
Che cos'è l'apprendimento profondo?



Che cos'è il Deep Learning?
Che cos'è l'apprendimento profondo? Il deep learning (DL) è un sottoinsieme dell'apprendimento automatico (ML) che si concentra principalmente sull'imitazione della capacità del cervello umano di apprendere ed elaborare informazioni. Nel mondo in rapida evoluzione dell'intelligenza artificiale (AI), l'apprendimento profondo è emerso come una tecnologia innovativa che sta avendo un impatto praticamente in ogni campo, dall'assistenza sanitaria alla...
Per ottenere questa capacità di apprendere ed elaborare le informazioni, l'apprendimento profondo si basa su una complessa rete di neuroni interconnessi chiamati reti neurali artificiali (RNA). Sfruttando la potenza delle RNA e la loro capacità di adattarsi e migliorare automaticamente nel tempo, gli algoritmi di apprendimento profondo possono scoprire schemi intricati, estrarre intuizioni significative e fare previsioni con notevole precisione.
*Prima di leggere questo blog sull'apprendimento profondo, assicuratevi di dare un'occhiata alla nostra spiegazione di AI e ML.
Gli elementi costitutivi dell'apprendimento profondo
Le fondamenta del deep learning si basano sul concetto di RNA, che si ispira alla struttura e al funzionamento del cervello umano. Le RNA sono costituite da vari strati di nodi o neuroni interconnessi, in cui ogni neurone elabora le informazioni e le trasmette allo strato successivo. Questi strati possono quindi imparare e adattarsi regolando i pesi delle connessioni tra i neuroni.
All'interno di una RNA ci sono neuroni artificiali, ognuno dei quali riceve un input da un altro prima di elaborare le informazioni e inviare l'output ai neuroni collegati. La forza delle connessioni tra i neuroni è nota come pesi, che determinano l'importanza di ciascun input nel calcolo complessivo.
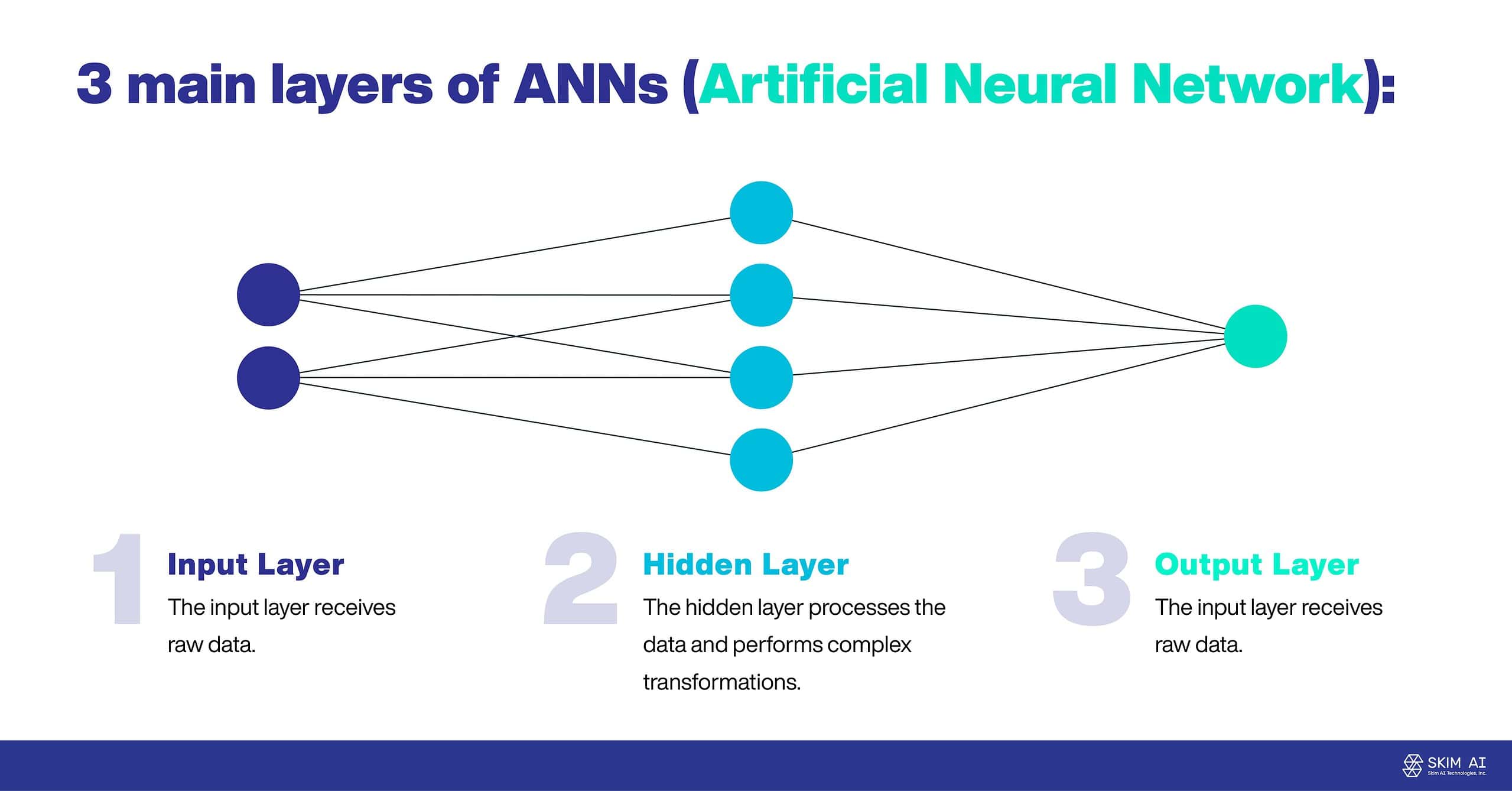
Le RNA sono spesso composte da tre strati principali:
Livello di ingresso: Il livello di ingresso riceve i dati grezzi.
Strato nascosto: Il livello nascosto elabora i dati ed esegue trasformazioni complesse.
Strato di uscita: Il livello di uscita produce il risultato finale.
