
Tutorial: Cómo ajustar BERT para el reconocimiento de entidades con nombre (NER)



Tutorial: Cómo ajustar BERT para NER
Publicado originalmente por Chris Tran, investigador de aprendizaje automático de Skim AI.![]()
Introducción
Este artículo trata sobre cómo afinar BERT para el Reconocimiento de Entidades Nombradas (NER). Específicamente, cómo entrenar una variación de BERT, SpanBERTa, para NER. Es la Parte II de la III de una serie sobre el entrenamiento de modelos lingüísticos BERT personalizados para español para una variedad de casos de uso:
- Parte I: Cómo entrenar desde cero un modelo lingüístico RoBERTa para el español
- Parte III: Cómo entrenar desde cero un modelo lingüístico ELECTRA para el español
En mi anterior entrada del blog, hemos hablado de cómo mi equipo preentrenó SpanBERTa, un modelo de lenguaje transformador para el español, en un gran corpus desde cero. El modelo ha demostrado ser capaz de predecir correctamente palabras enmascaradas en una secuencia basándose en su contexto. En esta entrada del blog, para aprovechar realmente la potencia de los modelos transformadores, perfeccionaremos SpanBERTa para una tarea de reconocimiento de entidades con nombre.
Según su definición en WikipediaEl reconocimiento de entidades con nombre (NER, por sus siglas en inglés) (también conocido como identificación de entidades, agrupación de entidades y extracción de entidades) es una subtarea de la extracción de información que trata de localizar y clasificar las entidades con nombre mencionadas en un texto no estructurado en categorías predefinidas como nombres de personas, organizaciones, ubicaciones, códigos médicos, expresiones temporales, cantidades, valores monetarios, porcentajes, etc.
Utilizaremos el script run_ner.py de Hugging Face y Conjunto de datos CoNLL-2002 para afinar SpanBERTa.
Configurar
Descargar transformadores e instalar los paquetes necesarios.
%%capture
!git clone https://github.com/huggingface/transformers
%cd transformers
!pip install .
!pip install -r ./examples/requirements.txt
%cd ..
Datos
1. Descargar conjuntos de datos
El siguiente comando descargará y descomprimirá el conjunto de datos. Los archivos contienen los datos de entrenamiento y de prueba de tres partes del programa CoNLL-2002 tarea compartida:
- esp.testa: Datos de prueba españoles para la fase de desarrollo
- esp.testb: datos de prueba españoles
- esp.tren: Datos de trenes españoles
%ptura
!wget -O 'conll2002.zip' 'https://drive.google.com/uc?export=download&id=1Wrl1b39ZXgKqCeAFNM9EoXtA1kzwNhCe'
Descomprimir 'conll2002.zip
El tamaño de cada conjunto de datos:
wc -l conll2002/esp.tren
wc -l conll2002/esp.testa
wc -l conll2002/esp.testb
273038 conll2002/esp.tren
54838 conll2002/esp.testa
53050 conll2002/esp.testb
Todos los archivos de datos tienen tres columnas: palabras, etiquetas de parte de habla asociadas y etiquetas de entidad con nombre en el formato IOB2. Los cortes de frase se codifican mediante líneas vacías.
head -n20 conll2002/esp.train
Melbourne NP B-LOC
( Fpa O
Australia NP B-LOC
) Fpt O
, Fc O
25 Z O
puede NC O
( Fpa O
EFE NC B-ORG
) Fpt O
. Fp O
- Fg O
El DA O
Abogado NC B-PER
General AQ I-PER
del SP I-PER
Estado NC I-PER
, Fc O
Sólo conservaremos la columna de palabras y la columna de etiquetas de entidades con nombre para nuestros conjuntos de datos de entrenamiento, desarrollo y prueba.
!cat conll2002/esp.train | cut -d " " -f 1,3 > train_temp.txt
!cat conll2002/esp.testa | cut -d " " -f 1,3 > dev_temp.txt
!cat conll2002/esp.testb | cut -d " " -f 1,3 > test_temp.txt
2. Preprocesamiento
Vamos a definir algunas variables que necesitamos para los siguientes pasos de preprocesamiento y entrenamiento del modelo:
MAX_LENGTH = 120 #@param {type: "integer"}
MODEL = "chriskhanhtran/spanberta" #@param ["chriskhanhtran/spanberta", "bert-base-multilingual-cased"]
El siguiente script dividirá las frases más largas que LONGITUD MÁXIMA (en términos de tokens) en pequeñas. De lo contrario, las frases largas se truncarán al tokenizarlas, lo que provocará la pérdida de datos de entrenamiento y que algunos tokens del conjunto de prueba no se puedan predecir.
