
The Top 5 Vector Databases for Enterprise AI & LLM Applications



The ability to efficiently store, manage, and search vast amounts of high-dimensional data has become paramount for today’s enterprises. Vector databases have emerged as a powerful solution, enabling organizations to unlock the full potential of AI-powered applications. These specialized databases are designed to handle complex vector data, facilitating fast similarity search, recommendations, and other advanced functionalities. As AI continues to permeate every aspect of modern technology, vector databases have become an indispensable tool for businesses seeking to gain a competitive edge.
In this blog, we will cover the top 5 vector databases on the market:
1. Pinecone
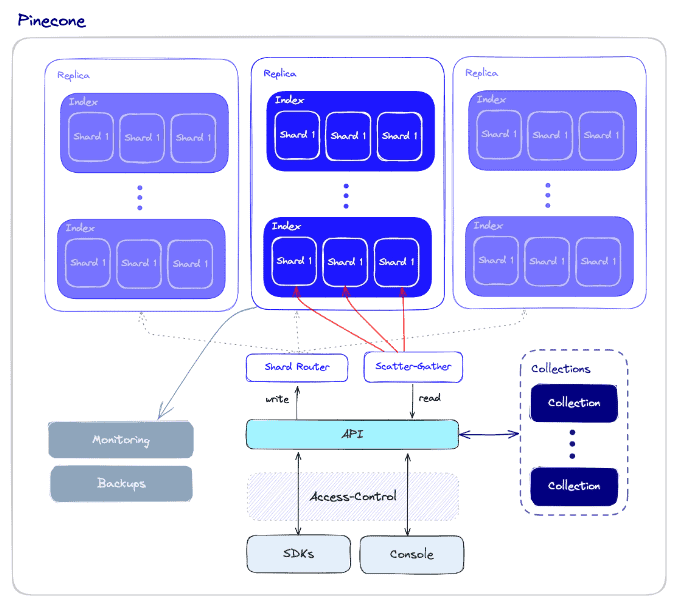
Pinecone is a fully managed vector database that prioritizes high performance and ease of use. It combines advanced vector search algorithms with features like filtering and distributed infrastructure to provide fast and reliable vector search at any scale.
One of Pinecone’s standout advantages is its serverless nature, eliminating the need for developers to provision or maintain infrastructure. This allows them to concentrate on building applications while Pinecone handles the complexities of managing and scaling the database. Pinecone integrates seamlessly with popular machine learning frameworks and data sources, making it a versatile choice for a wide range of applications, including semantic search, recommendations, anomaly detection, and question-answering.
2. Chroma

Chroma is a vector database designed for seamless integration with machine learning models and frameworks. Its primary goal is to simplify the process of building AI-powered applications by providing efficient vector storage, retrieval, and similarity search capabilities.
One of Chroma’s standout features is real-time indexing, allowing developers to quickly incorporate new data into their applications. Additionally, Chroma supports metadata storage, enabling the association of contextual information with vectors. Deployment is made easy with Chroma’s user-friendly interface and comprehensive documentation. By supporting various distance metrics and indexing algorithms, Chroma ensures optimal performance across different use cases, such as semantic search, recommendation systems, and anomaly detection.
3. Qdrant
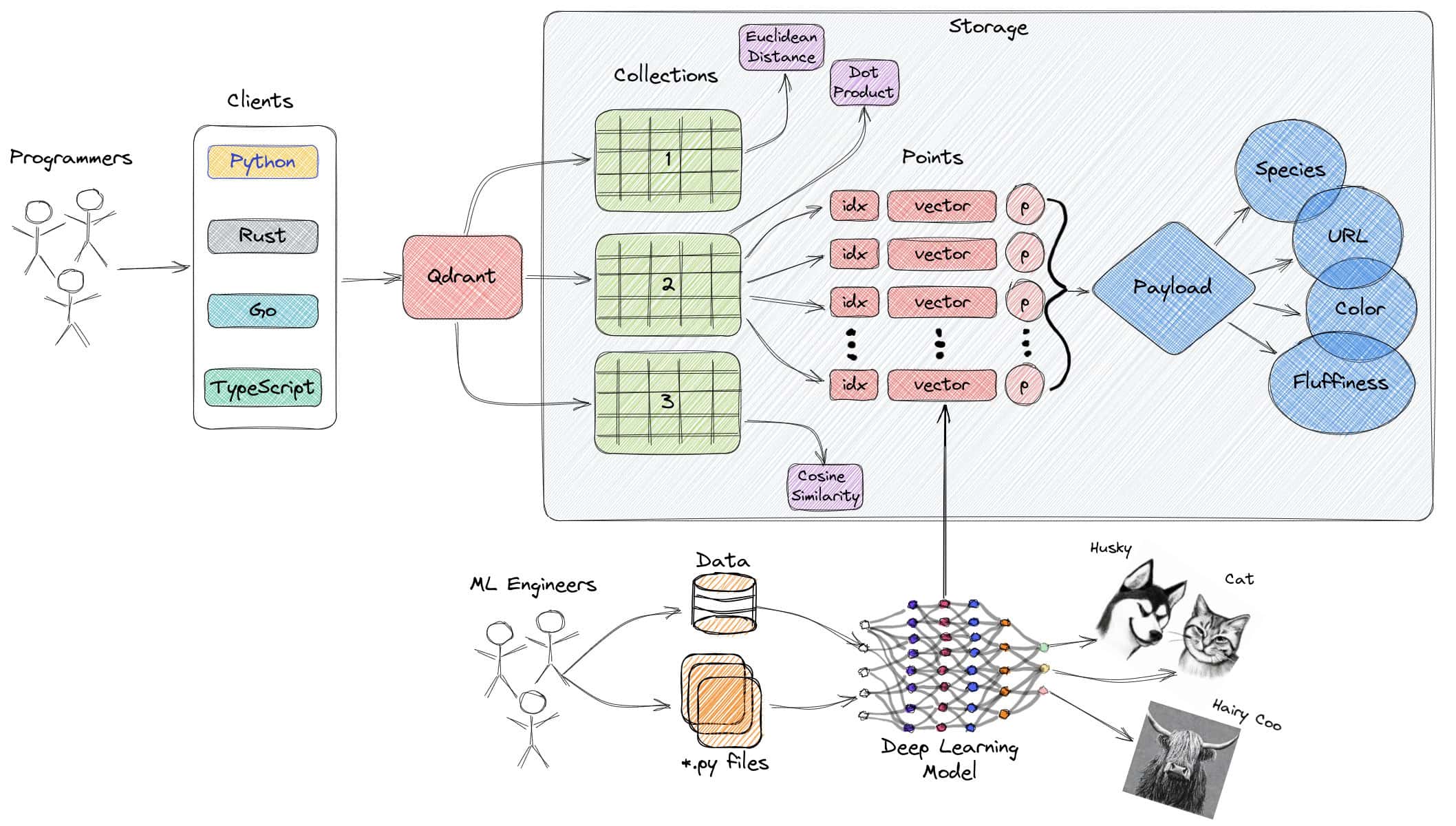
Qdrant is an open-source vector similarity search engine written in Rust, renowned for its speed and scalability. It provides a convenient API for storing, searching, and managing vectors with additional metadata, enabling developers to transform neural network encoders and embeddings into production-ready applications for matching, searching, recommending, and more.
Qdrant offers a plethora of features, including real-time updates, advanced filtering, distributed indexes, and cloud-native deployment options. Designed to handle billions of vectors and high query loads, Qdrant seamlessly integrates with machine learning frameworks, making it a powerful tool for building vector search solutions across various use cases, such as semantic search, recommendations, chatbots, matching engines, and anomaly detection.
