
Qu'est-ce que l'apprentissage profond ?



Qu'est-ce que l'apprentissage profond ?
Qu'est-ce que l'apprentissage profond ? Le deep learning (DL) est un sous-ensemble du machine learning (ML) qui se concentre principalement sur l'imitation de la capacité du cerveau humain à apprendre et à traiter des informations. Dans le monde de l'intelligence artificielle (IA), qui évolue rapidement, l'apprentissage profond s'est imposé comme une technologie révolutionnaire qui a un impact sur pratiquement tous les domaines, des soins de santé à l'autonomie...
Pour parvenir à cette capacité d'apprentissage et de traitement des informations, l'apprentissage profond s'appuie sur un réseau complexe de neurones interconnectés appelés réseaux neuronaux artificiels (RNA). En exploitant la puissance des réseaux neuronaux artificiels et leur capacité à s'adapter et à s'améliorer automatiquement au fil du temps, les algorithmes d'apprentissage profond peuvent découvrir des modèles complexes, extraire des informations significatives et faire des prédictions avec une précision remarquable.
*Avant de lire ce blog sur l'apprentissage profond, n'oubliez pas de consulter notre explication de l'IA par rapport au ML.
Les éléments constitutifs de l'apprentissage profond
Le fondement de l'apprentissage profond repose sur le concept d'ANN, qui s'inspire de la structure et de la fonction du cerveau humain. Les ANN sont constitués de différentes couches de nœuds ou de neurones interconnectés, chaque neurone traitant les informations et les transmettant à la couche suivante. Ces couches peuvent ensuite apprendre et s'adapter en ajustant les poids des connexions entre les neurones.
Dans un ANN, il y a des neurones artificiels, chacun d'entre eux recevant une entrée d'un autre avant de traiter l'information et d'envoyer la sortie aux neurones connectés. La force de ces connexions entre les neurones est appelée poids, et ces poids déterminent l'importance de chaque entrée dans le calcul global.
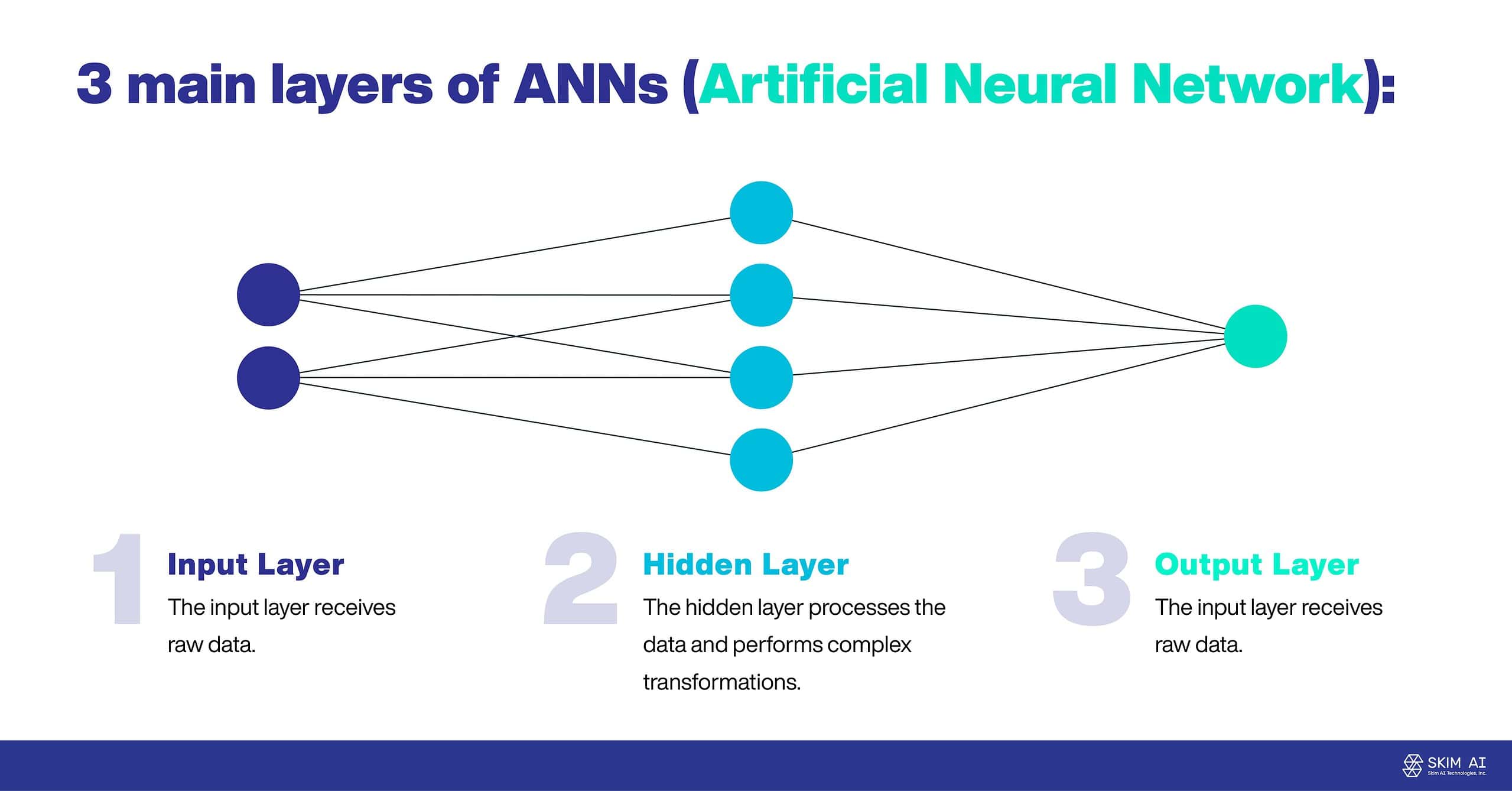
Les ANN sont souvent composés de trois couches principales :
Couche d'entrée : La couche d'entrée reçoit les données brutes.
Couche cachée : La couche cachée traite les données et effectue des transformations complexes.
