
I 5 principali strumenti e piattaforme di intelligenza artificiale multimodale



Il panorama dell'intelligenza artificiale è in costante evoluzione, con IA multimodale strumenti e piattaforme che stanno emergendo come attori significativi. Queste soluzioni innovative vanno oltre la tradizionale IA monomodale, integrando vari tipi di dati - come testo, immagini, voce e video - per creare sistemi più intelligenti, efficienti e intuitivi. Questa integrazione consente una comprensione e un'interazione più completa con i dati, rispecchiando da vicino il modo multiforme in cui gli esseri umani percepiscono ed elaborano le informazioni.
In questo blog esploreremo alcuni dei principali strumenti e piattaforme di IA multimodale che stanno facendo il giro del mondo tecnologico. Queste piattaforme non stanno solo rivoluzionando il modo in cui le macchine apprendono e interagiscono con i dati, ma anche il modo in cui le aziende e i privati sfruttano l'IA per applicazioni più complesse e accurate.
1. Pista Gen-2
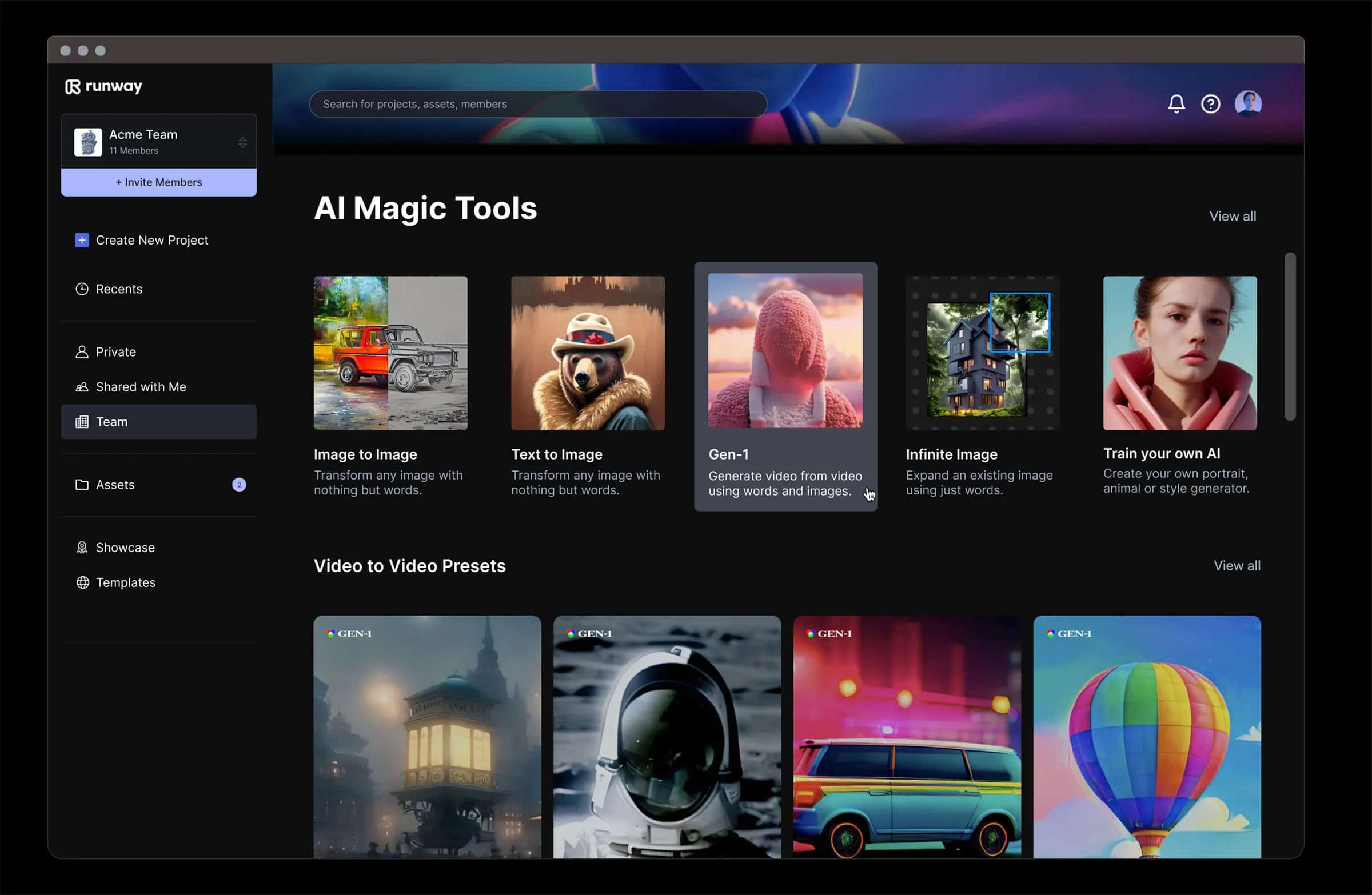
Pista Runway Gen-2, sviluppata da Runway, segna un'evoluzione significativa nel campo della IA generativain particolare nella sintesi di video e immagini. Questo strumento dimostra la potenza dell'intelligenza artificiale multimodale, consentendo agli utenti di generare video inediti utilizzando un mix di testo, immagini o clip video. Runway Gen-2 consente di creare risultati multimediali precisi, realistici e controllabili che superano i confini della creatività digitale.
