
What Is Deep Learning?



What is Deep Learning?
Deep learning (DL) is a subset of machine learning (ML) that primarily focuses on mimicking the human brain’s ability to learn and process information. In the rapidly evolving world of artificial intelligence (AI), deep learning has emerged as a groundbreaking technology that is impacting virtually every field, from healthcare to autonomous systems.
To achieve this ability to learn and process information, deep learning relies on a complex web of interconnected neurons called artificial neural networks (ANNs). By harnessing the power of ANNs and their ability to automatically adapt and improve over time, deep learning algorithms can discover intricate patterns, extract meaningful insights, and make predictions with remarkable accuracy.
*Before reading this blog on deep learning, make sure to check out our explanation of AI vs. ML.
The Building Blocks of Deep Learning
The foundation of deep learning is built upon the concept of ANNs, which are inspired by the structure and function of the human brain. ANNs consist of various layers of interconnected nodes or neurons, with each neuron processing information and passing it on to the next layer. These layers can then learn and adapt by adjusting the weights of the connections between the neurons.
Within an ANN, there are artificial neurons, with each one taking input from another before processing the information and sending the output to connected neurons. The strength of these connections between the neurons are known as weights, and these weights determine the importance of each input in the overall computation.
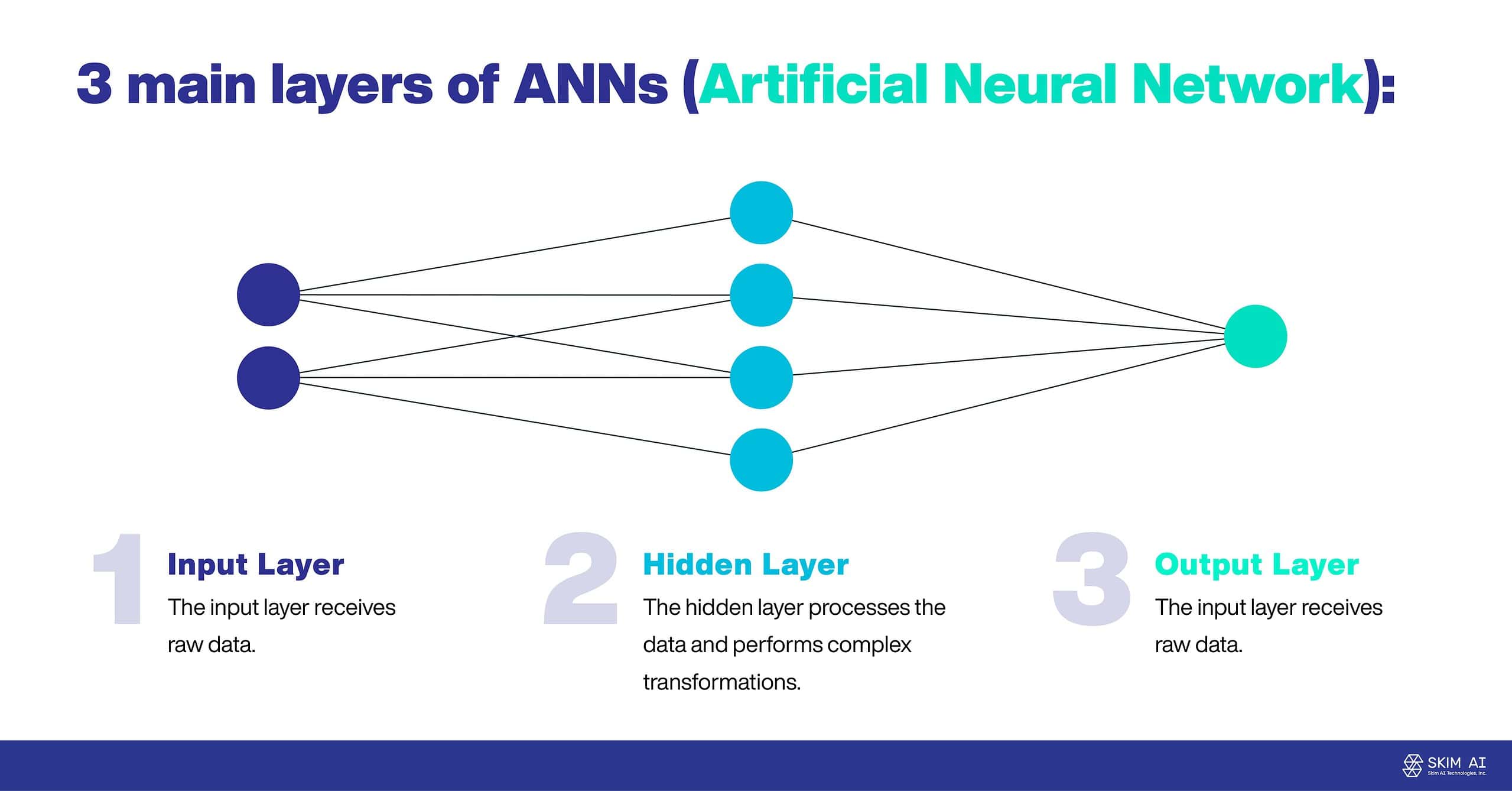
ANNs are often comprised of three main layers:
Input Layer: The input layer receives raw data.