Couche de sortie : La couche de sortie produit le résultat final.
Les fonctions d'activation, qui déterminent la sortie de chaque neurone en fonction de l'entrée reçue, constituent un autre élément important des ANN. Ces fonctions introduisent la non-linéarité dans le réseau, ce qui lui permet d'apprendre des modèles complexes et d'effectuer des calculs compliqués.
L'apprentissage profond repose sur le processus d'apprentissage, le réseau ajustant ses poids afin de minimiser l'erreur entre ses prédictions et ses résultats. Ce processus d'apprentissage implique souvent l'utilisation d'une fonction de perte, qui quantifie la différence entre la sortie du réseau et les valeurs réelles.
Les différents types d'architectures d'apprentissage
Cela dit, l'apprentissage profond ne suit pas une architecture d'apprentissage unique. Il existe quelques grands types d'architectures qui sont utilisés pour un large éventail de problèmes. Deux des plus courantes sont les réseaux neuronaux convolutifs (CNN) et les réseaux neuronaux récurrents (RNN). Il en existe toutefois plusieurs autres, tels que LSTMs, GRUs et Autoencodeurs.
Réseaux neuronaux convolutifs (CNN)
Les CNN jouent un rôle essentiel dans les tâches de vision artificielle et de reconnaissance d'images. Avant l'avènement des CNN, ces tâches nécessitaient des techniques d'extraction de caractéristiques laborieuses et fastidieuses pour l'identification d'objets dans les images. Dans le contexte de la reconnaissance d'images, la fonction première d'un CNN est de transformer les images en une forme plus facile à gérer tout en préservant les caractéristiques essentielles pour des prédictions précises.
Les CNN sont souvent plus performants que les autres réseaux neuronaux en raison de leurs performances exceptionnelles avec des images, des signaux audio ou des données vocales.
Ils utilisent trois principaux types de couches pour accomplir leurs tâches :
Couche de convolution: Identifie les caractéristiques à l'intérieur des pixels.
Couche de mise en commun: Résume les caractéristiques en vue d'un traitement ultérieur.
Couche entièrement connectée (FC): Utilise les caractéristiques acquises pour la prédiction.