Gli ultimi aggiornamenti di Gen-2 sono particolarmente degni di nota per i notevoli progressi nella fedeltà e nella coerenza dei video prodotti. Questo salto di qualità ha suscitato grande interesse nella comunità dell'IA e gli utenti lo hanno definito un momento cruciale nell'evoluzione dell'IA generativa. La capacità dello strumento di generare video in scala reale a partire da semplici richieste di testo, immagini o video esistenti è una caratteristica innovativa, che offre nuove possibilità alla narrazione e ai media digitali. Tali capacità hanno portato a paragoni con l'invenzione della macchina fotografica, suggerendo che l'IA sta diventando un nuovo mezzo per catturare e creare narrazioni visive.
Le caratteristiche principali di Runway Gen-2 includono:
La capacità di generare creazioni di video e immagini su misura.
Facile download dei contenuti generati per vari usi.
Accessibilità su entrambe le piattaforme web e mobile di Runway, per offrire versatilità e convenienza.
Un design che mette gli utenti in primo piano sviluppi dell'IA generativagarantendo un'innovazione costante.
Runway Gen-2 sta inaugurando una nuova era dei media digitali, in cui narrazione, creatività e intelligenza artificiale convergono per aprire strade inimmaginabili nella creazione di contenuti.
2. ImageBind di Meta AI
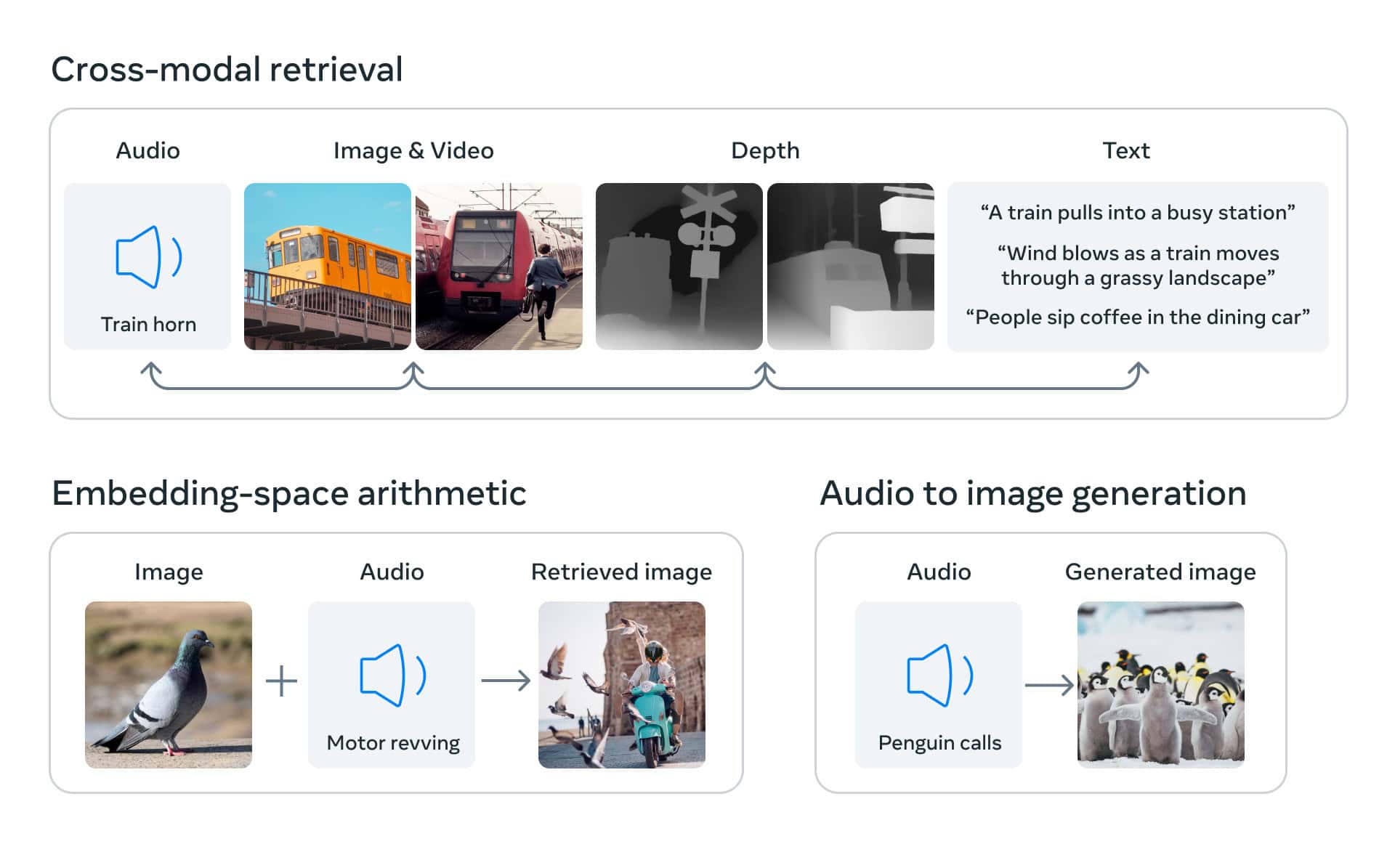
ImageBind, sviluppato da Meta AI, è all'avanguardia nell'innovazione dell'intelligenza artificiale multimodale e rappresenta un salto significativo nell'integrazione e nell'interpretazione di diversi tipi di dati. Questo modello all'avanguardia combina in modo unico le informazioni provenienti da sei modalità diverse: immagini, testo, audio, profondità, dati termici e IMU. Questa integrazione facilita l'incorporazione congiunta di questi diversi tipi di dati, creando opportunità senza precedenti per il recupero cross-modale, la composizione aritmetica delle modalità, il rilevamento e la generazione.
L'essenza dell'innovazione di ImageBind risiede nell'estensione dei modelli di linguaggio visivo su larga scala. Migliora le capacità di questi modelli a scatto zero, consentendo loro di adattarsi senza problemi a nuove modalità. Questa caratteristica consente lo sviluppo di applicazioni inedite fin dall'inizio, ampliando in modo significativo i potenziali casi d'uso dei sistemi di intelligenza artificiale. ImageBind ha dimostrato prestazioni superiori in compiti emergenti di riconoscimento a zero scatti in tutte le modalità e ha stabilito nuovi parametri di riferimento nel campo del riconoscimento a pochi scatti.
