
Les différents types d'apprentissage automatique



Les différents types d'apprentissage automatique
L'apprentissage automatique est un domaine qui évolue rapidement et qui a le potentiel de transformer de nombreux secteurs, des soins de santé à la finance en passant par la fabrication. L'apprentissage automatique repose sur quatre grands types de techniques d'apprentissage : apprentissage supervisé, apprentissage non supervisé, apprentissage semi-supervisé, et apprentissage par renforcement.
Chacune de ces approches a ses propres forces et faiblesses, et il est essentiel de comprendre comment elles fonctionnent pour réussir la mise en œuvre de solutions d'intelligence artificielle (IA).
*Avant de vous plonger dans ce blog sur l'apprentissage automatique, n'oubliez pas de consulter notre article sur l'IA et l'apprentissage automatique pour connaître la différence entre les deux.
Apprentissage supervisé

L'apprentissage supervisé est un type d'apprentissage automatique dans lequel l'algorithme est formé sur un ensemble de données étiquetées. Cela signifie que les données d'entrée ont déjà été classées ou étiquetées par des humains et que l'algorithme apprend à faire des prédictions sur la base de ces données étiquetées. Dans l'apprentissage supervisé, l'algorithme reçoit à la fois les données d'entrée et les données de sortie correspondantes, et il utilise ces informations pour apprendre une fonction de correspondance entre les deux.
L'une des applications les plus courantes de l'apprentissage supervisé est la classification. Dans la classification, l'algorithme est entraîné à prédire la catégorie à laquelle appartient un point de données d'entrée. Par exemple, un algorithme d'apprentissage supervisé peut être entraîné sur un ensemble de données d'images de chats et de chiens, chaque image étant étiquetée comme "chat" ou "chien". Une fois entraîné, l'algorithme peut alors prendre une nouvelle image et prédire s'il s'agit d'un chat ou d'un chien.
Une autre application courante de l'apprentissage supervisé est la régression. Dans la régression, l'algorithme est entraîné à prédire un résultat numérique continu sur la base des données d'entrée. Par exemple, un algorithme d'apprentissage supervisé pourrait être entraîné sur un ensemble de données relatives aux prix des maisons, chaque point de données comprenant des informations telles que la taille de la maison, le nombre de chambres et l'emplacement. L'algorithme apprendrait alors à prédire le prix d'une nouvelle maison sur la base de ces caractéristiques.
Apprentissage non supervisé

L'apprentissage non supervisé est un autre type courant d'apprentissage automatique où, contrairement à l'apprentissage supervisé, l'algorithme est formé sur un ensemble de données non étiquetées. Dans l'apprentissage non supervisé, l'algorithme ne reçoit aucune information sur la sortie ou les étiquettes des données d'entrée. Au lieu de cela, il apprend à identifier des modèles et des structures dans les données par lui-même.
L'une des applications les plus courantes de l'apprentissage non supervisé est le regroupement. Les algorithmes de clustering regroupent des points de données similaires sur la base de leurs caractéristiques, sans connaissance préalable des étiquettes des données. Cela peut être utile pour des tâches telles que la segmentation de la clientèle, lorsqu'une entreprise souhaite regrouper des clients en fonction de leurs habitudes d'achat ou d'autres comportements.
Une autre application de l'apprentissage non supervisé est la réduction de la dimensionnalité. Les algorithmes de réduction de la dimensionnalité sont utilisés pour réduire le nombre de caractéristiques dans un ensemble de données tout en préservant autant que possible les informations originales. Cela peut s'avérer utile pour des tâches telles que la reconnaissance d'images et de la parole, où les données d'entrée peuvent être hautement dimensionnelles et difficiles à traiter.
Apprentissage semi-supervisé