La couche convolutive est le composant le plus fondamental d'un CNN, où se produit la majorité des calculs. Cette couche se compose de données d'entrée, d'un filtre et d'une carte de caractéristiques. Les couches convolutives effectuent une opération de convolution sur l'entrée avant d'envoyer le résultat à la couche de mise en commun.
Dans une tâche de reconnaissance d'images, cette convolution condense tous les pixels de son champ réceptif en une seule valeur. En termes plus simples, l'application d'une convolution à une image réduit sa taille et combine toutes les informations contenues dans le champ en un seul pixel. Les caractéristiques de base, telles que les bords horizontaux et diagonaux, sont extraites dans la couche convolutive. La sortie générée par la couche convolutive est appelée carte des caractéristiques.
L'objectif principal de la couche de mise en commun est de réduire la taille de la carte des caractéristiques, diminuant ainsi les calculs et les connexions entre les couches.
La troisième couche d'un CNN est la couche FC, qui relie les neurones entre deux couches distinctes. Souvent placée avant la couche de sortie, elle aplatit les images d'entrée des couches précédentes. L'image aplatie passe généralement par des couches FC supplémentaires, où des fonctions mathématiques lancent le processus de classification.
Réseaux neuronaux récurrents (RNN)
Les réseaux neuronaux récurrents (RNN) comptent parmi les algorithmes les plus avancés qui aient été mis au point. Ils sont utilisés par des technologies très répandues telles que Siri et la recherche vocale de Google.
Le RNN est le premier algorithme capable de conserver son entrée grâce à une mémoire interne, ce qui le rend précieux pour les problèmes d'apprentissage automatique impliquant des données séquentielles telles que la parole, le texte, les données financières, l'audio, etc. L'architecture unique des RNN leur permet de capturer efficacement les dépendances et les modèles au sein des séquences, ce qui permet des prédictions plus précises et de meilleures performances globales dans un large éventail d'applications.
La caractéristique distinctive d'un RNN est sa capacité à maintenir un état caché, qui fonctionne comme une mémoire interne, lui permettant de se souvenir des informations des étapes temporelles précédentes. Cette capacité de mémoire permet aux RNN d'apprendre et d'exploiter les dépendances à long terme dans la séquence d'entrée, ce qui les rend particulièrement efficaces pour des tâches telles que l'analyse de séries temporelles, la PNL et la reconnaissance vocale.
La structure d'un RNN consiste en une série de couches interconnectées, où chaque couche est responsable du traitement d'un pas de temps de la séquence d'entrée. L'entrée de chaque pas de temps est une combinaison du point de données actuel et de l'état caché du pas de temps précédent. Ces informations sont ensuite traitées par la couche RNN, qui met à jour l'état caché et génère une sortie. L'état caché agit comme une mémoire, contenant les informations des étapes temporelles précédentes afin d'influencer le traitement futur.
Les défis de l'apprentissage profond
Malgré les succès remarquables de l'apprentissage profond, il reste plusieurs défis et domaines de recherche future qui méritent d'être explorés davantage pour faire progresser le domaine et assurer un déploiement responsable de ces technologies.
Interprétabilité et explicabilité
L'une des principales limites des modèles d'apprentissage profond est leur nature de boîte noire, c'est-à-dire l'opacité et la complexité de leur fonctionnement interne. Il est donc difficile pour les praticiens, les utilisateurs et les régulateurs de comprendre et d'interpréter le raisonnement qui sous-tend leurs prédictions et leurs décisions. Développer des techniques pour une meilleure interprétabilité et explicabilité est essentiel pour répondre à ces préoccupations, et il a plusieurs implications importantes.

L'amélioration de l'interprétabilité et de l'explicabilité aidera les utilisateurs et les parties prenantes à mieux comprendre comment les modèles d'apprentissage profond parviennent à leurs prédictions ou à leurs décisions, ce qui renforcera la confiance dans leurs capacités et leur fiabilité. Cela est particulièrement important pour les applications sensibles telles que soins de santéLes conséquences des décisions prises par l'IA peuvent avoir un impact considérable sur la vie des individus.