%ptura
wget "https://raw.githubusercontent.com/stefan-it/fine-tuned-berts-seq/master/scripts/preprocess.py"
!python3 preprocess.py train_temp.txt $MODEL $MAX_LENGTH > train.txt
!python3 preprocess.py dev_temp.txt $MODEL $MAX_LENGTH > dev.txt
!python3 preprocess.py test_temp.txt $MODEL $MAX_LENGTH > test.txt
2020-04-22 23:02:05.747294: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Abierta con éxito la biblioteca dinámica libcudart.so.10.1
Descargando: 100% 1.03k/1.03k [00:00<00:00, 704kB/s]
Descargando: 100% 954k/954k [00:00<00:00, 1.89MB/s]
Descargando: 100% 512k/512k [00:00<00:00, 1,19MB/s]
Descargando: 100% 16.0/16.0 [00:00<00:00, 12.6kB/s]
2020-04-22 23:02:23.409488: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Se ha abierto correctamente la biblioteca dinámica libcudart.so.10.1
2020-04-22 23:02:31.168967: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Se ha abierto correctamente la biblioteca dinámica libcudart.so.10.1
3. Etiquetas
En los conjuntos de datos CoNLL-2002/2003, hay 9 clases de etiquetas NER:
- O, Fuera de una entidad con nombre
- B-MIS, Inicio de una entidad miscelánea justo después de otra entidad miscelánea
- I-MIS, Entidad diversa
- B-PER, Comienzo del nombre de una persona justo después del nombre de otra persona
- I-PER, Nombre de la persona
- B-ORG, Inicio de una organización justo después de otra organización
- I-ORG, Organización
- B-LOC, Inicio de una localización justo después de otra localización
- I-LOC, Localización
Si su conjunto de datos tiene etiquetas diferentes o más etiquetas que los conjuntos de datos CoNLL-2002/2003, ejecute la línea siguiente para obtener etiquetas únicas de sus datos y guardarlas en etiquetas.txt. Este archivo se utilizará cuando empecemos a afinar nuestro modelo.
cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
Modelo de ajuste
Estos son los scripts de ejemplo de transformadoresque utilizaremos para afinar nuestro modelo para NER. Después del 21/04/2020, Hugging Face ha actualizado sus scripts de ejemplo para utilizar un nuevo Entrenador clase. Para evitar cualquier conflicto futuro, vamos a utilizar la versión anterior a estas actualizaciones.
%ptura
wget "https://raw.githubusercontent.com/chriskhanhtran/spanish-bert/master/ner/run_ner.py"
wget "https://raw.githubusercontent.com/chriskhanhtran/spanish-bert/master/ner/utils_ner.py"
Ahora es el momento del aprendizaje por transferencia. En mi entrada anteriorHe preentrenado un modelo lingüístico RoBERTa en un corpus español muy amplio para predecir palabras enmascaradas en función del contexto en el que se encuentran. De este modo, el modelo ha aprendido propiedades inherentes al lenguaje. He subido el modelo preentrenado al servidor de Hugging Face. Ahora cargaremos el modelo y empezaremos a ajustarlo para la tarea NER.
A continuación se muestran nuestros hiperparámetros de entrenamiento.
MAX_LENGTH = 128 #@param {type: "integer"}
MODEL = "chriskhanhtran/spanberta" #@param ["chriskhanhtran/spanberta", "bert-base-multilingual-cased"]
OUTPUT_DIR = "spanberta-ner" #@param ["spanberta-ner", "bert-base-ml-ner"]
BATCH_SIZE = 32 #@param {type: "integer"}
NUM_EPOCHS = 3 #@param {type: "integer"}
SAVE_STEPS = 100 #@param {type: "integer"}
LOGGING_STEPS = 100 #@param {type: "integer"}
SEED = 42 #@param {type: "integer"}
Empecemos a entrenar.