4. Weaviate
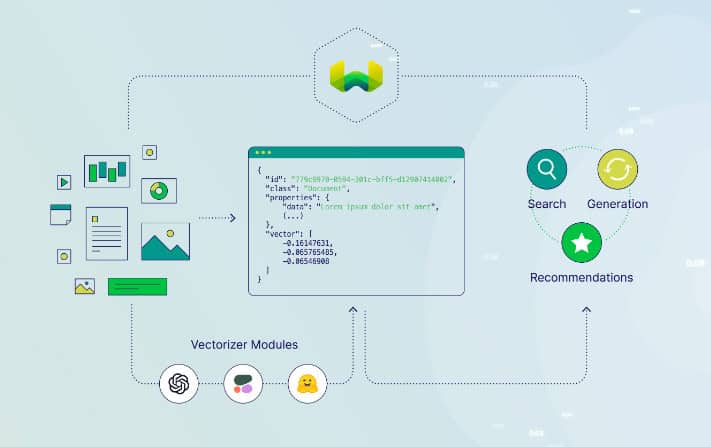
Weaviate is an open-source vector database that prioritizes speed, scalability, and ease of use. It stands out by allowing the storage of both objects and vectors, making it well-suited for combining vector search with structured filtering. Weaviate offers a GraphQL-based API, CRUD operations, horizontal scaling, and cloud-native deployment options, providing a flexible and scalable solution for developers.
Additionally, Weaviate incorporates modules for NLP tasks, automatic schema configuration, and custom vectorization, further enhancing its capabilities. It supports various distance metrics and index types, integrating seamlessly with popular machine learning tools, graph databases, and Kubernetes environments. Weaviate’s modular architecture and extensive features make it a powerful tool for building vector search applications across diverse use cases, including semantic search, image search, recommendations, and knowledge graphs.
5. Milvus
Milvus is an open-source vector database designed specifically for embedding management, similarity search, and scalable AI applications. It offers a comprehensive set of features, including heterogeneous compute support, storage reliability, comprehensive metrics, and a cloud-native architecture.
One of Milvus’s strengths lies in its ability to deliver consistent performance across different deployment environments. Milvus provides a flexible API that supports various indexes, distance metrics, and query types, enabling developers to tailor the database to their specific needs. It can scale to billions of vectors and be extended with custom plugins, ensuring scalability and extensibility. Milvus seamlessly integrates with machine learning frameworks, Kubernetes operators, and analytics tools, making it a versatile choice for a wide range of applications, such as image and video search, recommendation engines, chatbots, and anomaly detection.
Choosing the Right Vector Database for Your Enterprise
As the adoption of AI and machine learning continues to accelerate, vector databases have emerged as a critical component in building powerful enterprise AI applications. From fully managed solutions like Pinecone to open-source options like Qdrant and Chroma, the vector database landscape offers a diverse range of options tailored to different organizational needs and use cases.
Whether you’re building a semantic search engine, a recommendation system, or any other AI-powered application, vector databases provide the foundation for unlocking the full potential of machine learning models. By enabling fast similarity search, advanced filtering, and seamless integration with popular frameworks, these databases empower developers to focus on building innovative solutions without worrying about the underlying complexities of managing vector data.


