
Diferentes tipos de aprendizaje automático



Diferentes tipos de aprendizaje automático
El aprendizaje automático es un campo en rápida evolución que puede transformar muchos sectores, desde la sanidad a las finanzas, pasando por la fabricación. En el núcleo del aprendizaje automático hay cuatro tipos principales de técnicas de aprendizaje: aprendizaje supervisado, aprendizaje no supervisado, aprendizaje semisupervisado, y aprendizaje por refuerzo.
Cada uno de estos enfoques tiene sus propios puntos fuertes y débiles, y entender cómo funcionan es crucial para implantar con éxito soluciones de inteligencia artificial (IA).
*Antes de sumergirse en este blog sobre aprendizaje automático, asegúrese de consultar nuestro artículo sobre IA frente a ML para conocer la diferencia entre ambos.
Aprendizaje supervisado

El aprendizaje supervisado es un tipo de aprendizaje automático en el que el algoritmo se entrena con un conjunto de datos etiquetados. Esto significa que los datos de entrada ya han sido clasificados o etiquetados por humanos, y el algoritmo aprende a hacer predicciones basándose en estos datos etiquetados. En el aprendizaje supervisado, el algoritmo recibe tanto los datos de entrada como los datos de salida correspondientes, y utiliza esta información para aprender una función de asignación entre ambos.
Una de las aplicaciones más comunes del aprendizaje supervisado es la clasificación. En la clasificación, el algoritmo se entrena para predecir a qué categoría pertenece un punto de datos de entrada. Por ejemplo, un algoritmo de aprendizaje supervisado podría entrenarse en un conjunto de datos de imágenes de gatos y perros, etiquetando cada imagen como "gato" o "perro". Una vez entrenado, el algoritmo puede tomar una nueva imagen y predecir si es un gato o un perro.
Otra aplicación común del aprendizaje supervisado es la regresión. En la regresión, el algoritmo se entrena para predecir un resultado numérico continuo basado en los datos de entrada. Por ejemplo, un algoritmo de aprendizaje supervisado podría entrenarse en un conjunto de datos de precios de viviendas, con cada punto de datos incluyendo información como el tamaño de la casa, el número de dormitorios y la ubicación. El algoritmo aprendería entonces a predecir el precio de una casa nueva basándose en estas características.
Aprendizaje no supervisado

El aprendizaje no supervisado es otro tipo común de aprendizaje automático en el que, a diferencia del aprendizaje supervisado, el algoritmo se entrena en un conjunto de datos no etiquetados. En el aprendizaje no supervisado, el algoritmo no recibe ninguna información sobre la salida o las etiquetas de los datos de entrada. En su lugar, aprende a identificar patrones y estructuras en los datos por sí mismo.
Una de las aplicaciones más comunes del aprendizaje no supervisado es la agrupación. Los algoritmos de clustering agrupan puntos de datos similares basándose en sus características, sin ningún conocimiento previo de las etiquetas de los datos. Esto puede ser útil para tareas como la segmentación de clientes, en la que una empresa puede querer agrupar a los clientes en función de sus hábitos de compra u otros comportamientos.
Otra aplicación del aprendizaje no supervisado es la reducción de la dimensionalidad. Los algoritmos de reducción de la dimensionalidad se utilizan para reducir el número de características de un conjunto de datos conservando la mayor parte posible de la información original. Esto puede ser útil para tareas como el reconocimiento de imágenes y del habla, en las que los datos de entrada pueden tener muchas dimensiones y ser difíciles de procesar.
Aprendizaje semisupervisado