Lo sviluppo di ImageBind fa parte dei più ampi sforzi di Meta per creare sistemi di intelligenza artificiale multimodali che imparino da una varietà di tipi di dati. La capacità di combinare sei diverse forme di dati in un unico spazio di incorporazione non ha precedenti. Questa capacità non solo imita più da vicino la percezione umana, ma consente anche alle macchine di analizzare insieme diverse forme di informazioni in modo più efficace.
Le caratteristiche principali di ImageBind includono:
Integrazione di sei modalità (immagini, testo, audio, profondità, termica, IMU) in un unico modello.
Potenziamento delle capacità di zero-shot, per estendere la funzionalità dei modelli di linguaggio visivo.
Prestazioni superiori nei compiti di riconoscimento a colpo zero e a pochi colpi.
Disponibilità open-source, che contribuisce ai progressi nel campo dell'IA multimodale.
Con il suo approccio innovativo, ImageBind ha il potenziale per rivoluzionare l'IA, portando a un'innovativa applicazioni in immagine e la generazione di video, la sintesi audio e le esperienze virtuali immersive. È una testimonianza dell'evoluzione delle capacità dell'IA di imitare i processi cognitivi umani e di interpretare il mondo che ci circonda.
3. ChatGPT
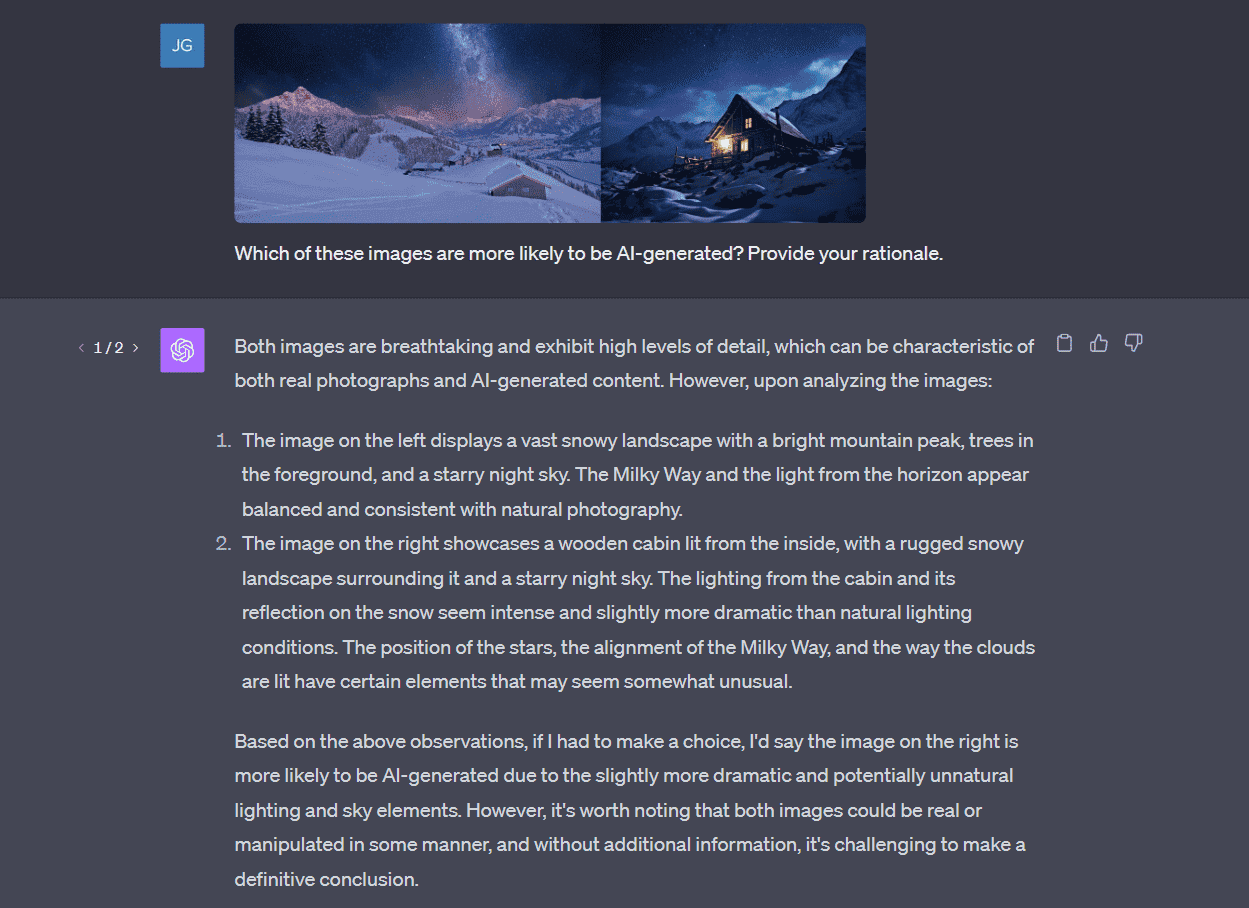
ChatGPT ha fatto un enorme passo avanti incorporando funzioni multimodali, migliorando le sue capacità di interazione oltre il testo per includere il riconoscimento vocale e delle immagini. Questa espansione rappresenta un'evoluzione significativa nella tecnologia dei chatbot.