Un altro importante elemento costitutivo delle RNA sono le funzioni di attivazione, che determinano l'uscita di ciascun neurone in base all'ingresso ricevuto. Queste funzioni introducono una non linearità nella rete, consentendole di apprendere modelli complessi e di eseguire calcoli intricati.
L'apprendimento profondo si basa sul processo di apprendimento, con la rete che regola i suoi pesi per minimizzare l'errore tra le sue previsioni e i risultati. Questo processo di apprendimento spesso comporta l'uso di una funzione di perdita, che quantifica la differenza tra l'output della rete e i valori reali.
I diversi tipi di architetture di apprendimento
Detto questo, il deep learning non segue un'unica architettura di apprendimento. Esistono alcuni tipi principali di architetture che vengono utilizzate per un'ampia gamma di problemi. Due delle più comuni sono le reti neurali convoluzionali (CNN) e le reti neurali ricorrenti (RNN). Tuttavia, ne esistono diverse altre, come LSTM, GRU e autoencoder.
Reti neurali convoluzionali (CNN)
Le CNN svolgono un ruolo fondamentale nelle attività di computer vision e di riconoscimento delle immagini. Prima dell'avvento delle CNN, questi compiti richiedevano tecniche di estrazione delle caratteristiche laboriose e lunghe per l'identificazione degli oggetti nelle immagini. Nel contesto del riconoscimento delle immagini, la funzione principale di una CNN è quella di trasformare le immagini in una forma più maneggevole, preservando le caratteristiche essenziali per una previsione accurata.
Le CNN spesso superano le altre reti neurali grazie alle loro eccezionali prestazioni con le immagini, i segnali audio o gli input vocali.
Per svolgere i loro compiti, impiegano tre tipi principali di strati:
Strato di convoluzione: Identifica le caratteristiche all'interno dei pixel.
Strato di pooling: Estrae le caratteristiche per un'ulteriore elaborazione.
Livello completamente connesso (FC): Utilizza le caratteristiche acquisite per la predizione.
Lo strato convoluzionale è il componente fondamentale di una CNN, dove avviene la maggior parte del calcolo. Questo livello è composto da dati di ingresso, un filtro e una mappa di caratteristiche. I livelli convoluzionali eseguono un'operazione di convoluzione sull'input prima di inviare il risultato al livello di pooling.
