
Tutorial: How to Fine-Tune BERT for Extractive Summarization



Tutorial: How to Fine-Tune BERT for Extractive Summarization
Originally published by Skim AI's Machine Learning Researcher, Chris Tran![]()
1. Introduction
Summarization has long been a challenge in Natural Language Processing. To generate a short version of a document while retaining its most important information, we need a model capable of accurately extracting the key points while avoiding repetitive information. Fortunately, recent works in NLP such as Transformer models and language model pretraining have advanced the state-of-the-art in summarization.
In this article, we will explore BERTSUM, a simple variant of BERT, for extractive summarization from Text Summarization with Pretrained Encoders (Liu et al., 2019). Then, in an effort to make extractive summarization even faster and smaller for low-resource devices, we will fine-tune DistilBERT (Sanh et al., 2019) and MobileBERT (Sun et al., 2019), two recent lite versions of BERT, and discuss our findings.
2. Extractive Summarization
There are two types of summarization: abstractive and extractive summarization. Abstractive summarization basically means rewriting key points while extractive summarization generates summary by copying directly the most important spans/sentences from a document.
Abstractive summarization is more challenging for humans, and also more computationally expensive for machines. However, which summaration is better depends on the purpose of the end user. If you were writing an essay, abstractive summaration might be a better choice. On the other hand, if you were doing some research and needed to get a quick summary of what you were reading, extractive summarization would be more helpful for the task.
In this section we will explore the architecture of our extractive summarization model. The BERT summarizer has 2 parts: a BERT encoder and a summarization classifier.
BERT Encoder

The overview architecture of BERTSUM
Our BERT encoder is the pretrained BERT-base encoder from the masked language modeling task (Devlin et at., 2018). The task of extractive summarization is a binary classification problem at the sentence level. We want to assign each sentence a label $y_i in {0, 1}$ indicating whether the sentence should be included in the final summary. Therefore, we need to add a token [CLS] before each sentence. After we run a forward pass through the encoder, the last hidden layer of these [CLS] tokens will be used as the representions for our sentences.
Summarization Classifier
After getting the vector representation of each sentence, we can use a simple feed forward layer as our classifier to return a score for each sentence. In the paper, the author experimented with a simple linear classifier, a Recurrent Neural Network and a small Transformer model with 3 layers. The Transformer classifier yields the best results, showing that inter-sentence interactions through self-attention mechanism is important in selecting the most important sentences.
So in the encoder, we learn the interactions among tokens in our document while in the summarization classifier, we learn the interactions among sentences.
3. Make Summarization Even Faster
Transformer models achieve state-of-the-art performance in most NLP bechmarks; however, training and making predictions from them are computationally expensive. In an effort to make summarization lighter and faster to be deployed on low-resource devices, I have modified the source codes provided by the authors of BERTSUM to replace the BERT encoder with DistilBERT and MobileBERT. The summary layers are kept unchaged.
Here are training losses of these 3 variants: TensorBoard

Despite being 40% smaller than BERT-base, DistilBERT has the same training losses as BERT-base while MobileBERT performs slightly worse. The table below shows their performance on CNN/DailyMail dataset, size and running time of a forward pass:
| Models | ROUGE-1 | ROUGE-2 | ROUGE-L | Inference Time* | Size | Params |
|---|---|---|---|---|---|---|
| bert-base | 43.23 | 20.24 | 39.63 | 1.65 s | 475 MB | 120.5 M |
| distilbert | 42.84 | 20.04 | 39.31 | 925 ms | 310 MB | 77.4 M |
| mobilebert | 40.59 | 17.98 | 36.99 | 609 ms | 128 MB | 30.8 M |
*Average running time of a forward pass on a single GPU on a standard Google Colab notebook
Being 45% faster, DistilBERT have almost the same performance as BERT-base. MobileBERT retains 94% performance of BERT-base, while being 4x smaller than BERT-base and 2.5x smaller than DistilBERT. In the MobileBERT paper, it’s shown that MobileBERT significantly outperforms DistilBERT on SQuAD v1.1. However, it’s not the case for extractive summarization. But this is still an impressive result for MobileBERT with a disk size of only 128 MB.
4. Let’s Summarize
All pretrained checkpoints, training details and setup instruction can be found in this GitHub repository. In addition, I have deployed a demo of BERTSUM with the MobileBERT encoder.
