
Different Types of Machine Learning



Different Types of Machine Learning
Machine learning is a rapidly evolving field that has the potential to transform many industries, from healthcare to finance to manufacturing. At the core of machine learning are four main types of learning techniques: supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning.
Each of these approaches has its own strengths and weaknesses, and understanding how they work is crucial for the successful implementation of artificial intelligence (AI) solutions.
*Before diving into this blog on machine learning, make sure to check out our piece on AI vs. ML to learn the difference between the two.
Supervised Learning

Supervised learning is a type of machine learning where the algorithm is trained on a labeled dataset. This means that the input data has already been classified or labeled by humans, and the algorithm learns to make predictions based on this labeled data. In supervised learning, the algorithm is given both the input data and the corresponding output data, and it uses this information to learn a mapping function between the two.
One of the most common applications of supervised learning is classification. In classification, the algorithm is trained to predict which category an input data point belongs to. For example, a supervised learning algorithm could be trained on a dataset of images of cats and dogs, with each image labeled as either “cat” or “dog”. Once trained, the algorithm can then take in a new image and predict whether it is a cat or a dog.
Another common application of supervised learning is regression. In regression, the algorithm is trained to predict a continuous numerical output based on the input data. For example, a supervised learning algorithm could be trained on a dataset of house prices, with each data point including information such as the size of the house, the number of bedrooms, and the location. The algorithm would then learn to predict the price of a new house based on these features.
Unsupervised Learning

Unsupervised learning is another common type of machine learning where, unlike supervised learning, the algorithm is trained on an unlabeled dataset. In unsupervised learning, the algorithm is not given any information about the output or labels of the input data. Instead, it learns to identify patterns and structures in the data on its own.
One of the most common applications of unsupervised learning is clustering. Clustering algorithms group similar data points together based on their features, without any prior knowledge of the data labels. This can be useful for tasks such as customer segmentation, where a company may want to group customers based on their purchasing habits or other behaviors.
Another application of unsupervised learning is dimensionality reduction. Dimensionality reduction algorithms are used to reduce the number of features in a dataset while preserving as much of the original information as possible. This can be useful for tasks such as image and speech recognition, where the input data may be high-dimensional and difficult to process.
Semi-Supervised Learning

When it comes to semi-supervised learning, it is a combination of both supervised and unsupervised learning techniques. The algorithm is trained on a dataset that contains both labeled and unlabeled data.
The labeled data is used to train the algorithm in a supervised manner, while the unlabeled data is used to help the algorithm learn more about the underlying structure of the data. The idea behind semi-supervised learning is that the unlabeled data can be used to improve the accuracy and generalization ability of the algorithm.
Semi-supervised learning is often used in natural language processing (NLP), which is a field of computer science and AI that focuses on enabling machines to comprehend written and spoken language similar to how humans do. Language models are typically trained on large amounts of unlabeled text data, which can be used to improve the accuracy of tasks such as text classification and language translation.
Semi-supervised learning can also be used for tasks such as image and speech recognition, where the amount of labeled data may be limited or expensive to obtain. By leveraging the available unlabeled data, the algorithm can improve its performance on the task at hand.
Reinforcement Learning
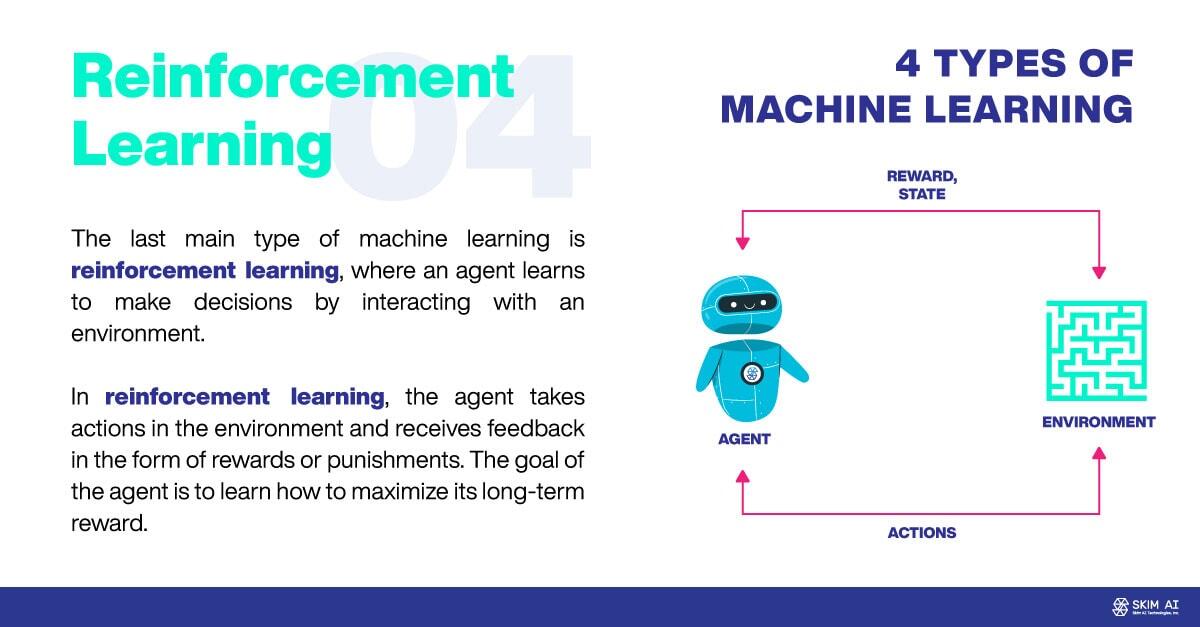
The last main type of machine learning is reinforcement learning, where an agent learns to make decisions by interacting with an environment. In reinforcement learning, the agent takes actions in the environment and receives feedback in the form of rewards or punishments. The goal of the agent is to learn how to maximize its long-term reward.
The biggest applications of reinforcement learning are in the field of robotics, where an agent can learn to control a physical robot to perform a task. The agent takes actions in the environment, such as moving the robot’s arms or legs, and receives feedback in the form of a reward or penalty based on how well it performs the task.
Reinforcement learning can also be used for games and simulations, where an agent can learn to play a game or navigate a virtual environment. For example, reinforcement learning has been used to train agents to play video games such as Atari games and the game of Go.
Another area where reinforcement learning has shown promise is in healthcare, where it can be used to optimize treatments for various diseases. The agent can learn to make treatment decisions based on patient data and receive feedback in the form of patient outcomes.
Transforming Industries
Machine learning is a rapidly evolving field that has the potential to transform nearly any industry and solve some of our most complex problems. Understanding the different types of machine learning, such as supervised, unsupervised, semi-supervised, and reinforcement learning allows us to continue pushing boundaries and make an impact on our data-driven world.


