
How your enterprise should be using vector databases for its LLM apps – AI&YOU #54



Stat/Fact of the Week: Over the next three years, 45.9% of enterprises aim to prioritize scaling AI and ML applications. In the upcoming fiscal year, 56.8% anticipate a double-digit revenue increase from their AI/ML investments, while another 37% expect single-digit growth.
As LLMs become more sophisticated and demanding, enterprises face the challenge of efficiently storing and retrieving the vast amounts of data required to train and operate these models. Enter vector databases – the key to unlocking the full potential of LLMs in enterprise AI applications.
In this week’s edition of AI&YOU, we are highlighting insights from three blogs we published:
How Your Enterprise Should Be Using Vector Databases for LLM Apps in 2024
How to Build Scalable Enterprise AI with Vector Databases in 2024
10 Strategies for Adopting Vector Databases in Your Enterprise
How your enterprise should be using vector database for its LLM apps – AI&YOU #54
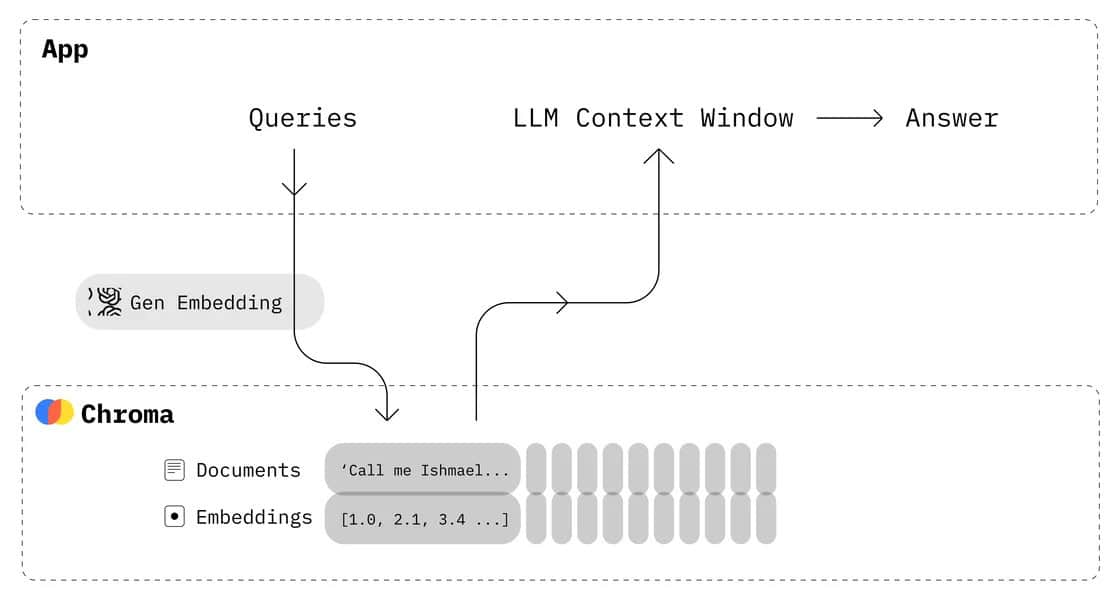
Vector databases are specialized databases designed to store and manage high-dimensional vector data. Unlike traditional databases that store data as rows and columns, vector databases represent data as numerical vectors in a vector space.
Each data point, such as a text document or an image, is converted into a vector embedding – a dense, fixed-length numerical representation that captures the semantic meaning of the data.
How vector databases work
At the core of vector databases lies the concept of vector embeddings and vector space. Vector embeddings are generated using machine learning models, which learn to map data points to a high-dimensional vector space. In this vector space, similar data points are represented by vectors that are close to each other, while dissimilar data points are farther apart.
Vector databases enable efficient similarity search and nearest neighbor search operations. When a query vector is provided, the database can quickly find the most similar vectors in the vector space using distance metrics like cosine similarity or Euclidean distance. This allows for fast and accurate retrieval of relevant data based on semantic similarity rather than exact keyword matches.
Advantages of using vector databases for LLM applications
Vector databases offer several key advantages over traditional databases when it comes to supporting LLM applications:
Semantic search: Vector databases enable semantic search, allowing LLMs to retrieve information based on the meaning and context of the query rather than relying on exact keyword matches.
Scalability: Vector databases are designed to handle large-scale vector data efficiently. They can store and process millions or even billions of high-dimensional vectors.
Faster query times: The specialized indexing and search algorithms used by vector databases enable lightning-fast query times, even on large datasets.
Improved accuracy: By leveraging the semantic information captured in vector embeddings, vector databases can help LLMs provide more accurate and contextually relevant responses to user queries.