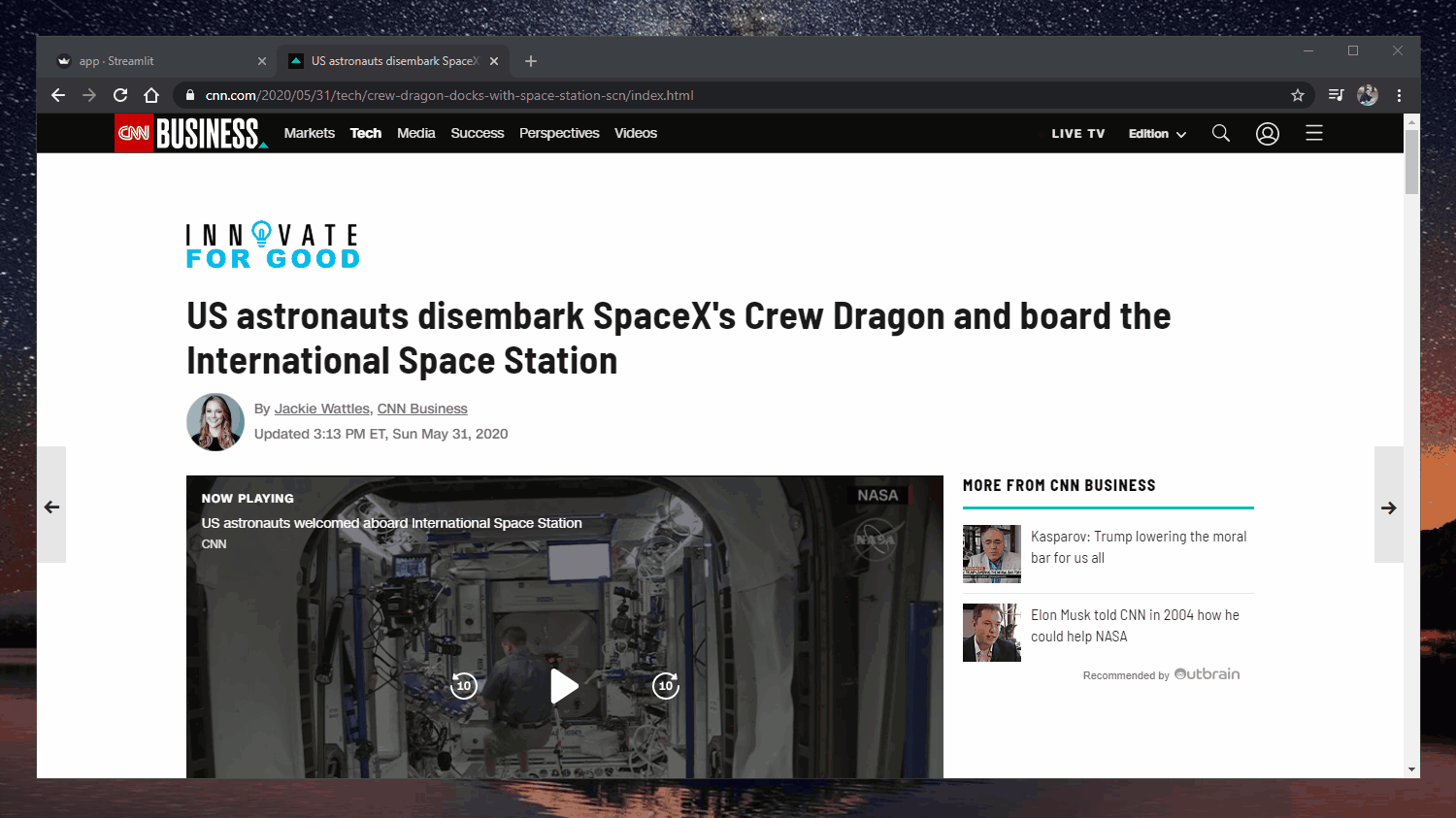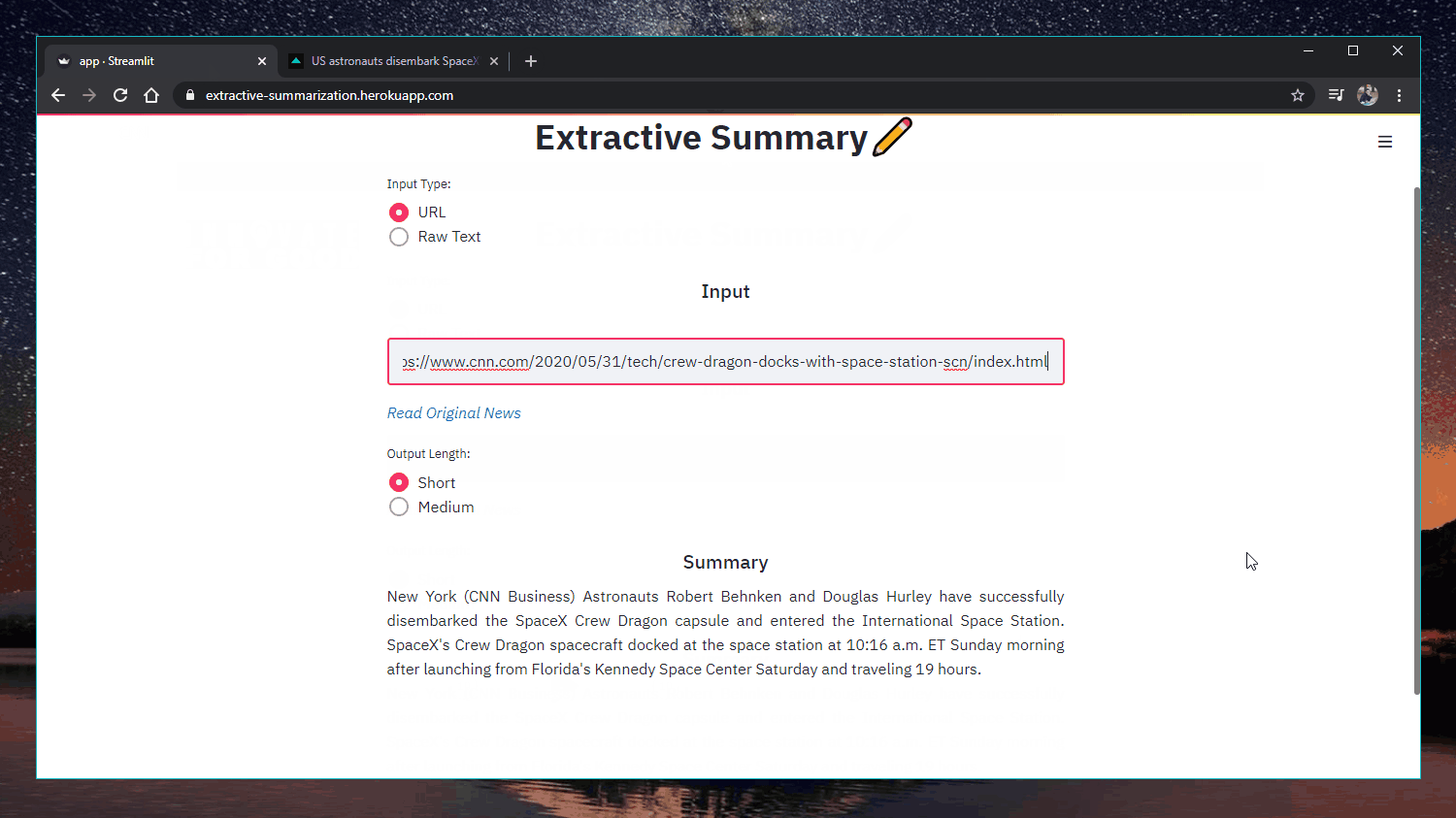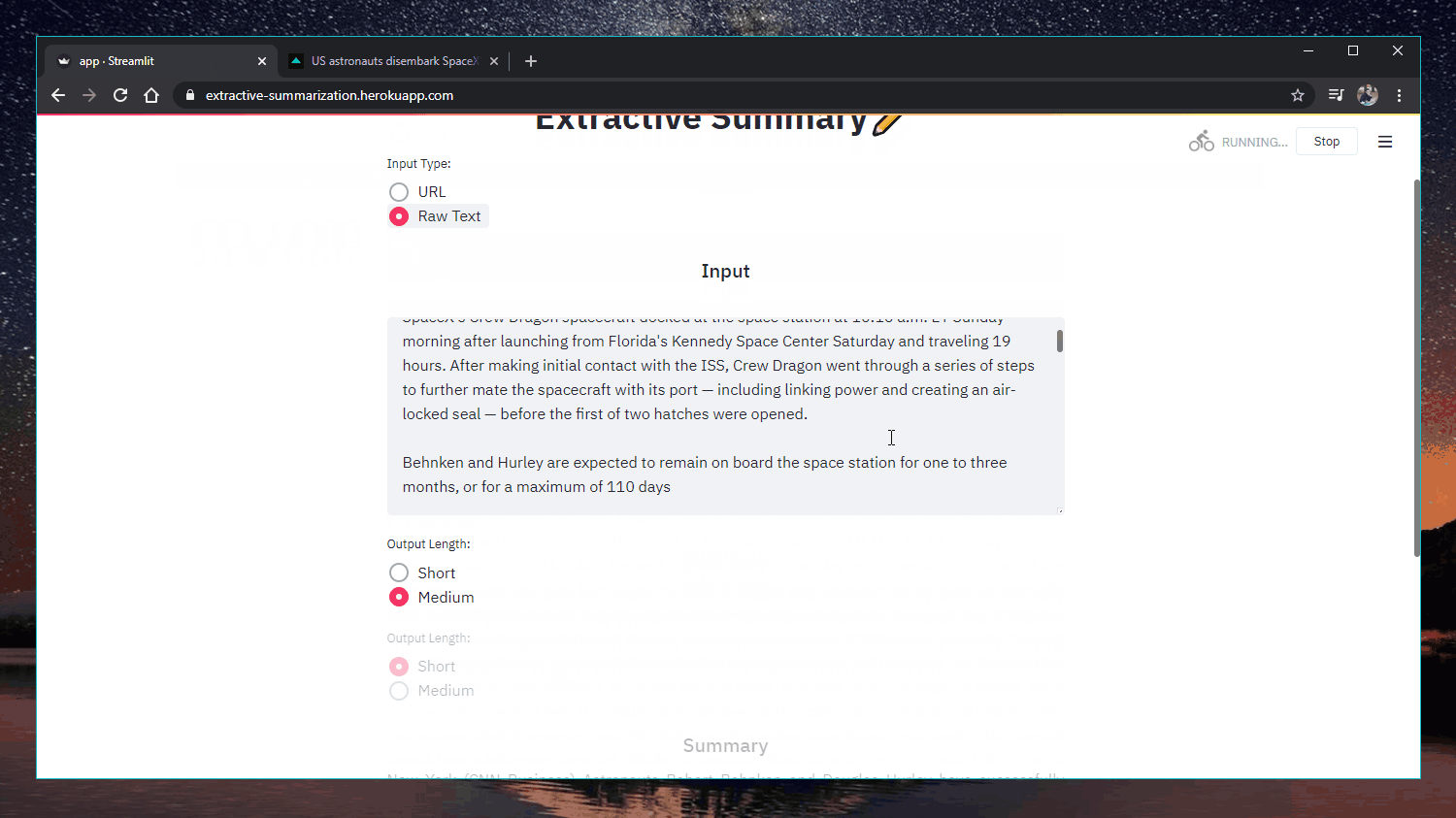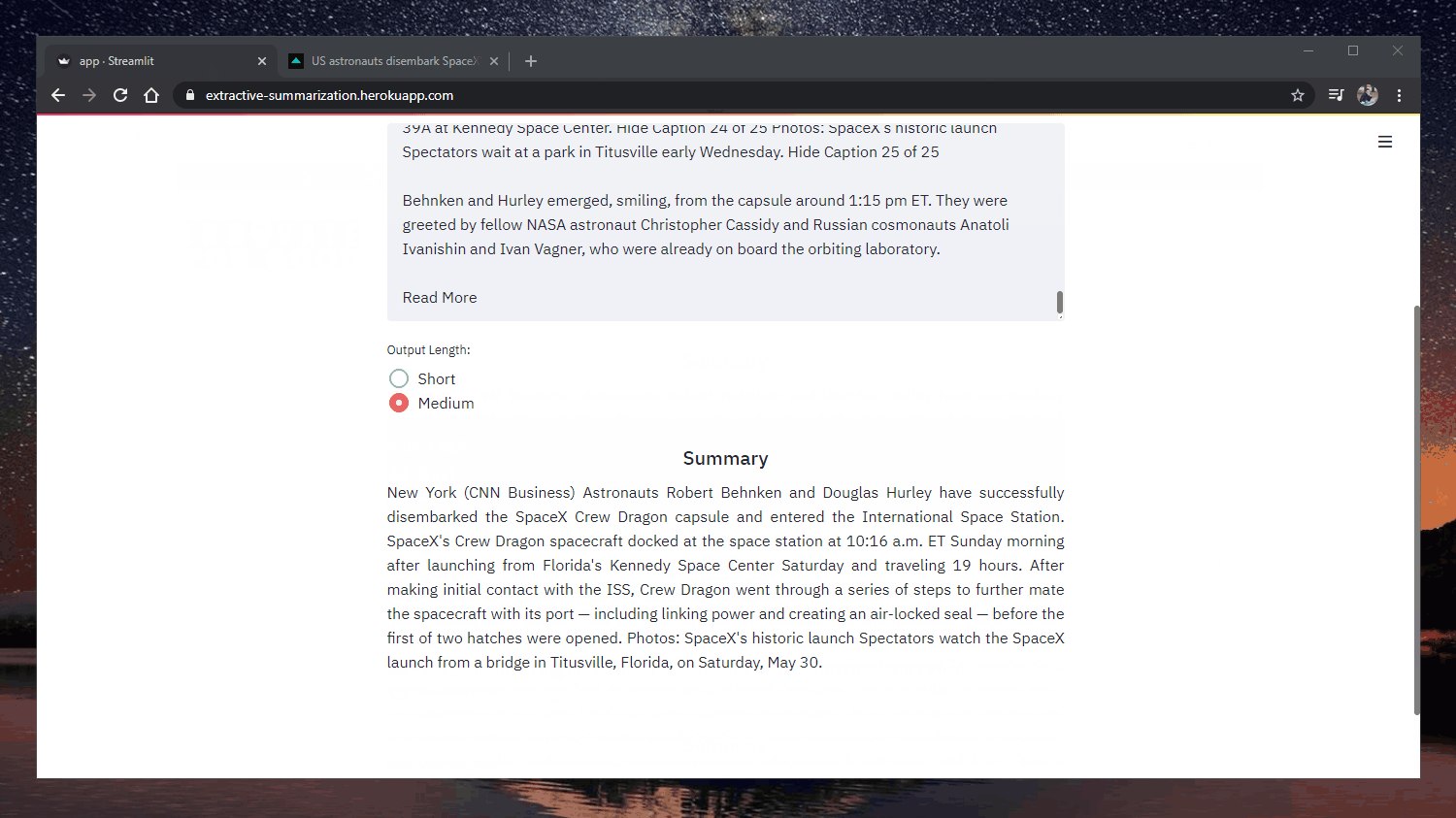
Web app: https://extractive-summarization.herokuapp.com/
![]()
Code:
![]()
import torch
from models.model_builder import ExtSummarizer
from ext_sum import summarize
# Load model
model_type = 'mobilebert' #@param ['bertbase', 'distilbert', 'mobilebert']
checkpoint = torch.load(f'checkpoints/{model_type}_ext.pt', map_location='cpu')
