
O que é a aprendizagem profunda?



O que é a aprendizagem profunda?
O que é a aprendizagem profunda? A aprendizagem profunda (AP) é um subconjunto da aprendizagem automática (AM) que se concentra principalmente em imitar a capacidade do cérebro humano de aprender e processar informações. No mundo em rápida evolução da inteligência artificial (IA), a aprendizagem profunda emergiu como uma tecnologia inovadora que está a ter impacto em praticamente todos os campos, desde os cuidados de saúde até à...
Para alcançar esta capacidade de aprender e processar informação, a aprendizagem profunda baseia-se numa rede complexa de neurónios interligados denominados redes neuronais artificiais (RNA). Ao aproveitar o poder das RNAs e a sua capacidade de se adaptarem e melhorarem automaticamente ao longo do tempo, os algoritmos de aprendizagem profunda podem descobrir padrões complexos, extrair conhecimentos significativos e fazer previsões com uma precisão notável.
*Antes de ler este blogue sobre aprendizagem profunda, não se esqueça de consultar a nossa explicação sobre IA vs. ML.
Os blocos de construção da aprendizagem profunda
A base da aprendizagem profunda assenta no conceito de RNA, que se inspira na estrutura e função do cérebro humano. As RNAs são constituídas por várias camadas de nós ou neurónios interligados, em que cada neurónio processa a informação e a transmite à camada seguinte. Estas camadas podem então aprender e adaptar-se ajustando os pesos das ligações entre os neurónios.
Numa RNA, existem neurónios artificiais, em que cada um deles recebe um input de outro antes de processar a informação e enviar o output para os neurónios ligados. A força destas ligações entre os neurónios é conhecida como pesos, e estes pesos determinam a importância de cada entrada no cálculo global.
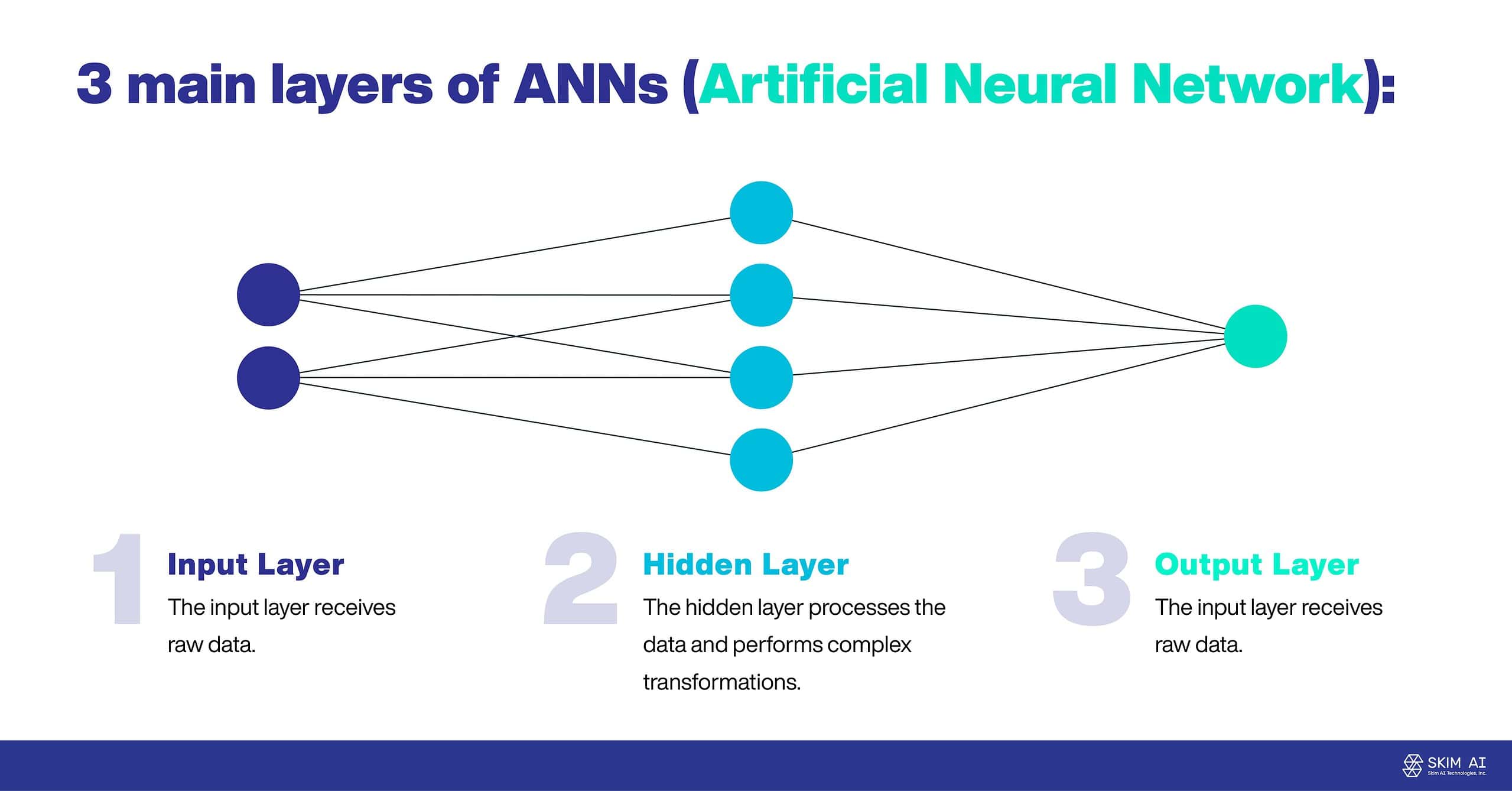
As RNA são frequentemente compostas por três camadas principais:
Camada de entrada: A camada de entrada recebe dados em bruto.
Camada oculta: A camada oculta processa os dados e efectua transformações complexas.
