
Top 5 Multimodal AI Tools and Plaforms



The landscape of artificial intelligence is constantly evolving, with multimodal AI tools and platforms emerging as significant players. These innovative solutions go beyond traditional single-mode AI by integrating various types of data – such as text, images, speech, and video – to create more intelligent, efficient, and intuitive systems. This integration allows for a more comprehensive understanding and interaction with data, closely mirroring the multifaceted way humans perceive and process information.
In this blog, we will explore some of the top multimodal AI tools and platforms that are making waves in the tech world. These platforms are not just revolutionizing how machines learn and interact with data, but also how businesses and individuals leverage AI for more complex and accurate applications.
1. Runway Gen-2
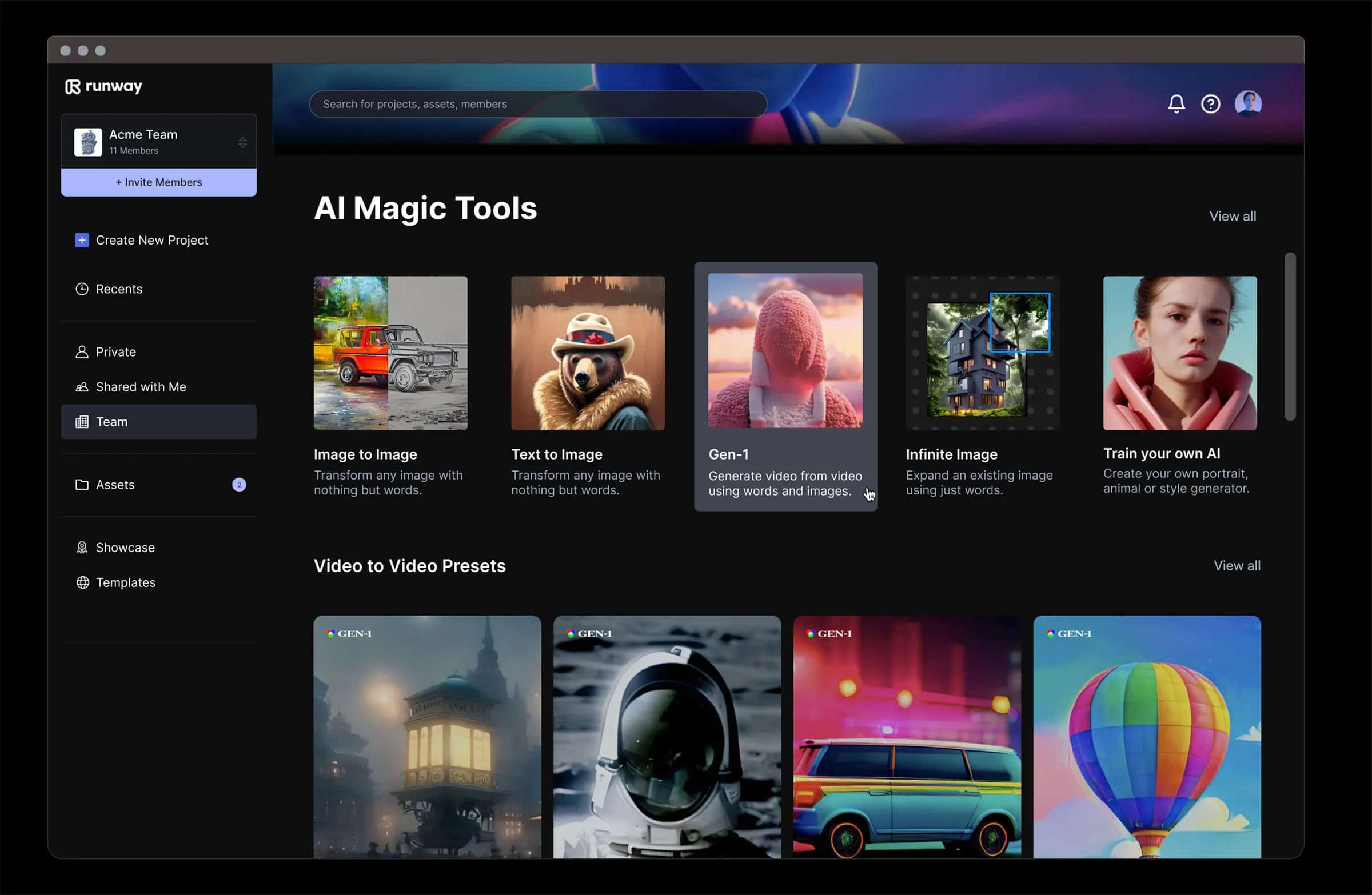
Runway Gen-2, developed by Runway, marks a significant evolution in the realm of generative AI, particularly in video and image synthesis. This tool demonstrates the power of multimodal AI by allowing users to generate novel videos using a mix of text, images, or video clips. Runway Gen-2 enables you to craft precise, realistic, and controllable multimedia outputs that push the boundaries of digital creativity.
