
Tutorial: Come preallenare ELECTRA per lo spagnolo partendo da zero



Tutorial: Come preallenare ELECTRA per lo spagnolo partendo da zero
Pubblicato originariamente dal ricercatore di apprendimento automatico di Skim AI, Chris Tran.![]()
Introduzione
Questo articolo spiega come pre-addestrare ELECTRA, un altro membro della famiglia di metodi di pre-addestramento Transformer, per lo spagnolo, per ottenere risultati all'avanguardia nei benchmark di elaborazione del linguaggio naturale. Si tratta della terza parte di una serie sull'addestramento di modelli linguistici BERT personalizzati per lo spagnolo per una serie di casi d'uso:
- Parte I: Come addestrare un modello linguistico RoBERTa per lo spagnolo partendo da zero
- Parte II: Come addestrare un modello linguistico spagnolo SpanBERTa per il riconoscimento di entità denominate (NER)
1. Introduzione
All'ICLR 2020, ELECTRA: preaddestramento dei codificatori di testo come discriminatori piuttosto che come generatoriè stato presentato un nuovo metodo per l'apprendimento auto-supervisionato della rappresentazione linguistica. ELECTRA è un altro membro della famiglia di metodi di pre-addestramento Transformer, i cui precedenti membri, come BERT, GPT-2 e RoBERTa, hanno ottenuto molti risultati all'avanguardia nei benchmark di elaborazione del linguaggio naturale.
A differenza di altri metodi di modellazione linguistica mascherata, ELECTRA è un'attività di pre-addestramento più efficiente in termini di campioni, chiamata rilevamento dei token sostituiti. Su scala ridotta, ELECTRA-small può essere addestrato su una singola GPU per 4 giorni, superando le prestazioni di ELECTRA-small. GPT (Radford et al., 2018) (addestrato utilizzando un numero di calcoli 30 volte superiore) sul benchmark GLUE. Su grande scala, ELECTRA-large supera ALBERT (Lan et al., 2019) su GLUE e stabilisce un nuovo stato dell'arte per SQuAD 2.0.

ELECTRA supera costantemente gli approcci di pre-addestramento dei modelli linguistici mascherati.
{\a6}(*) .text-center {\a6} (*)
2. Metodo
Metodi di pre-addestramento per la modellazione linguistica mascherata come BERT (Devlin et al., 2019) corrompere l'input sostituendo alcuni token (tipicamente 15% dell'input) con [MASCHERA] e poi addestrare un modello per ricostruire i token originali.
Invece di mascherare, ELECTRA corrompe l'input sostituendo alcuni token con campioni provenienti dalle uscite di un modello linguistico mascherato ridotto. Quindi, viene addestrato un modello discriminativo per prevedere se ogni token è originale o sostitutivo. Dopo il pre-addestramento, il generatore viene scartato e il discriminatore viene messo a punto su compiti a valle.
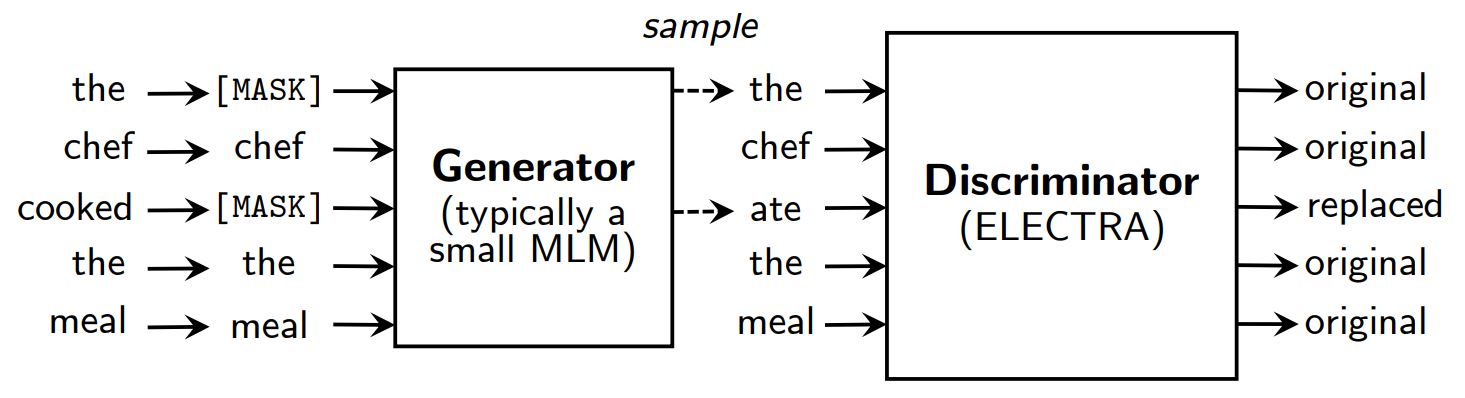
Una panoramica di ELECTRA.