Camada de saída: A camada de saída produz o resultado final.
Outro elemento importante das RNAs são as funções de ativação, que determinam a saída de cada neurónio com base na entrada recebida. Estas funções introduzem a não linearidade na rede, permitindo-lhe aprender padrões complexos e efetuar cálculos complexos.
A aprendizagem profunda tem tudo a ver com o processo de aprendizagem, com a rede a ajustar os seus pesos para minimizar o erro entre as suas previsões e os resultados. Este processo de aprendizagem envolve frequentemente a utilização de uma função de perda, que quantifica a diferença entre o resultado da rede e os valores reais.
Os diferentes tipos de arquitecturas de aprendizagem
Dito isto, a aprendizagem profunda não segue uma única arquitetura de aprendizagem. Existem alguns tipos principais de arquitecturas que são utilizadas para uma vasta gama de problemas. Duas das mais comuns são as redes neurais convolucionais (CNNs) e as redes neurais recorrentes (RNNs). No entanto, existem várias outras, tais como LSTMs, GRUs e Autoencoders.
Redes Neuronais Convolucionais (CNNs)
As CNN desempenham um papel fundamental nas tarefas de visão computacional e de reconhecimento de imagens. Antes do advento das CNN, estas tarefas exigiam técnicas de extração de características laboriosas e demoradas para a identificação de objectos nas imagens. No contexto do reconhecimento de imagens, a principal função de uma CNN é transformar as imagens numa forma mais fácil de gerir, preservando simultaneamente as características essenciais para previsões exactas.
As CNN superam frequentemente outras redes neuronais devido ao seu desempenho excecional com imagens, sinais de áudio ou entradas de voz.
Utilizam três tipos principais de camadas para realizar as suas tarefas:
Camada de convolução: Identifica características dentro de pixéis.
Camada de Pooling: Abstrai características para processamento posterior.
Camada totalmente conectada (FC): Utiliza as características adquiridas para a previsão.