The latest Gen-2 updates are particularly noteworthy for their major advancements in the fidelity and consistency of the videos they produce. This leap in quality has turned heads in the AI community, with users labeling it as a pivotal moment in the evolution of generative AI. The tool’s ability to generate full-scale videos from simple text prompts, images, or existing videos is a groundbreaking feature, offering new possibilities in storytelling and digital media. Such capabilities have led to comparisons with the invention of the camera, suggesting that AI is becoming a new medium for capturing and creating visual narratives.
Key features of Runway Gen-2 include:
The ability to generate bespoke video and image creations.
Easy downloading of generated content for various uses.
Accessibility on both Runway’s web and mobile platforms, offering versatility and convenience.
A design that keeps users at the forefront of developments in generative AI, ensuring constant innovation.
Runway Gen-2 is ushering in a new era in digital media, where storytelling, creativity, and AI converge to open up unimaginable avenues in content creation.
2. ImageBind by Meta AI
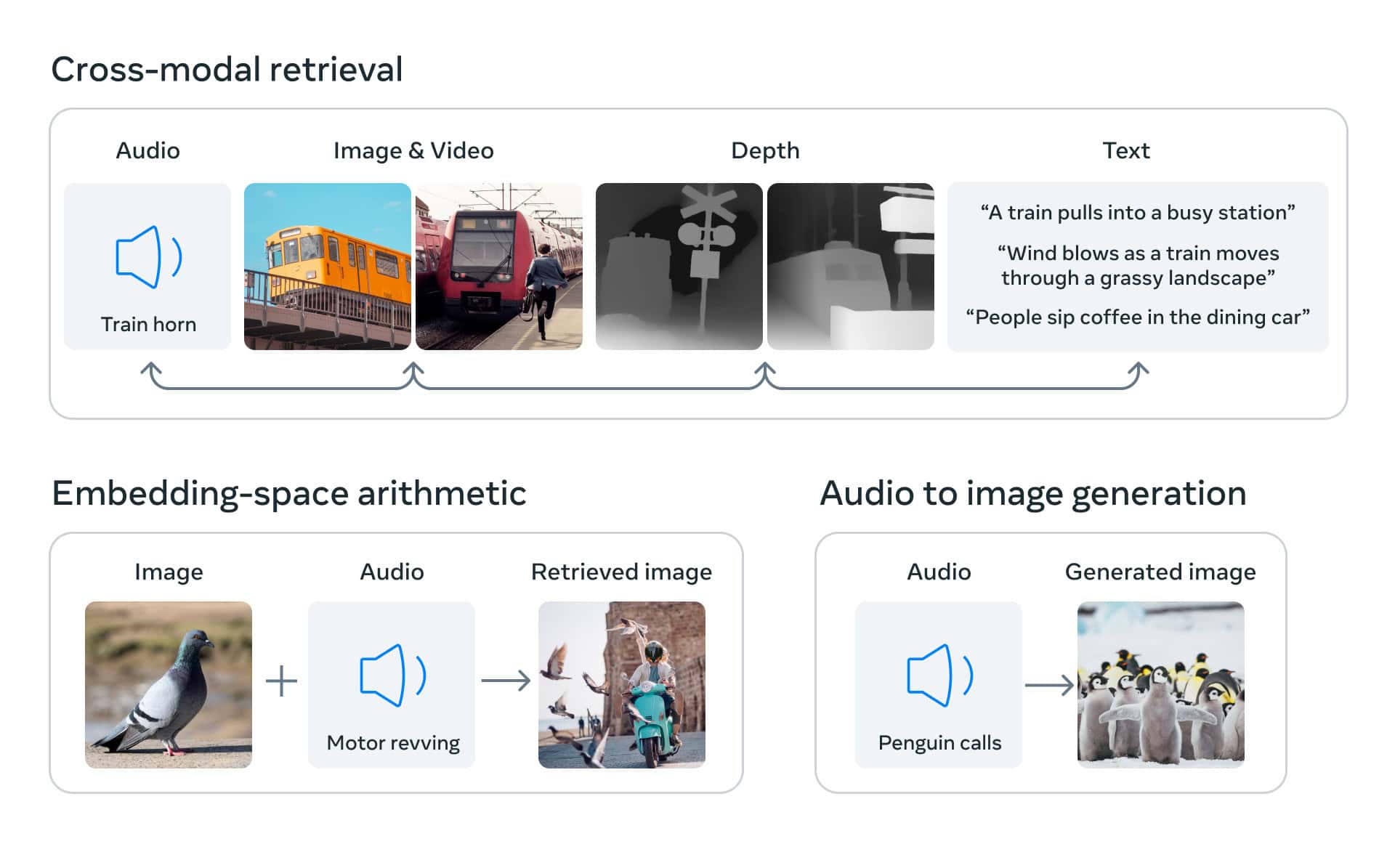
ImageBind, developed by Meta AI, is at the forefront of multimodal AI innovation, representing a significant leap in the integration and interpretation of diverse data types. This trailblazing model uniquely combines information from six different modalities: images, text, audio, depth, thermal, and IMU data. This integration facilitates a joint embedding of these varied data types, creating unprecedented opportunities for cross-modal retrieval, arithmetic composition of modalities, detection, and generation.
The essence of ImageBind’s innovation lies in its extension of large-scale vision-language models. It enhances these models’ zero-shot capabilities, allowing them to seamlessly adapt to new modalities. This feature enables the development of novel applications right out of the box, significantly expanding the potential use-cases for AI systems. ImageBind has showcased superior performance in emergent zero-shot recognition tasks across these modalities and has established new benchmarks in the domain of few-shot recognition.
ImageBind’s development is a part of Meta’s broader efforts to create multimodal AI systems that learn from a variety of data types. Its ability to combine six different forms of data into a single embedding space is unprecedented. This capability not only mimics human perception more closely but also enables machines to analyze different forms of information together more effectively.
Key features of ImageBind include:
Integration of six modalities (images, text, audio, depth, thermal, IMU) into a single model.
Enhanced zero-shot capabilities, extending the functionality of vision-language models.
Superior performance in zero-shot and few-shot recognition tasks.
Open-source availability, contributing to advancements in the field of multimodal AI.
With its groundbreaking approach, ImageBind has the potential to revolutionize AI, leading to innovative applications in image and video generation, audio synthesis, and immersive virtual experiences. It stands as a testament to the evolving capabilities of AI in mimicking human cognitive processes and interpreting the world around us.