El aprendizaje semisupervisado es una combinación de técnicas de aprendizaje supervisado y no supervisado. El algoritmo se entrena con un conjunto de datos etiquetados y no etiquetados.
Los datos etiquetados se utilizan para entrenar el algoritmo de forma supervisada, mientras que los datos no etiquetados se utilizan para ayudar al algoritmo a aprender más sobre la estructura subyacente de los datos. La idea que subyace al aprendizaje semisupervisado es que los datos no etiquetados pueden utilizarse para mejorar la precisión y la capacidad de generalización del algoritmo.
El aprendizaje semisupervisado se utiliza a menudo en el procesamiento del lenguaje natural (PLN), un campo de la informática y la IA que se centra en capacitar a las máquinas para comprender el lenguaje escrito y hablado de forma similar a como lo hacen los humanos. Los modelos lingüísticos suelen entrenarse con grandes cantidades de datos de texto sin etiquetar, que pueden utilizarse para mejorar la precisión de tareas como la clasificación de textos y la traducción de idiomas.
El aprendizaje semisupervisado también puede utilizarse para tareas como el reconocimiento de imágenes y del habla, en las que la cantidad de datos etiquetados puede ser limitada o costosa de obtener. Al aprovechar los datos no etiquetados disponibles, el algoritmo puede mejorar su rendimiento en la tarea en cuestión.
Aprendizaje por refuerzo
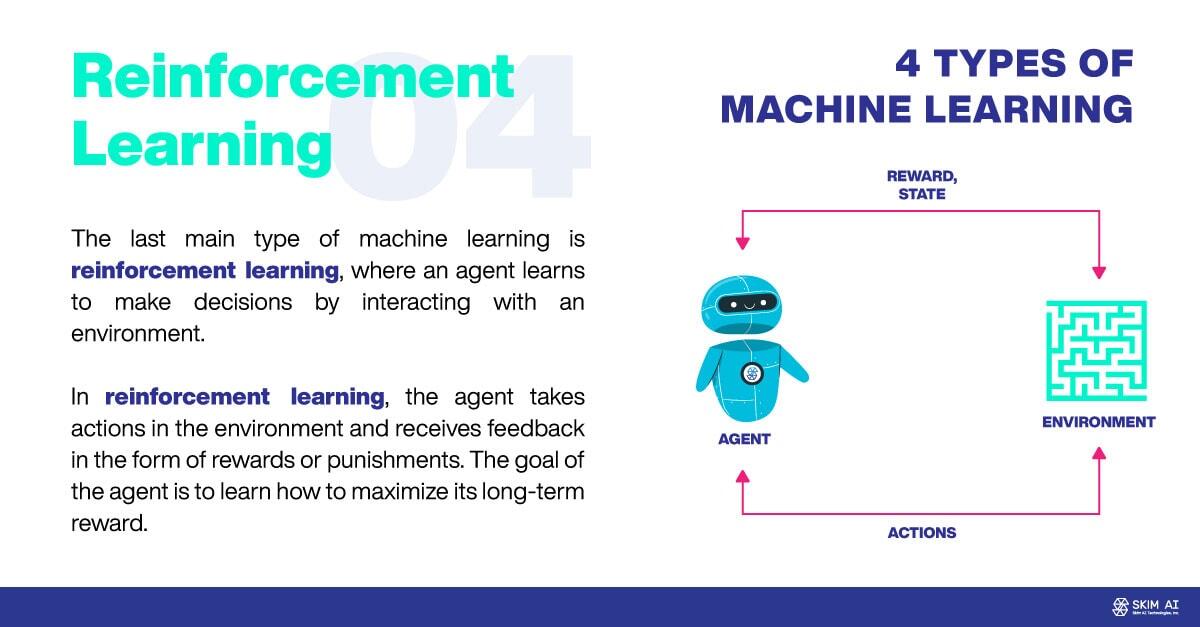
El último tipo principal de aprendizaje automático es el aprendizaje por refuerzo, en el que un agente aprende a tomar decisiones interactuando con un entorno. En el aprendizaje por refuerzo, el agente realiza acciones en el entorno y recibe retroalimentación en forma de recompensas o castigos. El objetivo del agente es aprender a maximizar su recompensa a largo plazo.
Las mayores aplicaciones del aprendizaje por refuerzo se encuentran en el campo de la robótica, donde un agente puede aprender a controlar un robot físico para que realice una tarea. El agente realiza acciones en el entorno, como mover los brazos o las piernas del robot, y recibe información en forma de recompensa o penalización en función de lo bien que realice la tarea.
El aprendizaje por refuerzo también puede utilizarse para juegos y simulaciones, donde un agente puede aprender a jugar a un juego o a navegar por un entorno virtual. Por ejemplo, el aprendizaje por refuerzo se ha utilizado para entrenar a agentes a jugar a videojuegos como los de Atari y el juego del Go.
Otro campo en el que el aprendizaje por refuerzo se ha mostrado prometedor es el de la asistencia sanitaria, donde puede utilizarse para optimizar los tratamientos de diversas enfermedades. El agente puede aprender a tomar decisiones sobre el tratamiento basándose en los datos del paciente y recibir información en forma de resultados.
Transformar las industrias
El aprendizaje automático es un campo en rápida evolución que tiene el potencial de transformar casi cualquier sector y resolver algunos de nuestros problemas más complejos. Comprender los distintos tipos de aprendizaje automático, como el supervisado, el no supervisado, el semisupervisado y el aprendizaje por refuerzo, nos permite seguir superando los límites y tener un impacto en nuestro mundo basado en los datos.