A camada convolucional é o componente mais fundamental de uma CNN, onde ocorre a maior parte do cálculo. Esta camada é constituída por dados de entrada, um filtro e um mapa de características. As camadas convolucionais efectuam uma operação de convolução na entrada antes de enviar o resultado para a camada de pooling.
Numa tarefa de reconhecimento de imagem, esta convolução condensa todos os pixels do seu campo recetivo num único valor. Em termos mais simples, a aplicação de uma convolução a uma imagem reduz o seu tamanho e combina toda a informação dentro do campo num único pixel. As características básicas, como as arestas horizontais e diagonais, são extraídas na camada convolucional. A saída gerada pela camada convolucional é designada por mapa de características.
O objetivo principal da camada de agrupamento é reduzir o tamanho do mapa de características, diminuindo assim a computação e as ligações entre camadas.
A terceira camada de uma CNN é a camada FC, que liga os neurónios entre duas camadas distintas. Muitas vezes posicionada antes da camada de saída, as imagens de entrada das camadas anteriores são achatadas. A imagem achatada passa normalmente por camadas FC adicionais, onde funções matemáticas iniciam o processo de classificação.
Redes Neuronais Recorrentes (RNNs)
As redes neuronais recorrentes (RNN) representam alguns dos algoritmos mais avançados desenvolvidos e são empregues por tecnologias amplamente utilizadas, como a Siri e a pesquisa por voz do Google.
O RNN é o primeiro algoritmo capaz de reter a sua entrada devido à memória interna, o que o torna valioso para problemas de aprendizagem automática que envolvam dados sequenciais, como fala, texto, dados financeiros, áudio e muito mais. A arquitetura única dos RNN permite-lhes captar eficazmente dependências e padrões dentro das sequências, permitindo previsões mais precisas e um melhor desempenho global numa vasta gama de aplicações.
A caraterística distintiva de uma RNN é a sua capacidade de manter um estado oculto, que funciona como uma memória interna, permitindo-lhe recordar informações de passos de tempo anteriores. Esta capacidade de memória permite que as RNNs aprendam e explorem dependências de longo alcance dentro da sequência de entrada, tornando-as particularmente eficazes para tarefas como análise de séries temporais, PNL e reconhecimento de voz.
A estrutura de uma RNN consiste numa série de camadas interligadas, em que cada camada é responsável pelo processamento de um passo de tempo da sequência de entrada. A entrada para cada passo de tempo é uma combinação do ponto de dados atual e do estado oculto do passo de tempo anterior. Esta informação é então processada pela camada RNN, que actualiza o estado oculto e gera uma saída. O estado oculto actua como uma memória, transportando informações de passos de tempo anteriores para influenciar o processamento futuro.
Desafios da aprendizagem profunda
Apesar dos notáveis êxitos da aprendizagem profunda, subsistem vários desafios e áreas de investigação futura que merecem ser explorados para fazer avançar o domínio e garantir uma implantação responsável destas tecnologias.
Interpretabilidade e explicabilidade
Uma das principais limitações dos modelos de aprendizagem profunda é a sua natureza de caixa negra, que se refere à opacidade e complexidade do seu funcionamento interno. Isto torna difícil para os profissionais, utilizadores e reguladores compreender e interpretar o raciocínio subjacente às suas previsões e decisões. Desenvolvimento de técnicas para uma melhor interpretabilidade e explicabilidade é fundamental para responder a estas preocupações e tem várias implicações importantes.

Uma maior interpretabilidade e explicabilidade ajudará os utilizadores e as partes interessadas a compreender melhor como os modelos de aprendizagem profunda chegam às suas previsões ou decisões, promovendo assim a confiança nas suas capacidades e fiabilidade. Isto é particularmente importante em aplicações sensíveis como cuidados de saúdeA IA pode ser utilizada em vários sectores, como o financeiro e a justiça penal, em que as consequências das decisões da IA podem ter um impacto significativo na vida das pessoas.