model = ExtSummarizer(checkpoint=checkpoint, bert_type=model_type, device='cpu')
# Run summarization
input_fp = 'raw_data/input.txt'
result_fp = 'results/summary.txt'
summary = summarize(input_fp, result_fp, model, max_length=3)
print(summary)
Summary sample
Original: https://www.cnn.com/2020/05/22/business/hertz-bankruptcy/index.html
By declaring bankruptcy, Hertz says it intends to stay in business while restructuring its debts and emerging a
financially healthier company. The company has been renting cars since 1918, when it set up shop with a dozen
Ford Model Ts, and has survived the Great Depression, the virtual halt of US auto production during World War II
and numerous oil price shocks. "The impact of Covid-19 on travel demand was sudden and dramatic, causing an
abrupt decline in the company's revenue and future bookings," said the company's statement.
5. Conclusion
In this article, we have explored BERTSUM, a simple variant of BERT, for extractive summarization from the paper Text Summarization with Pretrained Encoders (Liu et al., 2019). Then, in an effort to make extractive summarization even faster and smaller for low-resource devices, we fine-tuned DistilBERT (Sanh et al., 2019) and MobileBERT (Sun et al., 2019) on CNN/DailyMail datasets.
DistilBERT retains BERT-base’s performance in extractive summarization while being 45% smaller. MobileBERT is 4x smaller and 2.7x faster than BERT-base yet retains 94% of its performance.
Finally, we deployed a web app demo of MobileBERT for extractive summarization at https://extractive-summarization.herokuapp.com/.