3. ChatGPT
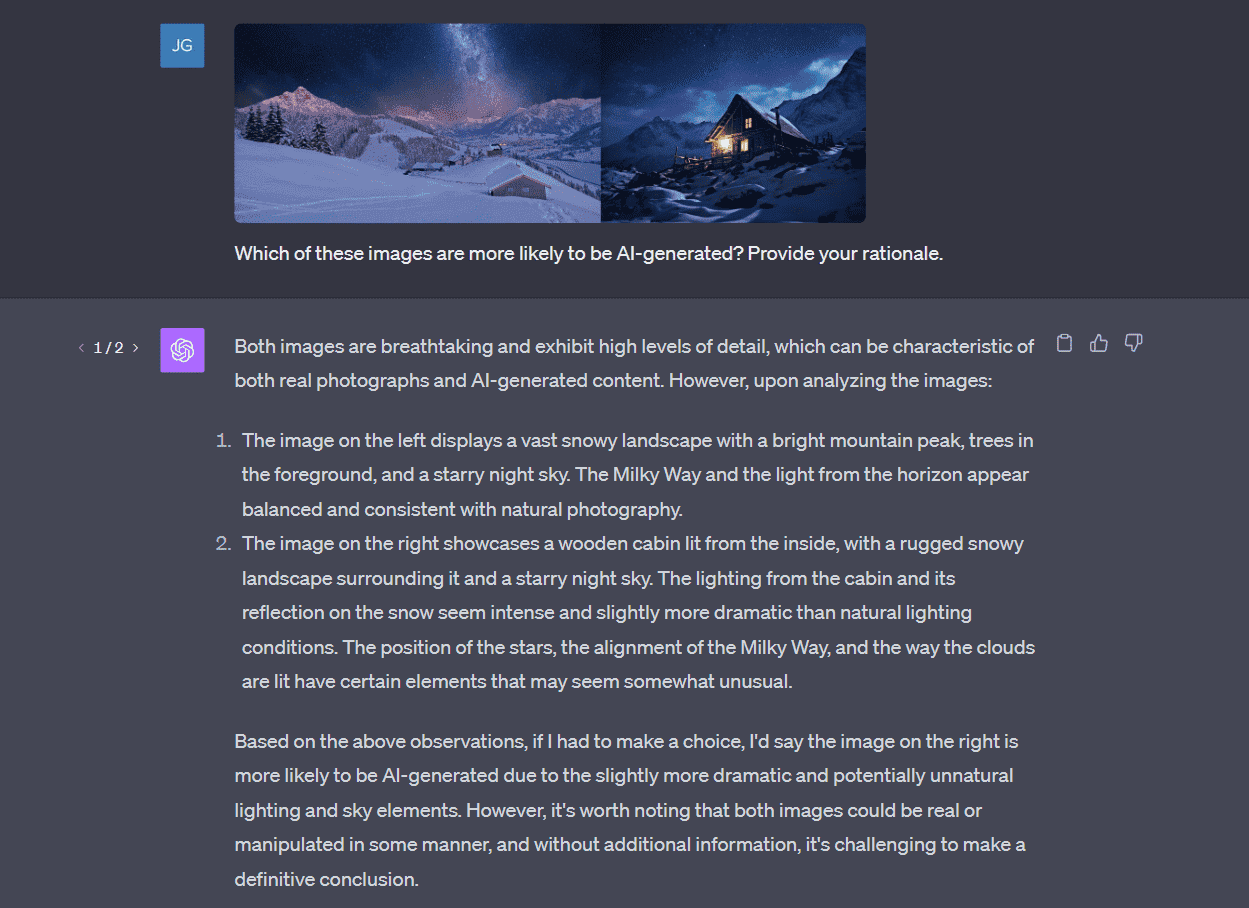
ChatGPT took a giant leap forward by incorporating multimodal features, enhancing its interaction capabilities beyond text to include voice and image recognition. This expansion represents a significant evolution in chatbot technology.
One of the most notable enhancements is ChatGPT’s image recognition capabilities. ChatGPT can now understand and interpret images, including handwritten text. Users can upload an image and engage with the chatbot about its content, whether it’s identifying objects in the image, like a cloud, or creating a meal plan from a photo of the contents of their fridge. This feature makes ChatGPT an incredibly versatile tool, capable of providing more contextual and relevant responses based on visual inputs.