A capacidade de interpretar e explicar os modelos de aprendizagem profunda também pode facilitar a identificação e a mitigação de potenciais enviesamentos, erros ou consequências não intencionais. Ao fornecer informações sobre o funcionamento interno dos modelos, os profissionais podem tomar decisões informadas sobre a seleção, formação e implementação de modelos para garantir que os sistemas de IA são utilizados de forma responsável e ética.
A obtenção de informações sobre os processos internos dos modelos de aprendizagem profunda pode ajudar os profissionais a identificar problemas ou erros que possam estar a afetar o seu desempenho. Ao compreender os factores que influenciam as previsões de um modelo, os profissionais podem ajustar a sua arquitetura, os dados de treino ou os hiperparâmetros para melhorar o desempenho e a precisão gerais.
Requisitos computacionais e de dados para a aprendizagem profunda
A aprendizagem profunda é incrivelmente poderosa, mas com esse poder vêm requisitos computacionais e de dados significativos. Estes requisitos podem, por vezes, colocar desafios à implementação da aprendizagem profunda.

Um dos principais desafios da aprendizagem profunda é a necessidade de grandes quantidades de dados de formação rotulados. Os modelos de aprendizagem profunda requerem frequentemente grandes quantidades de dados para aprender e generalizar eficazmente. Isto deve-se ao facto de estes modelos serem concebidos para extrair e aprender automaticamente características a partir de dados em bruto, e quanto mais dados tiverem acesso, melhor podem identificar e captar padrões e relações intrincados.
No entanto, a aquisição e rotulagem de quantidades tão grandes de dados pode ser demorada, trabalhosa e dispendiosa. Nalguns casos, os dados rotulados podem ser escassos ou difíceis de obter, especialmente em domínios especializados como a imagiologia médica ou as línguas raras. Para enfrentar este desafio, os investigadores exploraram várias técnicas, como o aumento de dados, a aprendizagem por transferência e a aprendizagem não supervisionada ou semi-supervisionada, que visam melhorar o desempenho do modelo com dados rotulados limitados.
Os modelos de aprendizagem profunda também exigem recursos computacionais significativos para a formação e a inferência. Estes modelos envolvem normalmente um grande número de parâmetros e camadas, que exigem hardware potente e unidades de processamento especializadas, como GPUs ou TPUs, para efetuar os cálculos necessários de forma eficiente.
As exigências computacionais dos modelos de aprendizagem profunda podem ser proibitivas para algumas aplicações ou organizações com recursos limitados, levando a tempos de formação mais longos e custos mais elevados. Para atenuar estes desafios, investigadores e profissionais têm investigado métodos para otimizar os modelos de aprendizagem profunda e reduzir o tamanho e a complexidade do modelo, mantendo o seu desempenho, o que, em última análise, conduz a tempos de formação mais rápidos e a menores requisitos de recursos.
Robustez e segurança
Os modelos de aprendizagem profunda demonstraram um desempenho excecional em várias aplicações; no entanto, continuam a ser susceptíveis de ataques adversários. Estes ataques implicam a criação de amostras de entrada maliciosas, deliberadamente concebidas para enganar o modelo, levando-o a gerar previsões ou resultados incorrectos. Combater estas vulnerabilidades e aumentar a robustez e a segurança dos modelos de aprendizagem profunda contra exemplos adversários e outros riscos potenciais é um desafio crítico para a comunidade de IA. As consequências de tais ataques podem ser de grande alcance, especialmente em domínios de grande importância, como os veículos autónomos, a cibersegurança e os cuidados de saúde, em que a integridade e a fiabilidade dos sistemas de IA são fundamentais.
Os ataques adversários exploram a sensibilidade dos modelos de aprendizagem profunda a pequenas perturbações, muitas vezes imperceptíveis, nos dados de entrada. Mesmo pequenas alterações nos dados originais podem levar a previsões ou classificações drasticamente diferentes, apesar de as entradas parecerem praticamente idênticas aos observadores humanos. Este fenómeno suscita preocupações quanto à estabilidade e fiabilidade dos modelos de aprendizagem profunda em cenários reais em que os adversários podem manipular os dados de entrada para comprometer o desempenho do sistema.