{\a6}(*) .text-center {\a6} (*)
Pur avendo un generatore e un discriminatore come la GAN, ELECTRA non è avversaria in quanto il generatore che produce token corrotti è addestrato con la massima verosimiglianza piuttosto che essere addestrato per ingannare il discriminatore.
Perché ELECTRA è così efficiente?
Con un nuovo obiettivo di addestramento, ELECTRA può raggiungere prestazioni paragonabili a quelle di modelli forti come RoBERTa (Liu et al., (2019) che ha più parametri e necessita di 4 volte più calcolo per l'addestramento. Nel documento è stata condotta un'analisi per capire cosa contribuisce realmente all'efficienza di ELECTRA. I risultati principali sono:
- ELECTRA trae grande vantaggio dal fatto di avere una perdita definita su tutti i token in ingresso, anziché solo su un sottoinsieme. In particolare, in ELECTRA il discriminatore predice su tutti i token dell'input, mentre in BERT il generatore predice solo i 15% token mascherati dell'input.
- Le prestazioni di BERT sono leggermente penalizzate perché nella fase di pre-addestramento il modello vede
[MASCHERA]mentre non è così nella fase di messa a punto.
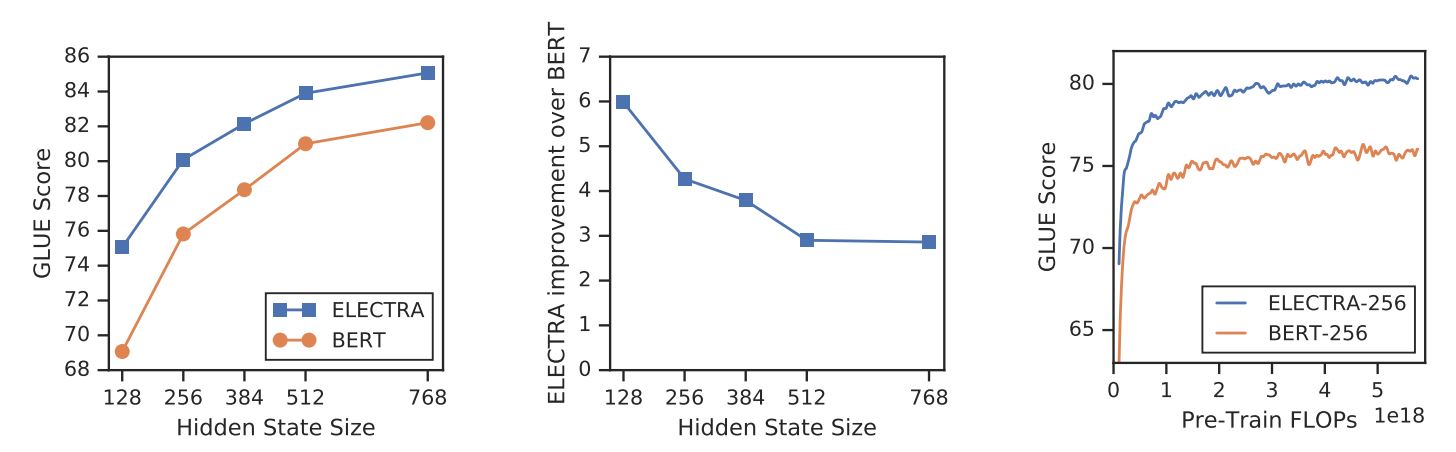
ELECTRA vs. BERT
{\a6}(*) .text-center {\a6} (*)
3. Pre-addestramento di ELECTRA
In questa sezione, addestreremo ELECTRA da zero con TensorFlow utilizzando gli script forniti dagli autori di ELECTRA in google-ricerca/electra. Poi convertiremo il modello in un checkpoint di PyTorch, che può essere facilmente messo a punto su task a valle utilizzando Hugging Face. trasformatori biblioteca.