La capacité d'interpréter et d'expliquer les modèles d'apprentissage profond peut également faciliter l'identification et l'atténuation des biais potentiels, des erreurs ou des conséquences involontaires. En donnant un aperçu du fonctionnement interne des modèles, les praticiens peuvent prendre des décisions éclairées sur la sélection, la formation et le déploiement des modèles afin de garantir que les systèmes d'IA sont utilisés de manière responsable et éthique.
La compréhension des processus internes des modèles d'apprentissage profond peut aider les praticiens à identifier les problèmes ou les erreurs susceptibles d'avoir un impact sur leurs performances. En comprenant les facteurs qui influencent les prédictions d'un modèle, les praticiens peuvent affiner son architecture, ses données d'entraînement ou ses hyperparamètres afin d'améliorer les performances globales et la précision.
Exigences en matière de données et de calcul pour l'apprentissage profond
L'apprentissage profond est incroyablement puissant, mais cette puissance s'accompagne d'exigences importantes en matière de données et de calcul. Ces exigences peuvent parfois poser des problèmes pour la mise en œuvre de l'apprentissage profond.

L'un des principaux défis de l'apprentissage profond est la nécessité de disposer de grandes quantités de données de formation étiquetées. Les modèles d'apprentissage profond ont souvent besoin de grandes quantités de données pour apprendre et généraliser efficacement. En effet, ces modèles sont conçus pour extraire et apprendre automatiquement des caractéristiques à partir de données brutes, et plus ils ont accès à des données, mieux ils peuvent identifier et capturer des modèles et des relations complexes.
Cependant, l'acquisition et l'étiquetage de telles quantités de données peuvent prendre du temps, nécessiter beaucoup de travail et être coûteux. Dans certains cas, les données étiquetées peuvent être rares ou difficiles à obtenir, en particulier dans des domaines spécialisés comme l'imagerie médicale ou les langues rares. Pour relever ce défi, les chercheurs ont exploré diverses techniques telles que l'augmentation des données, l'apprentissage par transfert et l'apprentissage non supervisé ou semi-supervisé, qui visent à améliorer les performances des modèles avec des données étiquetées limitées.
Les modèles d'apprentissage profond nécessitent également des ressources informatiques importantes pour la formation et l'inférence. Ces modèles comportent généralement un grand nombre de paramètres et de couches, ce qui nécessite un matériel puissant et des unités de traitement spécialisées, comme les GPU ou les TPU, pour effectuer les calculs nécessaires de manière efficace.
Les exigences de calcul des modèles d'apprentissage profond peuvent être prohibitives pour certaines applications ou organisations disposant de ressources limitées, ce qui entraîne des temps de formation plus longs et des coûts plus élevés. Pour atténuer ces difficultés, les chercheurs et les praticiens ont étudié des méthodes permettant d'optimiser les modèles d'apprentissage profond et de réduire la taille et la complexité du modèle tout en maintenant ses performances, ce qui permet en fin de compte d'accélérer les temps de formation et de réduire les besoins en ressources.
Robustesse et sécurité
Les modèles d'apprentissage profond ont démontré des performances exceptionnelles dans diverses applications. les attaques adverses. Ces attaques impliquent la création d'échantillons d'entrée malveillants délibérément conçus pour tromper le modèle et générer des prédictions ou des résultats incorrects. S'attaquer à ces vulnérabilités et améliorer la robustesse et la sécurité des modèles d'apprentissage profond contre les exemples adverses et d'autres risques potentiels est un défi essentiel pour la communauté de l'IA. Les conséquences de telles attaques peuvent être considérables, en particulier dans des domaines à fort enjeu tels que les véhicules autonomes, la cybersécurité et les soins de santé, où l'intégrité et la fiabilité des systèmes d'IA sont primordiales.
Les attaques adverses exploitent la sensibilité des modèles d'apprentissage profond à de petites perturbations, souvent imperceptibles, des données d'entrée. Même des altérations mineures des données d'origine peuvent conduire à des prédictions ou à des classifications radicalement différentes, alors que les données d'entrée semblent pratiquement identiques pour les observateurs humains. Ce phénomène soulève des inquiétudes quant à la stabilité et à la fiabilité des modèles d'apprentissage profond dans des scénarios réels où des adversaires pourraient manipuler les données d'entrée pour compromettre les performances du système.