In un'attività di riconoscimento di immagini, questa convoluzione condensa tutti i pixel all'interno del suo campo recettivo in un unico valore. In termini più semplici, l'applicazione di una convoluzione a un'immagine ne riduce le dimensioni e combina tutte le informazioni all'interno del campo in un singolo pixel. Le caratteristiche di base, come i bordi orizzontali e diagonali, vengono estratte nel livello convoluzionale. L'output generato dal livello convoluzionale viene definito mappa delle caratteristiche.
Lo scopo principale del livello di pooling è quello di ridurre le dimensioni della mappa delle caratteristiche, diminuendo così il calcolo e le connessioni tra i livelli.
Il terzo strato di una CNN è lo strato FC, che collega i neuroni tra due strati distinti. Spesso posizionato prima dello strato di uscita, le immagini in ingresso dagli strati precedenti vengono appiattite. L'immagine appiattita passa in genere attraverso altri strati FC, dove le funzioni matematiche avviano il processo di classificazione.
Reti neurali ricorrenti (RNN)
Le reti neurali ricorrenti (RNN) rappresentano alcuni degli algoritmi più all'avanguardia sviluppati e sono utilizzate da tecnologie molto diffuse come Siri e la ricerca vocale di Google.
L'RNN è il primo algoritmo in grado di conservare il proprio input grazie alla memoria interna, il che lo rende prezioso per i problemi di apprendimento automatico che coinvolgono dati sequenziali come il parlato, il testo, i dati finanziari, l'audio e altro ancora. L'architettura unica delle RNN consente loro di catturare efficacemente le dipendenze e gli schemi all'interno delle sequenze, consentendo previsioni più accurate e prestazioni complessive migliori in un'ampia gamma di applicazioni.
La caratteristica distintiva di una RNN è la capacità di mantenere uno stato nascosto, che funziona come una memoria interna, consentendole di ricordare le informazioni dei passi temporali precedenti. Questa capacità di memoria consente alle RNN di apprendere e sfruttare le dipendenze a lungo raggio all'interno della sequenza di input, rendendole particolarmente efficaci per compiti come l'analisi delle serie temporali, l'NLP e il riconoscimento vocale.
La struttura di una RNN consiste in una serie di strati interconnessi, dove ogni strato è responsabile dell'elaborazione di un passo temporale della sequenza di input. L'input per ogni passo temporale è una combinazione del punto dati corrente e dello stato nascosto del passo temporale precedente. Queste informazioni vengono poi elaborate dallo strato RNN, che aggiorna lo stato nascosto e genera un'uscita. Lo stato nascosto agisce come una memoria, trasportando le informazioni dei passi temporali precedenti per influenzare l'elaborazione futura.
Le sfide dell'apprendimento profondo
Nonostante i notevoli successi del deep learning, rimangono diverse sfide e aree di ricerca future che meritano di essere esplorate ulteriormente per far progredire il campo e garantire una diffusione responsabile di queste tecnologie.
Interpretabilità e spiegabilità
Uno dei principali limiti dei modelli di deep learning è la loro natura di black-box, ovvero l'opacità e la complessità del loro funzionamento interno. Ciò rende difficile per i professionisti, gli utenti e le autorità di regolamentazione comprendere e interpretare il ragionamento alla base delle loro previsioni e decisioni. Tecniche di sviluppo per una migliore interpretabilità e spiegabilità è fondamentale per affrontare questi problemi e ha diverse implicazioni importanti.

Una maggiore interpretabilità e spiegabilità aiuterà gli utenti e le parti interessate a capire meglio come i modelli di deep learning arrivano alle loro previsioni o decisioni, favorendo così la fiducia nelle loro capacità e affidabilità. Ciò è particolarmente importante in applicazioni delicate come assistenza sanitariaLe decisioni dell'IA possono avere un impatto significativo sulla vita delle persone, in ambito finanziario e penale.