Impostazione
pip installa tensorflow==1.15
!pip installa transformers==2.8.0
!git clone https://github.com/google-research/electra.git
importare os
importare json
da transformers import AutoTokenizer
Dati
Pre-alleneremo ELECTRA su un set di dati di sottotitoli di film spagnoli recuperati da OpenSubtitles. Questo dataset ha una dimensione di 5,4 GB e per la presentazione ci alleneremo su un piccolo sottoinsieme di ~30 MB.
DATA_DIR = "./data" #@param {type: "string"}
TRAIN_SIZE = 1000000 #@param {type: "integer"}
MODEL_NAME = "electra-spanish" #@param {type: "string"}
# Scaricare e decomprimere il dataset dei sottotitoli dei film spagnoli
se non os.path.exists(DATA_DIR):
!mkdir -p $DATA_DIR
!wget "https://object.pouta.csc.fi/OPUS-OpenSubtitles/v2016/mono/es.txt.gz" -O $DATA_DIR/OpenSubtitles.txt.gz
gzip -d $DATA_DIR/OpenSubtitles.txt.gz
!head -n $TRAIN_SIZE $DATA_DIR/OpenSubtitles.txt > $DATA_DIR/train_data.txt
rm $DATA_DIR/OpenSubtitles.txt
Prima di costruire il dataset di pre-addestramento, dobbiamo assicurarci che il corpus abbia il seguente formato:
- ogni riga è una frase
- una riga vuota separa due documenti
Creare un set di dati di pre-addestramento
Si utilizzerà il tokenizzatore di bert-base-multilingue-casuale per elaborare testi in spagnolo.
# Salvare il tokenizzatore WordPiece preaddestrato per ottenere vocab.txt
tokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
tokenizer.save_pretrained(DATA_DIR)
Utilizziamo build_pretraining_dataset.py per creare un set di dati di pre-addestramento da un dump di testo grezzo.
!python3 electra/build_pretraining_dataset.py \
--corpus-dir $DATA_DIR \
--file vocabolo $DATA_DIR/vocab.txt ´
--output-dir $DATA_DIR/pretrain_tfrecords \
--max-seq-length 128 \
--blanks-separate-docs False \
--no minuscole \
--num-processi 5
Avvio della formazione
Utilizziamo run_pretraining.py per preaddestrare un modello ELECTRA.
Per addestrare un piccolo modello ELECTRA per 1 milione di passi, eseguire:
python3 run_pretraining.py --data-dir $DATA_DIR --nome-modello electra_small
Questo richiede poco più di 4 giorni su una GPU Tesla V100. Tuttavia, il modello dovrebbe ottenere risultati decenti dopo 200k passi (10 ore di addestramento sulla GPU v100).
Per personalizzare la formazione, creare un file .json contenente gli iperparametri. Fare riferimento a configure_pretraining.py per i valori predefiniti di tutti gli iperparametri.
Di seguito, impostiamo gli iperparametri per addestrare il modello per soli 100 passi.
hparams = {
"do_train": "true",
"do_eval": "false",
"model_size": "small",
"do_lower_case": "false",
"vocab_size": 119547,
"num_train_steps": 100,
"save_checkpoints_steps": 100,
"train_batch_size": 32,
}
con open("hparams.json", "w") as f:
json.dump(hparams, f)
Iniziamo l'allenamento:
!python3 electra/run_pretraining.py \
--data-dir $DATA_DIR \
-nome del modello $MODEL_NAME \
--hparams "hparams.json"
Se si effettua l'addestramento su una macchina virtuale, eseguire le seguenti righe sul terminale per monitorare il processo di addestramento con TensorBoard.
pip installare -U tensorboard
tensorboard dev upload --logdir data/models/electra-spanish
Questo è il TensorBoard di addestramento di ELECTRA-small per 1 milione di passi in 4 giorni su una GPU V100.