In addition to image recognition, ChatGPT has also ventured into voice interactions. Equipped with a text-to-speech model, it offers users the choice of five different voice options, adding a new dimension to the chat experience. The incorporation of OpenAI’s Whisper speech recognition system further enhances this capability. Whisper can transcribe spoken words into text, facilitating a seamless and intuitive dialogue between the user and ChatGPT. This multimodal approach allows for a more natural and engaging conversational experience.
Key features of multimodal ChatGPT include:
Multimodal capabilities, processing not just text but also images and voice.
Image recognition, enabling it to interpret images and handwritten text.
Voice recognition supported by a text-to-speech model and five different voice options.
Integration with OpenAI’s Whisper for efficient speech-to-text transcription.
ChatGPT’s foray into multimodal functionalities marks a significant milestone in AI development. It showcases the potential of large models to process and interpret a diverse array of data types, paving the way for more sophisticated and interactive AI applications.
4. Inworld AI
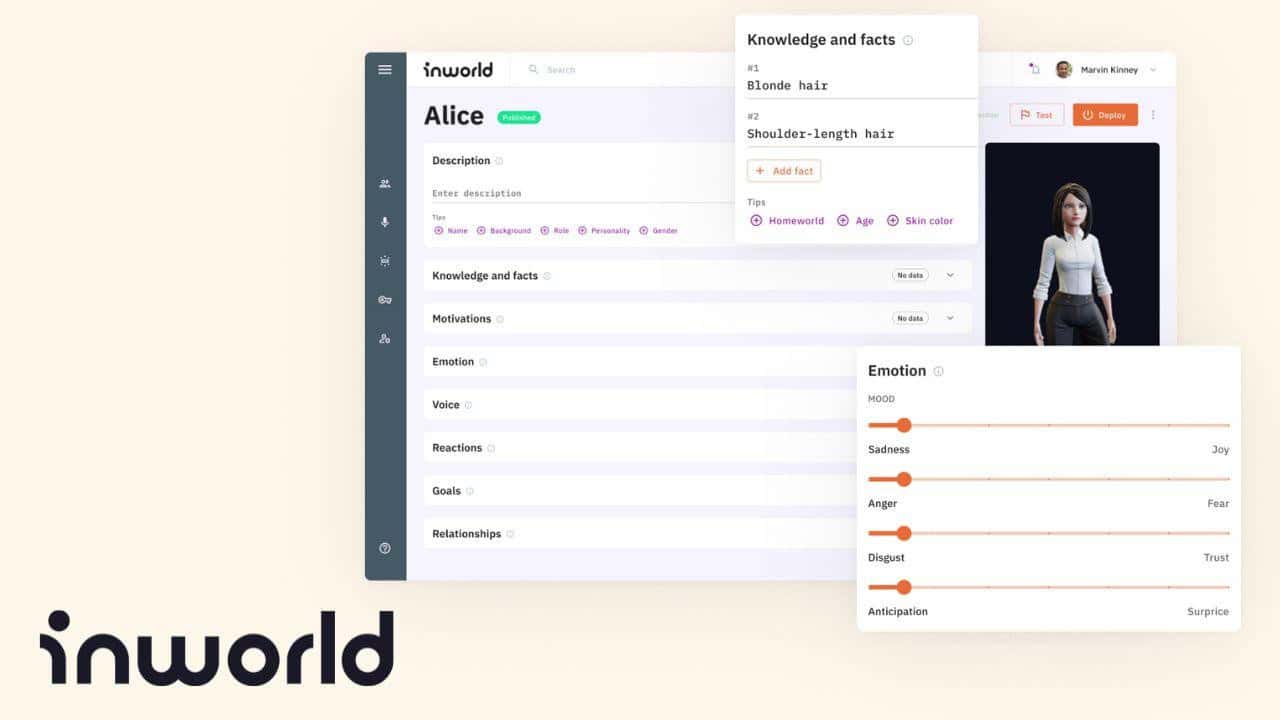
Inworld represents a significant advancement in the realm of artificial intelligence, particularly for non-playable characters (NPCs) in gaming and interactive environments. Developed by the team behind Google’s Dialogflow, this character engine extends beyond conventional large language models (LLMs), introducing a suite of features that elevate AI NPCs to new heights of realism and interaction.
