream tasks using Hugging Face’s transformers library.
Setup
!pip install tensorflow==1.15
!pip install transformers==2.8.0
!git clone https://github.com/google-research/electra.git
import os
import json
from transformers import AutoTokenizer
Data
We will pre-train ELECTRA on a Spanish movie subtitle dataset retrieved from OpenSubtitles. This dataset is 5.4 GB in size and we will train on a small subset of ~30 MB for presentation.
DATA_DIR = "./data" #@param {type: "string"}
TRAIN_SIZE = 1000000 #@param {type:"integer"}
MODEL_NAME = "electra-spanish" #@param {type: "string"}
# Download and unzip the Spanish movie substitle dataset
if not os.path.exists(DATA_DIR):
!mkdir -p $DATA_DIR
!wget "https://object.pouta.csc.fi/OPUS-OpenSubtitles/v2016/mono/es.txt.gz" -O $DATA_DIR/OpenSubtitles.txt.gz
!gzip -d $DATA_DIR/OpenSubtitles.txt.gz
!head -n $TRAIN_SIZE $DATA_DIR/OpenSubtitles.txt > $DATA_DIR/train_data.txt
!rm $DATA_DIR/OpenSubtitles.txt
Before building the pre-training dataset, we should make sure the corpus has the following format:
- each line is a sentence
- a blank line separates two documents
Build Pretraining Dataset
We will use the tokenizer of bert-base-multilingual-cased to process Spanish texts.
# Save the pretrained WordPiece tokenizer to get vocab.txt
tokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
tokenizer.save_pretrained(DATA_DIR)
We use build_pretraining_dataset.py to create a pre-training dataset from a dump of raw text.
!python3 electra/build_pretraining_dataset.py
--corpus-dir $DATA_DIR
--vocab-file $DATA_DIR/vocab.txt
--output-dir $DATA_DIR/pretrain_tfrecords
--max-seq-length 128
--blanks-separate-docs False
--no-lower-case
--num-processes 5
Start Training
We use run_pretraining.py to pre-train an ELECTRA model.
To train a small ELECTRA model for 1 million steps, run:
python3 run_pretraining.py --data-dir $DATA_DIR --model-name electra_small
This takes slightly over 4 days on a Tesla V100 GPU. However, the model should achieve decent results after 200k steps (10 hours of training on the v100 GPU).
To customize the training, create a .json file containing the hyperparameters. Please refer configure_pretraining.py for default values of all hyperparameters.
Below, we set the hyperparameters to train the model for only 100 steps.
hparams = {
"do_train": "true",
"do_eval": "false",
"model_size": "small",
"do_lower_case": "false",
"vocab_size": 119547,
"num_train_steps": 100,
"save_checkpoints_steps": 100,
"train_batch_size": 32,
}
with open("hparams.json", "w") as f:
json.dump(hparams, f)
Let’s start training:
!python3 electra/run_pretraining.py
--data-dir $DATA_DIR
--model-name $MODEL_NAME
--hparams "hparams.json"
If you are training on a virtual machine, run the following lines on the terminal to moniter the training process with TensorBoard.
pip install -U tensorboard
tensorboard dev upload --logdir data/models/electra-spanish
This is the TensorBoard of training ELECTRA-small for 1 million steps in 4 days on a V100 GPU.
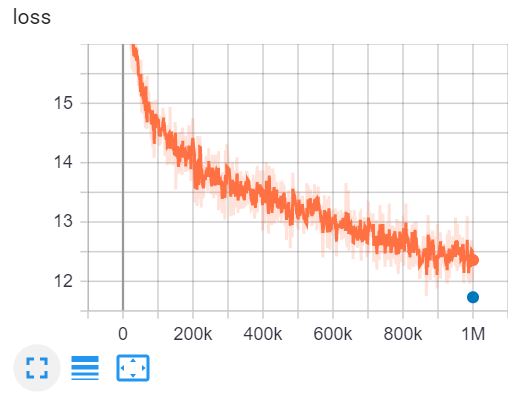 {: .align-center}
{: .align-center}
4. Convert Tensorflow checkpoints to PyTorch format
Hugging Face has a tool to convert Tensorflow checkpoints to PyTorch. However, this tool has yet been updated for ELECTRA. Fortunately, I found a GitHub repo by @lonePatient that can help us with this task.
!git clone https://github.com/lonePatient/electra_pytorch.git
MODEL_DIR = "data/models/electra-spanish/"
config = {
"vocab_size": 119547,
"embedding_size": 128,
"hidden_size": 256,
"num_hidden_layers": 12,
"num_attention_heads": 4,
"intermediate_size": 1024,
"generator_size":"0.25",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"attention_probs_dropout_prob": 0.1,
"max_position_embeddings": 512,
"type_vocab_size": 2,
"initializer_range": 0.02
}
with open(MODEL_DIR + "config.json", "w") as f:
json.dump(config, f)
!python electra_pytorch/convert_electra_tf_checkpoint_to_pytorch.py
--tf_checkpoint_path=$MODEL_DIR
--electra_config_file=$MODEL_DIR/config.json
--pytorch_dump_path=$MODEL_DIR/pytorch_model.bin
Use ELECTRA with transformers
After converting the model checkpoint to PyTorch format, we can start to use our pre-trained ELECTRA model on downstream tasks with the transformers library.
import torch
from transformers import ElectraForPreTraining, ElectraTokenizerFast
discriminator = ElectraForPreTraining.from_pretrained(MODEL_DIR)
tokenizer = ElectraTokenizerFast.from_pretrained(DATA_DIR, do_lower_case=False)
sentence = "Los pájaros están cantando" # The birds are singing
fake_sentence = "Los pájaros están hablando" # The birds are speaking
fake_tokens = tokenizer.tokenize(fake_sentence, add_special_tokens=True)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
discriminator_outputs = discriminator(fake_inputs)
predictions = discriminator_outputs[0] > 0
[print("%7s" % token, end="") for token in fake_tokens]
print("n")
[print("%7s" % int(prediction), end="") for prediction in predictions.tolist()];
[CLS] Los paj ##aros estan habla ##ndo [SEP]
1 0 0 0 0 0 0 0
Our model was trained for only 100 steps so the predictions are not accurate. The fully-trained ELECTRA-small for Spanish can be loaded as below:
discriminator = ElectraForPreTraining.from_pretrained("skimai/electra-small-spanish")
tokenizer = ElectraTokenizerFast.from_pretrained("skimai/electra-small-spanish", do_lower_case=False)
5. Conclusion
In this article, we have walked through the ELECTRA paper to understand why ELECTRA is the most efficient transformer pre-training approach at the moment. At a small scale, ELECTRA-small can be trained on one GPU for 4 days to outperform GPT on the GLUE benchmark. At a large scale, ELECTRA-large sets a new state-of-the-art for SQuAD 2.0.
We then actually train an ELECTRA model on Spanish texts and convert Tensorflow checkpoint to PyTorch and use the model with the transformers library.
References
- [1] ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
- [2] google-research/electra – the official GitHub repository of the original paper
- [3] electra_pytorch – a PyTorch implementation of ELECTRA