Uno dei miglioramenti più significativi è rappresentato dalle capacità di riconoscimento delle immagini di ChatGPT. ChatGPT è ora in grado di comprendere e interpretare le immagini, compreso il testo scritto a mano. Gli utenti possono caricare un'immagine e interagire con il chatbot sul suo contenuto, sia che si tratti di identificare oggetti nell'immagine, come una nuvola, sia che si tratti di creare un piano alimentare da una foto del contenuto del proprio frigorifero. Questa funzione rende ChatGPT uno strumento incredibilmente versatile, in grado di fornire risposte più contestuali e pertinenti sulla base di input visivi.
Oltre al riconoscimento delle immagini, ChatGPT si è cimentato anche nelle interazioni vocali. Dotata di un modello text-to-speech, offre agli utenti la possibilità di scegliere tra cinque diverse opzioni vocali, aggiungendo una nuova dimensione all'esperienza di chat. L'integrazione del sistema di riconoscimento vocale Whisper di OpenAI migliora ulteriormente questa capacità. Whisper è in grado di trascrivere le parole pronunciate in testo, facilitando un dialogo continuo e intuitivo tra l'utente e ChatGPT. Questo approccio multimodale consente un'esperienza di conversazione più naturale e coinvolgente.
Le caratteristiche principali della ChatGPT multimodale includono:
Capacità multimodali, per elaborare non solo testo ma anche immagini e voce.
Riconoscimento delle immagini, che consente di interpretare immagini e testo scritto a mano.
Riconoscimento vocale supportato da un modello text-to-speech e da cinque diverse opzioni vocali.
Integrazione con Whisper di OpenAI per una trascrizione efficiente dal parlato al testo.
L'incursione di ChatGPT nelle funzionalità multimodali segna una tappa significativa nello sviluppo dell'IA. Mostra il potenziale dei modelli di grandi dimensioni nell'elaborare e interpretare una vasta gamma di tipi di dati, aprendo la strada ad applicazioni di IA più sofisticate e interattive.