What sets Inworld apart is its comprehensive approach to character development. It allows users to craft AI NPCs with distinct personalities, enhanced by a deep understanding of context and narrative. This ensures that characters stay true to their designed roles within the gaming world, providing a more immersive experience for players. The tool’s configurability extends to aspects like safety, knowledge, memory, and narrative controls, making it a versatile solution for various applications.
Inworld is not only a breakthrough for gaming. It’s also being utilized in other domains, such as creating empathetic brand ambassadors and customer service agents, facilitating personalized learning experiences, and enhancing interactive simulations and gamified learning. The tool’s use of Real-Time Generative AI enables it to create characters that are rich, nuanced, and engaging, offering a new standard for AI-powered personalities, dialogue, and reactions.
Key features of Inworld include:
Configurable safety, knowledge, and memory parameters for tailored character development.
Production-ready and scalable design, requiring no additional configuration for growth.
Optimization for real-time experiences, making it ideal for integration into dynamic applications.
Versatility in applications, from gaming to customer service and educational tools.
With its innovative approach to AI NPCs, Inworld is setting a new benchmark for character engines, offering unparalleled opportunities for creating engaging, realistic characters in a multitude of settings.
5. Objective (Formerly Kailua Labs)
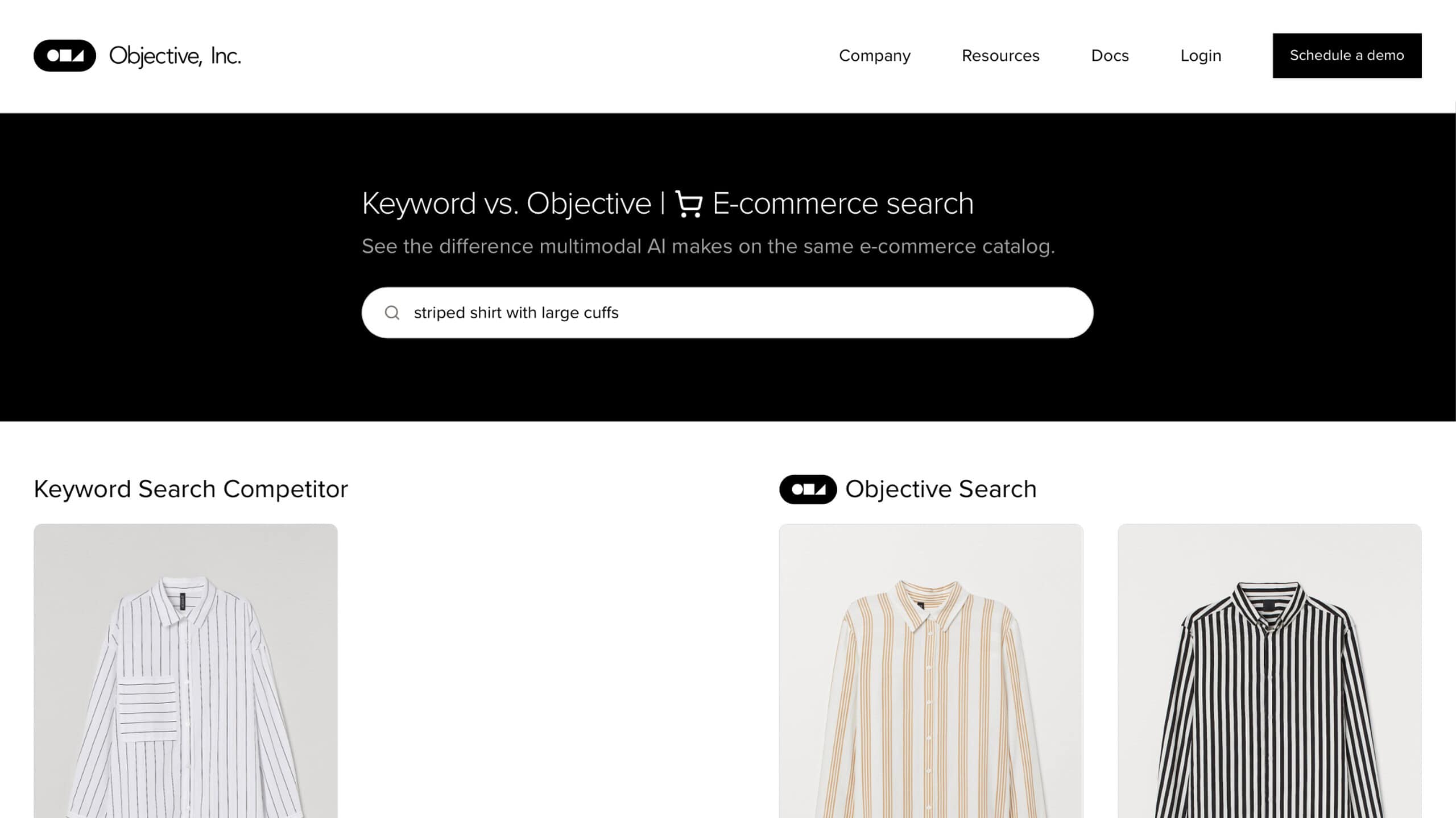
Objective (Formerly Kailua Labs) is revolutionizing the search process with its advanced AI capabilities. This tool leverages natural language processing (NLP) to allow users to intuitively search for a wide array of data types, including images, videos, and audio. What sets Objective apart is its ability to democratize the search process, removing the barriers of specialized knowledge or advanced technical expertise.
Objective’s user-friendly interface allows individuals to conduct searches using natural language queries, making it accessible and efficient for users of all skill levels. The tool’s strength lies in its support for multimodal search, enabling users to find content across various applications using a mix of natural language and different data types. This approach significantly enhances the accuracy and relevance of the search results.