Aplicações da aprendizagem profunda
A aprendizagem profunda demonstrou o seu potencial transformador numa vasta gama de aplicações e sectores. Algumas das aplicações mais notáveis incluem:
- Reconhecimento de imagens e visão por computador: A aprendizagem profunda melhorou drasticamente a precisão e a eficiência do reconhecimento de imagens e das tarefas de visão computacional. As CNNs, em particular, têm-se destacado na classificação de imagens, deteção de objectos e segmentação. Estes avanços abriram caminho para aplicações como o reconhecimento facial, veículos autónomos e análise de imagens médicas.
- PNL: A aprendizagem profunda revolucionou o processamento de linguagem natural, permitindo o desenvolvimento de modelos e aplicações de linguagem mais sofisticados. Vários modelos têm sido utilizados para obter resultados de ponta em tarefas como tradução automática, análise de sentimentos, resumo de texto e sistemas de resposta a perguntas.
- Reconhecimento e geração de fala: A aprendizagem profunda também fez progressos significativos no reconhecimento e geração de fala. Técnicas como RNNs e CNNs têm sido usadas para desenvolver sistemas de reconhecimento automático de fala (ASR) mais precisos e eficientes, que convertem a linguagem falada em texto escrito. Os modelos de aprendizagem profunda também permitiram a síntese de fala de alta qualidade, gerando fala semelhante à humana a partir de texto.
- Aprendizagem por reforço: A aprendizagem profunda, quando combinada com a aprendizagem por reforço, conduziu ao desenvolvimento de aprendizagem por reforço profundo (DRL) algoritmos. O DRL tem sido utilizado para formar agentes capazes de aprender políticas óptimas para a tomada de decisões e o controlo. As aplicações do DRL abrangem a robótica, as finanças e os jogos.
- Modelos generativos: Modelos generativos de aprendizagem profunda, tais como Redes Adversariais Generativas (GANs)Os modelos de análise de dados (modelos de imagem), que são modelos de análise de dados, mostraram um potencial notável para gerar amostras de dados realistas. Estes modelos têm sido utilizados em tarefas como a síntese de imagens, a transferência de estilos, o aumento de dados e a deteção de anomalias.
- Saúde: A aprendizagem profunda também fez contribuições significativas para a área da saúde, revolucionando o diagnóstico, a descoberta de medicamentos e a medicina personalizada. Por exemplo, algoritmos de aprendizagem profunda têm sido usados para analisar imagens médicas para deteção precoce de doenças, prever resultados de pacientes e identificar possíveis candidatos a medicamentos.
Revolucionando indústrias e aplicações
A aprendizagem profunda surgiu como uma tecnologia inovadora com o potencial de revolucionar uma vasta gama de sectores e aplicações. Na sua essência, a aprendizagem profunda utiliza redes neurais artificiais para imitar a capacidade do cérebro humano de aprender e processar informações. As CNN e as RNN são duas arquitecturas proeminentes que permitiram avanços significativos em domínios como o reconhecimento de imagens, a PNL, o reconhecimento da fala e os cuidados de saúde.
A aprendizagem profunda continua a enfrentar desafios que têm de ser resolvidos para garantir a sua utilização responsável e ética. Estes desafios incluem a melhoria da interpretabilidade e explicabilidade dos modelos de aprendizagem profunda, a abordagem dos requisitos de dados e computacionais e o reforço da robustez e segurança destes modelos contra ataques adversários.
À medida que os investigadores e os profissionais continuam a explorar e a desenvolver técnicas inovadoras para enfrentar estes desafios, o domínio da aprendizagem profunda continuará, sem dúvida, a avançar, trazendo novas capacidades e aplicações que transformarão a forma como vivemos, trabalhamos e interagimos com o mundo que nos rodeia. Com o seu imenso potencial, a aprendizagem profunda deverá desempenhar um papel cada vez mais importante na definição do futuro da inteligência artificial e na promoção do progresso tecnológico em vários domínios