4. Inworld AI
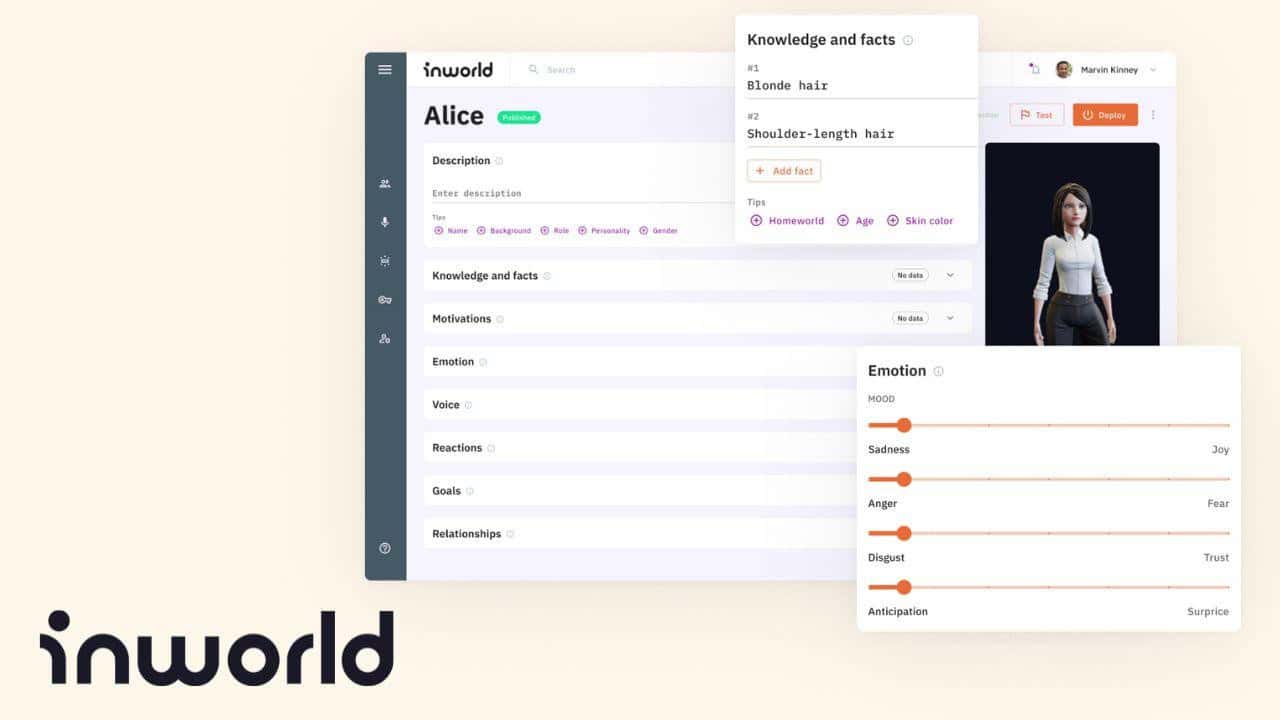
Inworld rappresenta un progresso significativo nel campo dell'intelligenza artificiale, in particolare per i personaggi non giocabili (PNG) nei giochi e negli ambienti interattivi. Sviluppato dal team che ha creato Dialogflow di Google, questo motore di personaggi va oltre i tradizionali modelli linguistici di grandi dimensioni (LLM), introducendo una serie di funzionalità che elevano i PNG dell'intelligenza artificiale a nuovi livelli di realismo e interazione.
Ciò che distingue Inworld è il suo approccio completo allo sviluppo dei personaggi. Permette agli utenti di creare PNG IA con personalità distinte, arricchite da una profonda comprensione del contesto e della narrazione. Questo garantisce che i personaggi rimangano fedeli al ruolo che hanno progettato all'interno del mondo di gioco, offrendo ai giocatori un'esperienza più coinvolgente. La configurabilità dello strumento si estende ad aspetti quali la sicurezza, la conoscenza, la memoria e i controlli narrativi, rendendolo una soluzione versatile per diverse applicazioni.
Inworld non è solo un'innovazione per i giochi. Viene utilizzato anche in altri ambiti, come la creazione di ambasciatori del marchio e agenti del servizio clienti empatici, la facilitazione di esperienze di apprendimento personalizzate e il miglioramento delle simulazioni interattive e dell'apprendimento gamificato. L'uso dell'intelligenza artificiale generativa in tempo reale consente di creare personaggi ricchi, ricchi di sfumature e coinvolgenti, offrendo un nuovo standard per le personalità, i dialoghi e le reazioni alimentate dall'intelligenza artificiale.
Le caratteristiche principali di Inworld includono:
Parametri di sicurezza, conoscenza e memoria configurabili per uno sviluppo personalizzato del personaggio.
Design scalabile e pronto per la produzione, che non richiede ulteriori configurazioni per la crescita.