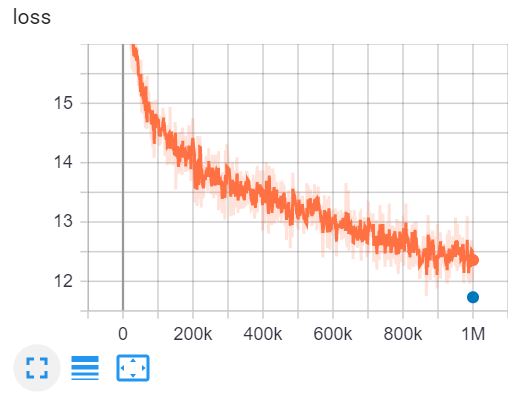 {\a6}(*)
{\a6}(*)
4. Convertire i checkpoint di Tensorflow in formato PyTorch
Il volto abbracciato ha uno strumento per convertire i checkpoint di Tensorflow in PyTorch. Tuttavia, questo strumento non è ancora stato aggiornato per ELECTRA. Fortunatamente, ho trovato un repo su GitHub di @lonePatient che può aiutarci in questo compito.
!git clone https://github.com/lonePatient/electra_pytorch.git
MODEL_DIR = "data/models/electra-spanish/"
config = {
"vocab_size": 119547,
"embedding_size": 128,
"hidden_size": 256,
"num_hidden_layers": 12,
"num_teste_attenzione": 4,
"dimensione_intermedia": 1024,
"generator_size":"0.25",
"atto_nascosto": "gelu",
"prob_dropout_nascosto": 0.1,
"attention_probs_dropout_prob": 0.1,
"max_position_embeddings": 512,
"dimensione_tipo_vocabolo": 2,
"intervallo_inizializzatore": 0.02
}
con open(MODEL_DIR + "config.json", "w") come f:
json.dump(config, f)
!python electra_pytorch/convert_electra_tf_checkpoint_to_pytorch.py \
--tf_checkpoint_path=$MODEL_DIR \
--electra_config_file=$MODEL_DIR/config.json \
--pytorch_dump_path=$MODEL_DIR/pytorch_model.bin
Utilizzare ELECTRA con trasformatori
Dopo aver convertito il checkpoint del modello in formato PyTorch, possiamo iniziare a utilizzare il nostro modello ELECTRA pre-addestrato su compiti a valle con l'opzione trasformatori biblioteca.
importare torcia
da transformers import ElectraForPreTraining, ElectraTokenizerFast
discriminatore = ElectraForPreTraining.from_pretrained(MODEL_DIR)
tokenizer = ElectraTokenizerFast.from_pretrained(DATA_DIR, do_lower_case=False)
sentence = "Los pájaros están cantando" # Gli uccelli stanno cantando
fake_sentence = "Los pájaros están hablando" # Gli uccelli stanno parlando
fake_tokens = tokenizer.tokenize(fake_sentence, add_special_tokens=True)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
discriminator_outputs = discriminator(fake_inputs)
previsioni = discriminator_outputs[0] > 0
[print("%7s" % token, end="") for token in fake_tokens]
print("\n")
[print("%7s" % int(prediction), end="") for prediction in predictions.tolist()];
[CLS] Los paj ##aros estan habla ##ndo [SEP]
1 0 0 0 0 0 0 0
Il nostro modello è stato addestrato per soli 100 passi, quindi le previsioni non sono accurate. Il modello ELECTRA-small completamente addestrato per lo spagnolo può essere caricato come segue:
discriminatore = ElectraForPreTraining.from_pretrained("skimai/electra-small-spanish")
tokenizer = ElectraTokenizerFast.from_pretrained("skimai/electra-small-spanish", do_lower_case=False)
5. Conclusione
In questo articolo abbiamo analizzato il documento di ELECTRA per capire perché ELECTRA è l'approccio di pre-addestramento dei trasformatori più efficiente al momento. Su piccola scala, ELECTRA-small può essere addestrato con una sola GPU per 4 giorni, superando GPT nel benchmark GLUE. Su larga scala, ELECTRA-large stabilisce un nuovo stato dell'arte per SQuAD 2.0.
Poi addestriamo un modello ELECTRA su testi spagnoli e convertiamo il checkpoint di Tensorflow in PyTorch e utilizziamo il modello con il programma trasformatori biblioteca.
Riferimenti
- [1] ELECTRA: preaddestramento dei codificatori di testo come discriminatori piuttosto che come generatori
- [2] google-ricerca/electra - il repository GitHub ufficiale del documento originale
- [3] electra_pytorch - un'implementazione PyTorch di ELECTRA