Key features of Objective include:
User-friendly and accessible design, catering to users with varying degrees of technical expertise.
Multimodal search capabilities, allowing for more comprehensive and relevant search results.
The utilization of natural language processing to simplify and enhance the search experience.
Objective’s commitment to delivering easy-to-use, innovative AI tools exemplifies its dedication to enhancing the search experience. By simplifying the process and ensuring accurate results, Objective is making advanced AI search accessible to a broader audience, changing the way we interact with data.
Transforming Digital Interaction Through Multimodal AI Systems
As we’ve explored in this blog, the landscape of AI is being reshaped by the advent of multimodal tools and platforms. From Runway Gen-2’s groundbreaking video synthesis to Inworld AI’s innovative character engine, each tool brings a unique set of capabilities that are pushing the boundaries of what AI can achieve. Objective has revolutionized the way we approach data search, while ImageBind has set new benchmarks in data integration and interpretation. Finally, ChatGPT’s expansion into image and voice recognition is a testament to the evolving nature of conversational AI, making it more versatile and user-friendly.
These tools represent not just technological advancements but a paradigm shift in how we interact with and utilize AI. They demonstrate the immense potential of integrating multiple data types, leading to richer, more intuitive, and contextually aware AI systems. As these tools continue to evolve and new innovations emerge, we can expect even more exciting developments that will further bridge the gap between human and machine intelligence.
The future of AI is undoubtedly multimodal, and these tools are just the beginning of a journey towards more holistic, interactive, and intelligent systems. As we move forward, the possibilities are endless, and the potential for transformative applications across various industries is immense. The era of multimodal AI is here, and it promises to reshape our digital world.