python3 ejecutar_ner.py
--data_dir ./
-tipo_modelo bert
--labels ./labels.txt
--nombre_del_modelo_o_ruta $MODEL
--output_dir $OUTPUT_DIR
--max_seq_length $MAX_LENGTH
--num_train_epochs $NUM_EPOCHS
--per_gpu_train_batch_size $BATCH_SIZE
--save_steps $SAVE_STEPS
--logging_steps $LOGGING_STEPS
--seed $SEED
--do_train
--do_eval
--do_predict
--overwrite_output_dir
Rendimiento en el dev set:
21/04/2020 02:24:31 - INFO - __main__ - ***** Resultados de la evaluación *****
21/04/2020 02:24:31 - INFO - __main__ - f1 = 0.831027443864822
21/04/2020 02:24:31 - INFO - __main__ - pérdida = 0.1004064822183894
21/04/2020 02:24:31 - INFO - __main__ - precisión = 0.8207885304659498
21/04/2020 02:24:31 - INFO - __main__ - recall = 0.8415250344510795
Rendimiento en el conjunto de pruebas:
21/04/2020 02:24:48 - INFO - __main__ - ***** Resultados de la evaluación *****
21/04/2020 02:24:48 - INFO - __main__ - f1 = 0.8559533721898419
21/04/2020 02:24:48 - INFO - __main__ - pérdida = 0.06848683688204177
21/04/2020 02:24:48 - INFO - __main__ - precisión = 0.845858475041141
21/04/2020 02:24:48 - INFO - __main__ - recall = 0.8662921348314607
Estos son los tableros tensores de ajuste fino spanberta y bert-base-multilingüe-cased para 5 épocas. Podemos ver que los modelos sobreajustan los datos de entrenamiento después de 3 épocas.
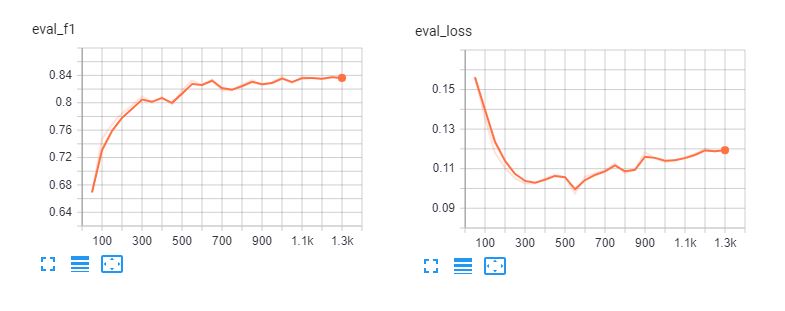
Informe de clasificación
Para comprender el rendimiento real de nuestro modelo, carguemos sus predicciones y examinemos el informe de clasificación.
def leer_ejemplos_desde_archivo(ruta_archivo):
"""Leer palabras y etiquetas de un archivo de datos CoNLL-2002/2003.
Args:
file_path (str): ruta al archivo de datos NER.
Devuelve:
ejemplos (dict): un diccionario con dos claves: palabras (lista de listas)
manteniendo las palabras en cada secuencia, y etiquetas (lista de listas) con
etiquetas correspondientes.
"""
with open(ruta_archivo, codificación="utf-8") as f:
ejemplos = {"palabras": [], "etiquetas": []}
palabras = []
etiquetas = []
para línea en f:
if linea.startswith("-DOCSTART-") or linea == "" or linea == "\n":
si palabras:
ejemplos["palabras"].append(palabras)
ejemplos["etiquetas"].append(etiquetas)
palabras = []
etiquetas = []
si no
divisiones = line.split(" ")
words.append(divisiones[0])
si len(splits) > 1
labels.append(splits[-1].replace("\n", ""))
else:
# Los ejemplos podrían no tener etiqueta para mode = "test"
labels.append("O")
devolver ejemplos
Leer datos y etiquetas de los archivos de texto sin procesar:
y_true = read_examples_from_file("test.txt")["labels"]
y_pred = read_examples_from_file("spanberta-ner/test_predictions.txt")["labels"]
Imprimir el informe de clasificación:
from seqeval.metrics import classification_report as classification_report_seqeval
print(informe_de_clasificación_seqeval(y_true, y_pred))
precisión recall f1-score support
LOC 0,87 0,84 0,85 1084
ORG 0,82 0,87 0,85 1401
MISC 0,63 0,66 0,65 340
PER 0,94 0,96 0,95 735
micro avg 0,84 0,86 0,85 3560
macro avg 0.84 0.86 0.85 3560
Las métricas que vemos en este informe están diseñadas específicamente para tareas de PLN como NER y etiquetado POS, en las que todas las palabras de una entidad deben predecirse correctamente para que se cuenten como una predicción correcta. Por tanto, las métricas de este informe de clasificación son mucho más bajas que las de informe de clasificación de scikit-learn.