Hidden Layer: The hidden layer processes the data and performs complex transformations.
Output Layer: The output layer produces the final result.
Another important building block of ANNs are activation functions, which determine the output of each neuron based on the input received. These functions introduce non-linearity into the network, enabling it to learn complex patterns and perform intricate computations.
Deep learning is all about the learning process, with the network adjusting its weights to minimize the error between its predictions and outcomes. This learning process often involves the use of a loss function, which quantifies the difference between the network’s output and the true values.
The Different Types of Learning Architectures
With all of that said, deep learning does not follow one learning architecture. There are a few main types of architectures that are used for a wide range of problems. Two of the most common are convolutional neural networks (CNNs) and recurrent neural networks (RNNs). However, there are several others, such as LSTMs, GRUs, and Autoencoders.
Convolutional Neural Networks (CNNs)
CNNs play a pivotal role in computer vision and image recognition tasks. Before the advent of CNNs, these tasks required laborious and time-intensive feature extraction techniques for object identification in images. In the context of image recognition, the primary function of a CNN is to transform images into a more manageable form while preserving essential features for accurate predictions.
CNNs often outperform other neural networks due to their exceptional performance with image, audio signal, or speech inputs.
They employ three main types of layers to accomplish their tasks:
Convolution Layer: Identifies features within pixels.
Pooling Layer: Abstracts features for further processing.
Fully-Connected (FC) Layer: Utilizes the acquired features for prediction.
The convolutional layer is the most fundamental component of a CNN, where the majority of the computation occurs. This layer consists of input data, a filter, and a feature map. Convolutional layers perform a convolution operation on the input before sending the result to the pooling layer.
In an image recognition task, this convolution condenses all pixels within its receptive field into a single value. In simpler terms, applying a convolution to an image reduces its size and combines all the information within the field into a single pixel. Basic features, such as horizontal and diagonal edges, are extracted in the convolutional layer. The output generated by the convolutional layer is referred to as the feature map.
The primary purpose of the pooling layer is to reduce the feature map’s size, thereby decreasing computation and connections between layers.
The third layer in a CNN is the FC layer, which connects neurons between two distinct layers. Often positioned before the output layer, the input images from previous layers are flattened. The flattened image typically passes through additional FC layers, where mathematical functions initiate the classification process.
Recurrent Neural Networks (RNNs)
Recurrent neural networks (RNNs) represent some of the most cutting-edge algorithms developed, and they are employed by widely-used technologies such as Siri and Google’s voice search.
The RNN is the first algorithm capable of retaining its input due to internal memory, which makes it valuable for machine learning problems involving sequential data like speech, text, financial data, audio, and more. The unique architecture of RNNs enables them to effectively capture dependencies and patterns within the sequences, allowing for more accurate predictions and better overall performance in a wide range of applications.
An RNN’s distinguishing feature is its ability to maintain a hidden state, which functions as an internal memory, allowing it to remember information from previous time steps. This memory capability enables RNNs to learn and exploit long-range dependencies within the input sequence, making them particularly effective for tasks like time series analysis, NLP, and speech recognition.
The structure of an RNN consists of a series of interconnected layers, where each layer is responsible for processing one time step of the input sequence. The input for each time step is a combination of the current data point and the hidden state from the previous time step. This information is then processed by the RNN layer, which updates the hidden state and generates an output. The hidden state acts as a memory, carrying information from earlier time steps to influence future processing.
Challenges of Deep Learning
Despite the remarkable successes of deep learning, there remain several challenges and areas for future research that warrant further exploration to advance the field and ensure responsible deployment of these technologies.
Interpretability and Explainability
One of the major limitations of deep learning models is their black-box nature, which refers to the opacity and complexity of their internal workings. This makes it difficult for practitioners, users, and regulators to understand and interpret the reasoning behind their predictions and decisions. Developing techniques for better interpretability and explainability is critical in addressing these concerns, and it has several important implications.

Enhanced interpretability and explainability will help users and stakeholders better understand how deep learning models arrive at their predictions or decisions, thereby fostering trust in their capabilities and reliability. This is particularly important in sensitive applications such as healthcare, finance, and criminal justice, where the consequences of AI decisions can significantly impact individuals’ lives.
The ability to interpret and explain deep learning models can also facilitate the identification and mitigation of potential biases, errors, or unintended consequences. By providing insights into the models’ inner workings, practitioners can make informed decisions about model selection, training, and deployment to ensure that AI systems are used responsibly and ethically.
Gaining insights into the internal processes of deep learning models can help practitioners identify issues or errors that may be impacting their performance. By understanding the factors that influence a model’s predictions, practitioners can fine-tune its architecture, training data, or hyperparameters to improve overall performance and accuracy.