LLMs and Vector Databases: A Perfect Match for Enterprise AI
The success of LLMs heavily relies on the quality and accessibility of the data on which they are trained. This is where vector databases come into play, providing a powerful solution for storing and retrieving the vast amounts of data required by LLMs.
LLMs are trained on massive datasets containing billions of words, allowing them to learn the intricacies of language and develop a deep understanding of context and meaning. Once pre-trained, LLMs can be fine-tuned on domain-specific data to adapt to particular use cases and industries. The quality and relevance of this data directly impact the performance and accuracy of LLMs in enterprise AI applications.
Challenges of using traditional databases for LLM data storage and retrieval
Traditional databases, such as relational databases, are not well-suited for handling the unstructured and high-dimensional data required by LLMs. These databases struggle with the following challenges:
Scalability: Traditional databases often face performance issues when dealing with large-scale datasets, making it difficult to store and retrieve the massive amounts of data needed for LLM training and operation.
Inefficient search: Keyword-based search in traditional databases fails to capture the semantic meaning and context of the data, leading to irrelevant or incomplete results when queried by LLMs.
Lack of flexibility: The rigid schema of traditional databases makes it challenging to accommodate the diverse and evolving data types and structures associated with LLMs.
How vector databases overcome these challenges
Vector databases are specifically designed to address the limitations of traditional databases when it comes to supporting LLMs:
Efficient similarity search for context-aware data retrieval: By representing data as vectors in a high-dimensional space, vector databases enable fast and accurate similarity search. LLMs can retrieve relevant information based on the semantic meaning of the query, ensuring more contextually appropriate responses.
Scalability for handling large datasets: Vector databases are built to handle massive amounts of vector data efficiently. They can scale horizontally across multiple machines, allowing for the storage and processing of billions of vector embeddings required by LLMs.
Identifying use cases for vector databases in your LLM applications
Before implementing a vector database, it’s crucial to identify the specific use cases where it can provide the most value for your enterprise AI applications.
Semantic search and information retrieval is one area where vector databases excel. By representing documents, images, and other data as vectors, LLMs can retrieve the most semantically similar results using natural language queries, improving the accuracy and relevance of search outputs.
Retrieval augmented generation, or RAG, is another key use case, where LLMs can generate more accurate and contextually relevant responses by integrating with vector databases. During the generation process, the LLM retrieves relevant information from the vector database based on the input query, enhancing the coherence and factual correctness of the generated text.
Personalization and recommendation systems can also greatly benefit from vector databases. By representing user preferences, behaviors, and item features as vectors, LLMs can generate highly targeted recommendations and user-specific outputs by computing the similarity between user and item vectors.
Vector databases can also be used for knowledge management and content organization. Enterprises can leverage vector databases to organize and manage large volumes of unstructured data, automatically categorizing and tagging content by clustering similar vectors together, making it easier to discover and navigate.
Choosing the right vector database for your needs
Selecting the appropriate vector database is crucial for the success of your enterprise AI applications. When evaluating different vector database solutions, consider the trade-offs between open-source and proprietary options.
Open-source vector databases offer flexibility, customization, and cost-effectiveness, with active communities, regular updates, and extensive documentation. On the other hand, proprietary solutions, often provided by cloud platforms or specialized vendors, offer managed services, enterprise-grade support, and seamless integration with other tools in their ecosystem, but may come with higher costs and vendor lock-in risks.
Scalability, performance, and ease of integration are critical factors to assess when choosing a vector database. Evaluate the database’s ability to handle the scale of your data, both in terms of storage capacity and query performance, and consider the database’s indexing and search algorithms, such as approximate nearest neighbor (ANN) search, which can significantly speed up similarity search on large datasets.
Investigate how well the vector database integrates with your existing technology stack, including LLM frameworks, data pipelines, and downstream applications, and prioritize databases with active communities, comprehensive documentation, and responsive support channels to ensure access to timely help, bug fixes, and feature updates.

Best practices for integrating vector databases with your LLM applications
To ensure a smooth and effective implementation of vector databases in your enterprise AI applications, several best practices should be followed.
First, develop a robust data preprocessing pipeline to clean, normalize, and transform your raw data into a format suitable for vector embedding generation. Experiment with different embedding models and techniques to find the most appropriate approach for your specific use case and data types, and fine-tune pre-trained embedding models on your domain-specific data to capture the unique semantics and relationships within your enterprise’s context.
Implement data quality checks and validation steps to ensure the consistency and reliability of your vector embeddings.
Query optimization and performance tuning are essential for efficient vector database usage. Fine-tune your vector database’s indexing and search parameters to strike a balance between query speed and accuracy, and employ techniques like dimensionality reduction, quantization methods, and caching mechanisms to optimize the storage and retrieval of vectors.