Ottimizzazione per esperienze in tempo reale, ideale per l'integrazione in applicazioni dinamiche.
Versatilità nelle applicazioni, dal gioco al servizio clienti e agli strumenti didattici.
Con il suo approccio innovativo all'intelligenza artificiale dei PNG, Inworld stabilisce un nuovo punto di riferimento per i motori dei personaggi, offrendo opportunità senza precedenti per la creazione di personaggi coinvolgenti e realistici in una moltitudine di ambientazioni.
5. Obiettivo (Precedentemente Kailua Labs)
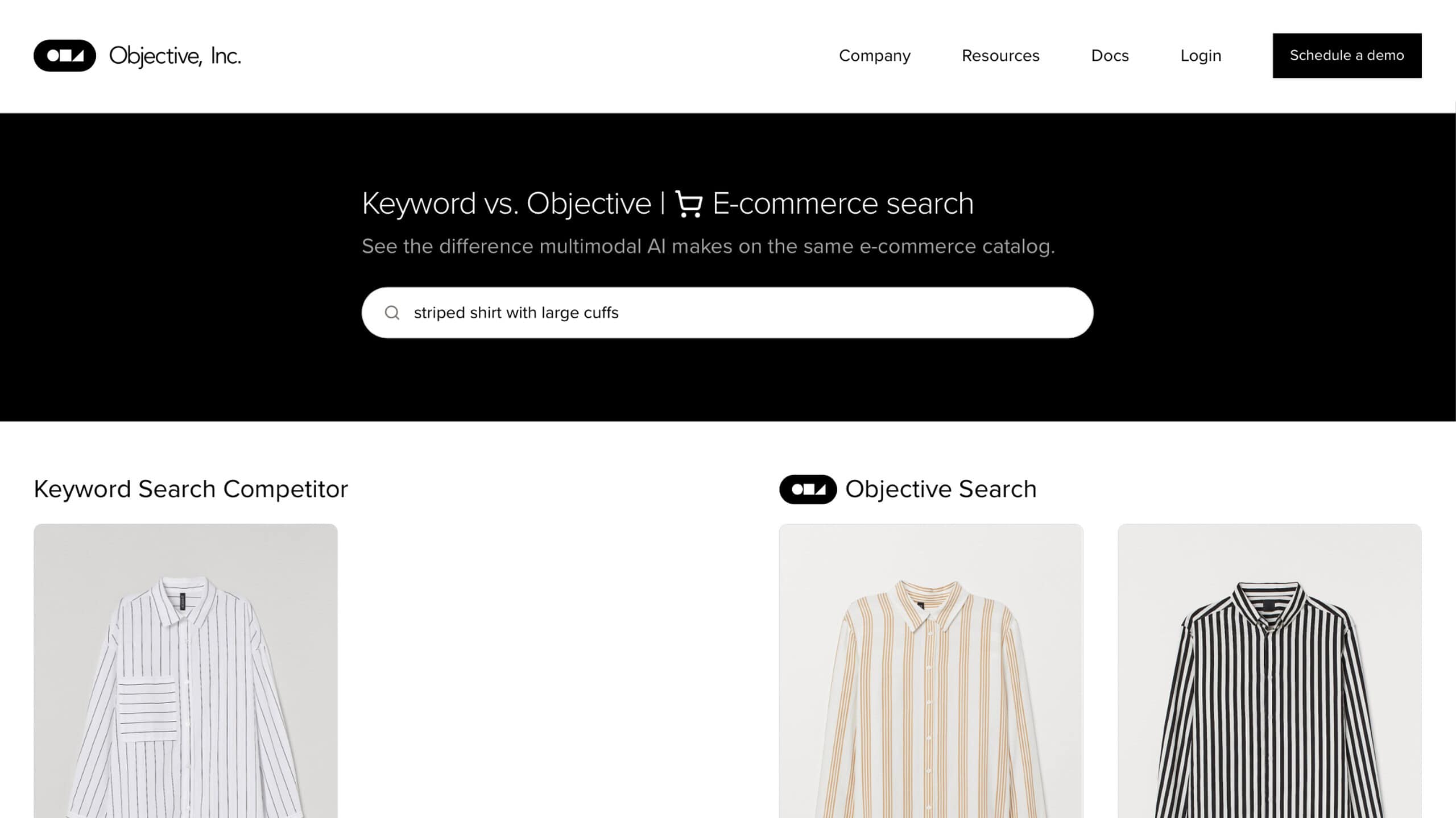
Objective (ex Kailua Labs) sta rivoluzionando il processo di ricerca grazie alle sue avanzate capacità di intelligenza artificiale. Questo strumento sfrutta l'elaborazione del linguaggio naturale (NLP) per consentire agli utenti di cercare in modo intuitivo un'ampia gamma di tipi di dati, tra cui immagini, video e audio. Ciò che distingue Objective è la sua capacità di democratizzare il processo di ricerca, eliminando le barriere delle conoscenze specialistiche o delle competenze tecniche avanzate.