La capacità di interpretare e spiegare i modelli di deep learning può anche facilitare l'identificazione e la riduzione di potenziali distorsioni, errori o conseguenze indesiderate. Fornendo informazioni sul funzionamento interno dei modelli, i professionisti possono prendere decisioni informate sulla selezione, l'addestramento e l'impiego dei modelli, per garantire che i sistemi di IA siano utilizzati in modo responsabile ed etico.
La comprensione dei processi interni dei modelli di deep learning può aiutare i professionisti a identificare i problemi o gli errori che possono influire sulle loro prestazioni. Comprendendo i fattori che influenzano le previsioni di un modello, i professionisti possono mettere a punto l'architettura, i dati di addestramento o gli iperparametri per migliorare le prestazioni e l'accuratezza complessive.
Requisiti di dati e di calcolo per l'apprendimento profondo
L'apprendimento profondo è incredibilmente potente, ma questa potenza comporta requisiti significativi in termini di dati e di calcolo. Questi requisiti possono talvolta rappresentare una sfida per l'implementazione dell'apprendimento profondo.

Una delle sfide principali del deep learning è la necessità di disporre di grandi quantità di dati di addestramento etichettati. I modelli di apprendimento profondo spesso richiedono grandi quantità di dati per imparare e generalizzare in modo efficace. Questo perché questi modelli sono progettati per estrarre e apprendere automaticamente le caratteristiche dai dati grezzi e più dati hanno accesso, meglio possono identificare e catturare modelli e relazioni intricate.
Tuttavia, l'acquisizione e l'etichettatura di queste grandi quantità di dati può richiedere tempo, lavoro e costi elevati. In alcuni casi, i dati etichettati possono essere scarsi o difficili da ottenere, soprattutto in domini specializzati come l'imaging medico o le lingue rare. Per affrontare questa sfida, i ricercatori hanno esplorato varie tecniche come l'aumento dei dati, l'apprendimento per trasferimento e l'apprendimento non supervisionato o semi-supervisionato, che mirano a migliorare le prestazioni dei modelli con dati etichettati limitati.
I modelli di apprendimento profondo richiedono anche notevoli risorse computazionali per l'addestramento e l'inferenza. Questi modelli coinvolgono in genere un gran numero di parametri e livelli, che richiedono hardware potente e unità di elaborazione specializzate, come le GPU o le TPU, per eseguire i calcoli necessari in modo efficiente.
I requisiti computazionali dei modelli di deep learning possono essere proibitivi per alcune applicazioni o organizzazioni con risorse limitate, con conseguenti tempi di formazione più lunghi e costi più elevati. Per mitigare queste sfide, ricercatori e professionisti hanno studiato metodi per ottimizzare i modelli di deep learning e ridurre le dimensioni e la complessità del modello, pur mantenendone le prestazioni, in modo da ottenere tempi di formazione più rapidi e minori requisiti di risorse.
Robustezza e sicurezza
I modelli di apprendimento profondo hanno dimostrato prestazioni eccezionali in varie applicazioni; tuttavia, rimangono suscettibili di attacchi avversari. Questi attacchi comportano la creazione di campioni di input dannosi, deliberatamente progettati per ingannare il modello e generare previsioni o output errati. Affrontare queste vulnerabilità e migliorare la robustezza e la sicurezza dei modelli di deep learning contro gli esempi avversari e altri rischi potenziali è una sfida cruciale per la comunità dell'IA. Le conseguenze di tali attacchi possono essere di vasta portata, soprattutto in settori ad alta concentrazione come i veicoli autonomi, la sicurezza informatica e la sanità, dove l'integrità e l'affidabilità dei sistemi di IA sono fondamentali.
Gli attacchi avversari sfruttano la sensibilità dei modelli di deep learning a piccole e spesso impercettibili perturbazioni dei dati di input. Anche piccole alterazioni dei dati originali possono portare a previsioni o classificazioni drasticamente diverse, nonostante gli input appaiano virtualmente identici agli osservatori umani. Questo fenomeno solleva preoccupazioni circa la stabilità e l'affidabilità dei modelli di deep learning in scenari reali in cui gli avversari potrebbero manipolare gli input per compromettere le prestazioni del sistema.