Applications de l'apprentissage profond
L'apprentissage profond a démontré son potentiel de transformation dans un large éventail d'applications et d'industries. Parmi les applications les plus remarquables, on peut citer
- Reconnaissance d'images et vision par ordinateur : L'apprentissage profond a considérablement amélioré la précision et l'efficacité des tâches de reconnaissance d'images et de vision par ordinateur. Les CNN, en particulier, ont excellé dans la classification d'images, la détection d'objets et la segmentation. Ces progrès ont ouvert la voie à des applications telles que la reconnaissance faciale, les véhicules autonomes et l'analyse d'images médicales.
- NLP : L'apprentissage profond a révolutionné le traitement du langage naturel, permettant le développement de modèles de langage et d'applications plus sophistiqués. Divers modèles ont été utilisés pour obtenir des résultats de pointe dans des tâches telles que la traduction automatique, l'analyse des sentiments, le résumé de texte et les systèmes de réponse aux questions.
- Reconnaissance et génération de la parole : L'apprentissage profond a également fait des progrès significatifs dans la reconnaissance et la génération de la parole. Des techniques telles que les RNN et les CNN ont été utilisées pour développer des systèmes de reconnaissance automatique de la parole (ASR) plus précis et plus efficaces, qui convertissent la langue parlée en texte écrit. Les modèles d'apprentissage profond ont également permis une synthèse vocale de haute qualité, générant une parole semblable à celle d'un être humain à partir d'un texte.
- Apprentissage par renforcement : L'apprentissage en profondeur, combiné à l'apprentissage par renforcement, a conduit au développement de la technologie de l'apprentissage par renforcement. l'apprentissage par renforcement profond (DRL) algorithmes. La LRD a été utilisée pour former des agents capables d'apprendre des politiques optimales de prise de décision et de contrôle. Les applications de la LRD couvrent la robotique, la finance et les jeux.
- Modèles génératifs : Les modèles d'apprentissage profond génératifs, tels que Réseaux adversoriels génératifs (GAN)ont montré un potentiel remarquable pour la génération d'échantillons de données réalistes. Ces modèles ont été utilisés pour des tâches telles que la synthèse d'images, le transfert de style, l'augmentation des données et la détection d'anomalies.
- Soins de santé : L'apprentissage profond a également apporté des contributions significatives aux soins de santé, révolutionnant les diagnostics, la découverte de médicaments et la médecine personnalisée. Par exemple, les algorithmes d'apprentissage profond ont été utilisés pour analyser des images médicales en vue de la détection précoce de maladies, pour prédire les résultats des patients et pour identifier des médicaments candidats potentiels.
Révolutionner les industries et les applications
L'apprentissage profond s'est imposé comme une technologie révolutionnaire susceptible de bouleverser un large éventail d'industries et d'applications. L'apprentissage profond s'appuie sur des réseaux de neurones artificiels pour imiter la capacité du cerveau humain à apprendre et à traiter des informations. Les CNN et les RNN sont deux architectures de premier plan qui ont permis des avancées significatives dans des domaines tels que la reconnaissance d'images, le NLP, la reconnaissance vocale et les soins de santé.
L'apprentissage profond reste confronté à des défis qu'il convient de relever pour garantir son déploiement responsable et éthique. Ces défis comprennent l'amélioration de l'interprétabilité et de l'explicabilité des modèles d'apprentissage profond, la prise en compte des exigences en matière de données et de calcul, et l'amélioration de la robustesse et de la sécurité de ces modèles contre les attaques adverses.
Alors que les chercheurs et les praticiens continuent d'explorer et de développer des techniques innovantes pour relever ces défis, le domaine de l'apprentissage profond continuera sans aucun doute à progresser, apportant de nouvelles capacités et applications qui transformeront la façon dont nous vivons, travaillons et interagissons avec le monde qui nous entoure. Grâce à son immense potentiel, l'apprentissage profond est appelé à jouer un rôle de plus en plus important pour façonner l'avenir de l'intelligence artificielle et stimuler le progrès technologique dans divers domaines.