L'apprentissage semi-supervisé est une combinaison de techniques d'apprentissage supervisé et non supervisé. L'algorithme est formé sur un ensemble de données qui contient à la fois des données étiquetées et non étiquetées.
Les données étiquetées sont utilisées pour former l'algorithme de manière supervisée, tandis que les données non étiquetées sont utilisées pour aider l'algorithme à en apprendre davantage sur la structure sous-jacente des données. L'idée derrière l'apprentissage semi-supervisé est que les données non marquées peuvent être utilisées pour améliorer la précision et la capacité de généralisation de l'algorithme.
L'apprentissage semi-supervisé est souvent utilisé dans le traitement du langage naturel (NLP), un domaine de l'informatique et de l'intelligence artificielle qui vise à permettre aux machines de comprendre le langage écrit et parlé de la même manière que les humains. Les modèles de langage sont généralement formés sur de grandes quantités de données textuelles non étiquetées, qui peuvent être utilisées pour améliorer la précision de tâches telles que la classification de textes et la traduction.
L'apprentissage semi-supervisé peut également être utilisé pour des tâches telles que la reconnaissance d'images et de la parole, où la quantité de données étiquetées peut être limitée ou coûteuse à obtenir. En exploitant les données non étiquetées disponibles, l'algorithme peut améliorer ses performances pour la tâche en question.
Apprentissage par renforcement
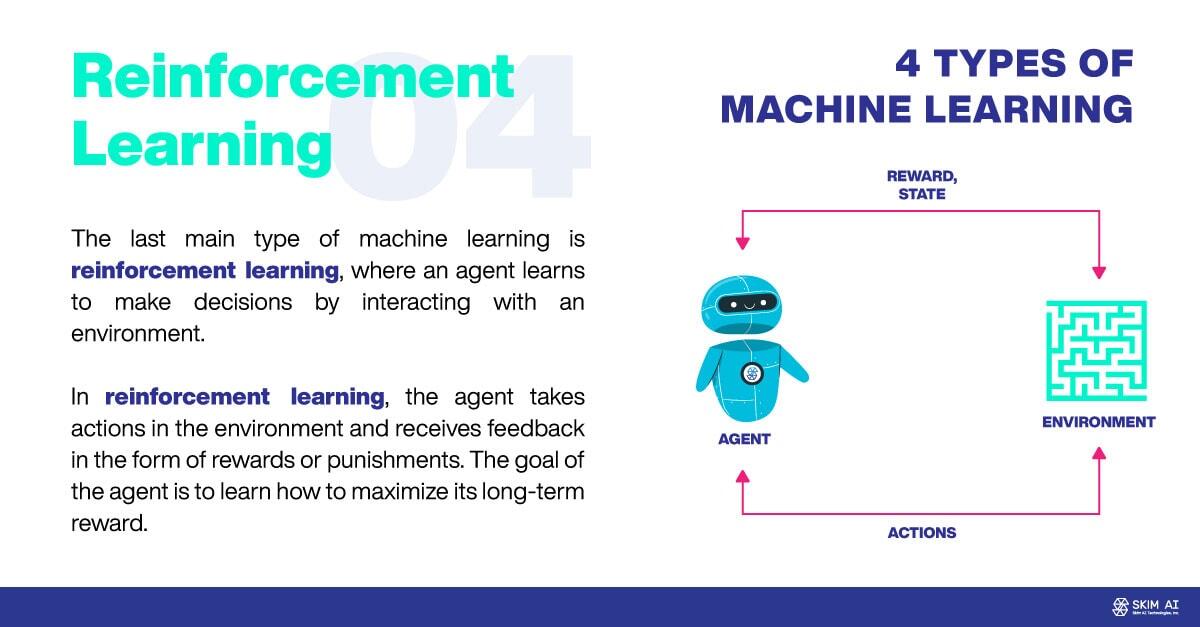
Le dernier grand type d'apprentissage automatique est l'apprentissage par renforcement, dans lequel un agent apprend à prendre des décisions en interagissant avec un environnement. Dans l'apprentissage par renforcement, l'agent entreprend des actions dans l'environnement et reçoit un retour d'information sous forme de récompenses ou de punitions. L'objectif de l'agent est d'apprendre à maximiser sa récompense à long terme.
Les applications les plus importantes de l'apprentissage par renforcement se trouvent dans le domaine de la robotique, où un agent peut apprendre à contrôler un robot physique pour qu'il effectue une tâche. L'agent agit dans l'environnement, par exemple en bougeant les bras ou les jambes du robot, et reçoit un retour d'information sous la forme d'une récompense ou d'une pénalité en fonction de la manière dont il exécute la tâche.
L'apprentissage par renforcement peut également être utilisé pour les jeux et les simulations, où un agent peut apprendre à jouer à un jeu ou à naviguer dans un environnement virtuel. Par exemple, l'apprentissage par renforcement a été utilisé pour former des agents à jouer à des jeux vidéo tels que les jeux Atari et le jeu de Go.
Un autre domaine dans lequel l'apprentissage par renforcement s'est avéré prometteur est celui des soins de santé, où il peut être utilisé pour optimiser les traitements de diverses maladies. L'agent peut apprendre à prendre des décisions de traitement sur la base des données du patient et recevoir un retour d'information sous la forme de résultats pour le patient.
Transformer les industries
L'apprentissage automatique est un domaine qui évolue rapidement et qui a le potentiel de transformer presque tous les secteurs et de résoudre certains de nos problèmes les plus complexes. Comprendre les différents types d'apprentissage automatique, tels que l'apprentissage supervisé, non supervisé, semi-supervisé et par renforcement, nous permet de continuer à repousser les limites et d'avoir un impact sur notre monde dominé par les données.