importar numpy como np
from sklearn.metrics import informe_clasificación
print(informe_de_clasificación(np.concatenate(y_true), np.concatenate(y_pred)))
precisión recall f1-score support
B-LOC 0,88 0,85 0,86 1084
B-MISC 0,73 0,73 0,73 339
B-ORG 0,87 0,91 0,89 1400
B-PER 0,95 0,96 0,95 735
I-LOC 0,82 0,81 0,81 325
I-MISC 0,85 0,76 0,80 557
I-ORG 0,89 0,87 0,88 1104
I-PER 0,98 0,98 0,98 634
O 1.00 1.00 1.00 45355
precisión 0,98 51533
macro avg 0.89 0.87 0.88 51533
media ponderada 0,98 0,98 0,98 51533
A partir de los informes anteriores, nuestro modelo tiene un buen rendimiento en la predicción de persona, ubicación y organización. Necesitaremos más datos para MISC para mejorar el rendimiento de nuestro modelo en estas entidades.
Tuberías
Después de afinar nuestros modelos, podemos compartirlos con la comunidad siguiendo el tutorial en este página. Ahora podemos empezar a cargar el modelo afinado desde el servidor de Hugging Face y utilizarlo para predecir entidades con nombre en documentos españoles.
from transformers import pipeline, AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("skimai/spanberta-base-cased-ner-conll02")
tokenizer = AutoTokenizer.from_pretrained("skimai/spanberta-base-cased-ner-conll02")
ner_model = pipeline('ner', model=model, tokenizer=tokenizer)
El siguiente ejemplo se ha obtenido de La Opinión y significa "La recuperación económica de Estados Unidos tras la pandemia de coronavirus será cuestión de meses, ha afirmado el secretario del Tesoro, Steven Mnuchin."
sequence = "La recuperación económica de los Estados Unidos después de la " \
"pandemia del coronavirus será cuestión de meses, afirmó el " \
"Secretario del Tesoro, Steven Mnuchin".
ner_model(sequence)
[{'entidad': 'B-ORG', 'puntuación': 0.9155661463737488, 'palabra': 'ĠEstados'},
{'entidad': 'I-ORG', 'puntuación': 0.800682544708252, 'palabra': 'ĠUnidos'},
{'entidad': 'I-MISC', 'puntuación': 0.5006815791130066, 'palabra': 'Ġcorona'},
{'entidad': 'I-MISC', 'score': 0.510674774646759, 'word': 'virus'},
{'entidad': 'B-PER', 'puntuación': 0.5558510422706604, 'palabra': 'ĠSecretario'},
{'entidad': 'I-PER', 'score': 0.7758238315582275, 'word': 'Ġdel'},
{'entidad': 'I-PER', 'score': 0.7096233367919922, 'word': 'ĠTesoro'},
{'entidad': 'B-PER', 'puntuación': 0.9940345883369446, 'palabra': 'ĠSteven'},
{'entidad': 'I-PER', 'score': 0.9962581992149353, 'word': 'ĠM'},
{'entidad': 'I-PER', 'score': 0.9918380379676819, 'word': 'n'},
{'entidad': 'I-PER', 'score': 0.9848328828811646, 'word': 'uch'},
{'entidad': 'I-PER', 'score': 0.8513168096542358, 'word': 'in'}]
Tiene muy buena pinta. El modelo afinado reconoce con éxito todas las entidades de nuestro ejemplo, e incluso reconoce "corona virus".
Conclusión
El reconocimiento de entidades con nombre puede ayudarnos a extraer rápidamente información importante de los textos. Por lo tanto, su aplicación en los negocios puede tener un impacto directo en la mejora de la productividad humana en la lectura de contratos y documentos. Sin embargo, se trata de una tarea de PNL difícil, ya que el NER requiere una clasificación precisa a nivel de palabra, lo que hace que enfoques sencillos como la bolsa de palabras resulten imposibles de abordar.
Hemos visto cómo podemos aprovechar un modelo BERT preentrenado para obtener rápidamente un rendimiento excelente en la tarea NER para el español. El modelo SpanBERTa preentrenado también puede ajustarse para otras tareas, como la clasificación de documentos. He escrito un tutorial detallado para afinar BERT para la clasificación de secuencias y el análisis de sentimiento.
La siguiente parte de esta serie es la 3, en la que hablaremos de cómo utilizar ELECTRA, un enfoque de preentrenamiento más eficaz para los modelos de transformadores que puede alcanzar rápidamente un rendimiento de vanguardia. Permanezca atento.