Data and Computational Requirements for Deep Learning
Deep learning is incredibly powerful, but with this power comes significant data and computational requirements. These requirements can sometimes pose challenges for the implementation of deep learning.

One of the primary challenges in deep learning is the need for large quantities of labeled training data. Deep learning models often require vast amounts of data to learn and generalize effectively. This is because these models are designed to automatically extract and learn features from raw data, and the more data they have access to, the better they can identify and capture intricate patterns and relationships.
However, acquiring and labeling such vast amounts of data can be time-consuming, labor-intensive, and expensive. In some cases, labeled data may be scarce or difficult to obtain, particularly in specialized domains like medical imaging or rare languages. To address this challenge, researchers have explored various techniques such as data augmentation, transfer learning, and unsupervised or semi-supervised learning, which aim to improve model performance with limited labeled data.
Deep learning models also demand significant computational resources for training and inference. These models typically involve a large number of parameters and layers, which require powerful hardware and specialized processing units, like GPUs or TPUs, to perform the necessary calculations efficiently.
The computational demands of deep learning models can be prohibitive for some applications or organizations with limited resources, leading to longer training times and higher costs. To mitigate these challenges, researchers and practitioners have been investigating methods to optimize deep learning models and reduce the model’s size and complexity while maintaining its performance, ultimately leading to faster training times and lower resource requirements.
Robustness and Security
Deep learning models have demonstrated exceptional performance in various applications; however, they remain susceptible to adversarial attacks. These attacks entail creating malicious input samples deliberately engineered to deceive the model into generating incorrect predictions or outputs. Tackling these vulnerabilities and enhancing the robustness and security of deep learning models against adversarial examples and other potential risks is a critical challenge for the AI community. The consequences of such attacks can be far-reaching, especially in high-stakes domains such as autonomous vehicles, cybersecurity, and healthcare, where the integrity and reliability of AI systems are paramount.
Adversarial attacks exploit the sensitivity of deep learning models to small, often imperceptible perturbations in input data. Even minor alterations to the original data can lead to dramatically different predictions or classifications, despite the inputs appearing virtually identical to human observers. This phenomenon raises concerns about the stability and dependability of deep learning models in real-world scenarios where adversaries could manipulate inputs to compromise system performance.
Applications of Deep Learning
Deep learning has demonstrated its transformative potential across a wide range of applications and industries. Some of the most notable applications include:
- Image Recognition and Computer Vision: Deep learning has dramatically improved the accuracy and efficiency of image recognition and computer vision tasks. CNNs, in particular, have excelled at image classification, object detection, and segmentation. These advancements have paved the way for applications like facial recognition, autonomous vehicles, and medical image analysis.
- NLP: Deep learning has revolutionized natural language processing, enabling the development of more sophisticated language models and applications. Various models have been employed to achieve state-of-the-art results in tasks such as machine translation, sentiment analysis, text summarization, and question-answering systems.
- Speech Recognition and Generation: Deep learning has also made significant strides in speech recognition and generation. Techniques like RNNs and CNNs have been used to develop more accurate and efficient automatic speech recognition (ASR) systems, which convert spoken language into written text. Deep learning models have also enabled high-quality speech synthesis, generating human-like speech from text.
- Reinforcement Learning: Deep learning, when combined with reinforcement learning, has led to the development of deep reinforcement learning (DRL) algorithms. DRL has been employed to train agents capable of learning optimal policies for decision-making and control. Applications of DRL span across robotics, finance, and gaming.
- Generative Models: Generative deep learning models, such as Generative Adversarial Networks (GANs), have shown remarkable potential for generating realistic data samples. These models have been utilized for tasks like image synthesis, style transfer, data augmentation, and anomaly detection.
- Healthcare: Deep learning has also made significant contributions to healthcare, revolutionizing diagnostics, drug discovery, and personalized medicine. For example, deep learning algorithms have been used to analyze medical images for early detection of diseases, predict patient outcomes, and identify potential drug candidates.
Revolutionizing Industries and Applications
Deep learning has emerged as a groundbreaking technology with the potential to revolutionize a wide array of industries and applications. At its core, deep learning leverages artificial neural networks to mimic the human brain’s ability to learn and process information. CNNs and RNNs are two prominent architectures that have enabled significant advancements in fields such as image recognition, NLP, speech recognition, and healthcare.
Deep learning still faces challenges that need to be addressed to ensure its responsible and ethical deployment. These challenges include improving the interpretability and explainability of deep learning models, addressing data and computational requirements, and enhancing the robustness and security of these models against adversarial attacks.
As researchers and practitioners continue to explore and develop innovative techniques to tackle these challenges, the field of deep learning will undoubtedly continue to advance, bringing forth new capabilities and applications that will transform the way we live, work, and interact with the world around us. With its immense potential, deep learning is set to play an increasingly important role in shaping the future of artificial intelligence and driving technological progress across various domains