Applicazioni del Deep Learning
L'apprendimento profondo ha dimostrato il suo potenziale di trasformazione in un'ampia gamma di applicazioni e settori. Alcune delle applicazioni più importanti includono:
- Riconoscimento delle immagini e visione artificiale: L'apprendimento profondo ha migliorato notevolmente l'accuratezza e l'efficienza delle attività di riconoscimento delle immagini e di computer vision. Le CNN, in particolare, hanno eccelso nella classificazione delle immagini, nel rilevamento degli oggetti e nella segmentazione. Questi progressi hanno aperto la strada ad applicazioni come il riconoscimento facciale, i veicoli autonomi e l'analisi delle immagini mediche.
- NLP: l'apprendimento profondo ha rivoluzionato l'elaborazione del linguaggio naturale, consentendo lo sviluppo di modelli linguistici e applicazioni più sofisticati. Diversi modelli sono stati impiegati per ottenere risultati all'avanguardia in attività come la traduzione automatica, l'analisi del sentiment, la sintesi di testi e i sistemi di risposta alle domande.
- Riconoscimento e generazione del parlato: L'apprendimento profondo ha fatto passi da gigante anche nel riconoscimento e nella generazione del parlato. Tecniche come le RNN e le CNN sono state utilizzate per sviluppare sistemi di riconoscimento automatico del parlato (ASR) più accurati ed efficienti, che convertono il linguaggio parlato in testo scritto. I modelli di apprendimento profondo hanno anche permesso una sintesi vocale di alta qualità, generando un parlato simile a quello umano a partire da un testo.
- Apprendimento per rinforzo: L'apprendimento profondo, quando combinato con l'apprendimento per rinforzo, ha portato allo sviluppo di apprendimento profondo per rinforzo (DRL) algoritmi. La DRL è stata utilizzata per addestrare agenti in grado di apprendere politiche ottimali per il processo decisionale e il controllo. Le applicazioni della DRL riguardano la robotica, la finanza e i giochi.
- Modelli generativi: Modelli generativi di deep learning, come Reti avversarie generative (GAN)hanno dimostrato un notevole potenziale nel generare campioni di dati realistici. Questi modelli sono stati utilizzati per compiti come la sintesi di immagini, il trasferimento di stile, l'aumento dei dati e il rilevamento di anomalie.
- Sanità: L'apprendimento profondo ha dato un contributo significativo anche all'assistenza sanitaria, rivoluzionando la diagnostica, la scoperta di farmaci e la medicina personalizzata. Ad esempio, gli algoritmi di deep learning sono stati utilizzati per analizzare le immagini mediche per la diagnosi precoce delle malattie, per prevedere gli esiti dei pazienti e per identificare potenziali candidati ai farmaci.
Rivoluzionando industrie e applicazioni
L'apprendimento profondo è emerso come una tecnologia innovativa con il potenziale di rivoluzionare un'ampia gamma di settori e applicazioni. L'apprendimento profondo sfrutta le reti neurali artificiali per imitare la capacità del cervello umano di apprendere ed elaborare le informazioni. Le CNN e le RNN sono due architetture di spicco che hanno consentito progressi significativi in campi quali il riconoscimento delle immagini, l'NLP, il riconoscimento vocale e l'assistenza sanitaria.
L'apprendimento profondo si trova ancora di fronte a sfide che devono essere affrontate per garantirne un utilizzo responsabile ed etico. Queste sfide includono il miglioramento dell'interpretabilità e della spiegabilità dei modelli di apprendimento profondo, la necessità di soddisfare i requisiti di dati e di calcolo e il miglioramento della robustezza e della sicurezza di questi modelli contro gli attacchi avversari.
Mentre ricercatori e professionisti continuano a esplorare e sviluppare tecniche innovative per affrontare queste sfide, il campo dell'apprendimento profondo continuerà senza dubbio a progredire, portando avanti nuove capacità e applicazioni che trasformeranno il modo in cui viviamo, lavoriamo e interagiamo con il mondo che ci circonda. Con il suo immenso potenziale, l'apprendimento profondo è destinato a svolgere un ruolo sempre più importante nel plasmare il futuro dell'intelligenza artificiale e nel guidare il progresso tecnologico in vari settori.