Establish a comprehensive monitoring system to track the performance, availability, and health of your vector database, and perform regular maintenance tasks to ensure the integrity and freshness of your vector data.
Security and access control are paramount when dealing with sensitive enterprise data. Implement robust security measures, such as encryption, authentication, and access control mechanisms, to safeguard sensitive information, and regularly audit and review access logs to detect and prevent unauthorized access attempts or suspicious activities.
Foster a culture of collaboration and knowledge sharing among your AI teams, encouraging the exchange of best practices, lessons learned, and innovative ideas related to vector databases and LLM applications.
By following these best practices and considering the unique requirements of your enterprise, you can successfully implement vector databases and unlock the full potential of your LLM applications.
Enabling Retrieval Augmented Generation (RAG) with Vector Databases
One of the most exciting applications of vector databases in enterprise AI is their ability to enable retrieval augmented generation. RAG combines the power of large language models with vector search to generate contextually relevant and accurate responses.
In an enterprise setting, RAG can be used to build intelligent chatbots and virtual assistants that can understand and respond to user queries with remarkable accuracy. By leveraging vector databases to store and retrieve relevant information, LLMs can generate human-like responses that are tailored to the specific context of the conversation.
For example, a financial institution can deploy a RAG-powered chatbot to provide personalized investment advice to customers. By integrating vector databases with LLMs, the chatbot can understand the customer’s financial goals, risk tolerance, and investment preferences, and generate tailored recommendations based on the most relevant information retrieved from the database.
Impact on Enterprise AI Scalability, Adoption, and ROI
Advancements in vector database technologies and their integration with other AI innovations are profoundly impacting enterprise AI adoption, scalability, and return on investment (ROI). As vector databases enable more scalable, efficient, and explainable AI solutions, businesses will derive greater value from their AI investments.
The ability to build AI applications that can process and analyze vast amounts of unstructured data in real time opens up new opportunities for automation, optimization, and innovation across various business functions. From customer service and marketing to supply chain management and financial forecasting, the potential applications of vector databases in enterprise AI are limitless.
As a result, we are seeing a significant increase in enterprise AI adoption, with businesses across industries leveraging vector databases to drive competitive advantage and business growth. The ROI of AI initiatives will also improve, as vector databases help organizations achieve faster time-to-value, reduced operational costs, and increased revenue streams.
10 Strategies for Adopting Vector Databases in Your Enterprise
This week, we also explored 10 strategies for adopting vector databases in your enterprise:
Align vector databases with your business objectives: Identify specific use cases that can benefit from vector databases and drive tangible business value.
Assess scalability and performance needs: Evaluate your current data volumes, projected growth, and query patterns to determine the optimal scalability approach.
Ensure seamless integration and compatibility: Address potential interoperability challenges and integrate vector databases seamlessly with your existing infrastructure and data pipeline.
Implement robust security measures: Protect your organization’s assets by implementing strong encryption, secure key management, and regular access monitoring and auditing.
Optimize indexing and query performance: Select indexing strategies that align with your data characteristics and query patterns, and continuously iterate on your strategies to ensure optimal performance.
Build in-house expertise and foster collaboration: Invest in comprehensive training programs and encourage cross-functional collaboration to accelerate the adoption and maximize the benefits of vector databases.
Adopt a phased implementation approach: Start small with focused pilot projects, gather feedback, and gradually scale up your implementation to minimize disruptions and manage resources effectively.
Leverage metadata and operational data: Utilize metadata to enable targeted and context-aware queries, and analyze operational data to fine-tune your vector database configuration and optimize performance.
Integrate with existing data pipelines: Ensure efficient data ingestion, preprocessing, and transformation, and establish data governance policies to maintain data quality and reliability.
Choose the right vector database solution: Evaluate both open-source and commercial options to find the best fit for your organization’s requirements and capabilities.
As the landscape of enterprise AI continues to evolve, vector databases will play an increasingly critical role in driving innovation and competitive advantage. By embracing this transformative technology and following these implementation strategies, you can position your organization at the forefront.
For even more content on enterprise AI, including infographics, stats, how-to guides, articles, and videos, follow Skim AI on LinkedIn
Are you a Founder, CEO, Venture Capitalist, or Investor seeking AI Advisory or Due Diligence services? Get the guidance you need to make informed decisions about your company’s AI product strategy or investment opportunities.
We build custom AI solutions for Venture Capital and Private Equity backed companies in the following industries: Medical Technology, News/Content Aggregation, Film & Photo Production, Educational Technology, Legal Technology, Fintech & Cryptocurrency.