Obiettivo interfaccia facile da usare L'interfaccia user-friendly di Objective consente di effettuare ricerche utilizzando query in linguaggio naturale, rendendolo accessibile ed efficiente per gli utenti di qualsiasi livello di competenza. Il punto di forza dello strumento è il supporto per la ricerca multimodale, che consente agli utenti di trovare contenuti in varie applicazioni utilizzando un mix di linguaggio naturale e diversi tipi di dati. Questo approccio migliora significativamente l'accuratezza e la pertinenza dei risultati della ricerca.
Le caratteristiche principali dell'obiettivo includono:
Un design facile e accessibile, che si rivolge a utenti con diversi gradi di competenza tecnica.
Funzionalità di ricerca multimodale, che consentono di ottenere risultati di ricerca più completi e pertinenti.
L'utilizzo dell'elaborazione del linguaggio naturale per semplificare e migliorare l'esperienza di ricerca.
L'impegno di Objective nel fornire strumenti di IA innovativi e di facile utilizzo esemplifica la sua dedizione al miglioramento dell'esperienza di ricerca. Semplificando il processo e garantendo risultati accurati, Objective rende la ricerca avanzata dell'intelligenza artificiale accessibile a un pubblico più ampio, cambiando il modo in cui interagiamo con i dati.
Trasformare l'interazione digitale attraverso sistemi di intelligenza artificiale multimodali
Come abbiamo esplorato in questo blog, il panorama dell'IA è stato rimodellato dall'avvento di strumenti e piattaforme multimodali. Dall'innovativa sintesi video di Runway Gen-2 all'innovativo motore per personaggi di Inworld AI, ogni strumento offre una serie di funzionalità uniche che stanno superando i limiti di ciò che l'IA può raggiungere. Objective ha rivoluzionato il modo in cui affrontiamo la ricerca dei dati, mentre ImageBind ha stabilito nuovi parametri di riferimento nell'integrazione e nell'interpretazione dei dati. Infine, l'espansione di ChatGPT nel riconoscimento delle immagini e della voce testimonia l'evoluzione dell'IA conversazionale, rendendola più versatile e facile da usare.
Questi strumenti non rappresentano solo un progresso tecnologico, ma un cambiamento di paradigma nel modo in cui interagiamo con l'IA e la utilizziamo. Dimostrano l'immenso potenziale dell'integrazione di più tipi di dati, che porta a sistemi di IA più ricchi, intuitivi e consapevoli del contesto. Con la continua evoluzione di questi strumenti e l'emergere di nuove innovazioni, possiamo aspettarci sviluppi ancora più interessanti che colmeranno ulteriormente il divario tra intelligenza umana e intelligenza artificiale.
Il futuro dell'IA è indubbiamente multimodale e questi strumenti sono solo l'inizio di un viaggio verso sistemi più olistici, interattivi e intelligenti. Le possibilità sono infinite e il potenziale di trasformazione delle applicazioni in vari settori è immenso. L'era dell'intelligenza artificiale multimodale è arrivata e promette di rimodellare il nostro mondo digitale.


