
AI Research Paper Summarized: “Chain of Thought(lessness)?” Prompting



Chain-of-Thought (CoT) prompting has been hailed as a breakthrough in unlocking the reasoning capabilities of large language models (LLMs). This technique, which involves providing step-by-step reasoning examples to guide LLMs, has garnered significant attention in the AI community. Many researchers and practitioners have claimed that CoT prompting allows LLMs to tackle complex reasoning tasks more effectively, potentially bridging the gap between machine computation and human-like problem-solving.
However, a recent paper titled “Chain of Thoughtlessness? An Analysis of CoT in Planning” challenges these optimistic claims. This research paper, focusing on planning tasks, provides a critical examination of CoT prompting’s effectiveness and generalizability. As AI practitioners, it’s crucial to understand these findings and their implications for developing AI applications that require sophisticated reasoning capabilities.
Understanding the Study
The researchers chose a classical planning domain called Blocksworld as their primary testing ground. In Blocksworld, the task is to rearrange a set of blocks from an initial configuration to a goal configuration using a series of move actions. This domain is ideal for testing reasoning and planning capabilities because:
It allows for the generation of problems with varying complexity
It has clear, algorithmically verifiable solutions
It’s unlikely to be heavily represented in LLM training data
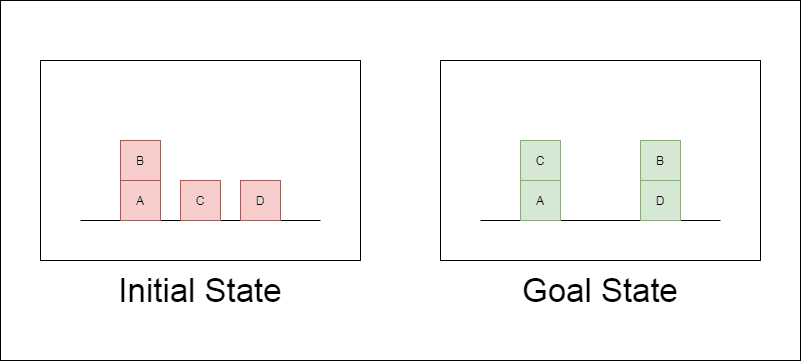
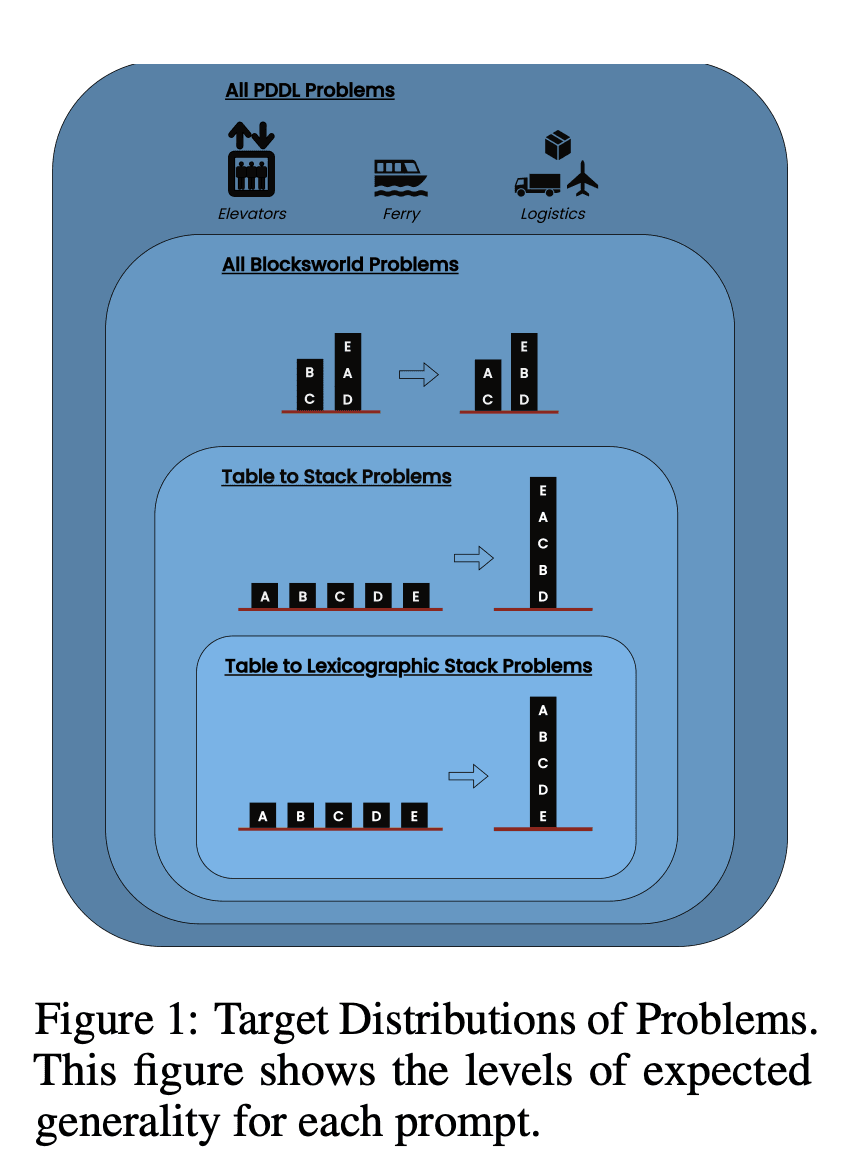
The study examined three state-of-the-art LLMs: GPT-4, Claude-3-Opus, and GPT-4-Turbo. These models were tested using prompts of varying specificity:
Zero-Shot Chain of Thought (Universal): Simply appending “let’s think step by step” to the prompt.
Progression Proof (Specific to PDDL): Providing a general explanation of plan correctness with examples.
Blocksworld Universal Algorithm: Demonstrating a general algorithm for solving any Blocksworld problem.
Stacking Prompt: Focusing on a specific subclass of Blocksworld problems (table-to-stack).
Lexicographic Stacking: Further narrowing down to a particular syntactic form of the goal state.
By testing these prompts on problems of increasing complexity, the researchers aimed to evaluate how well LLMs could generalize the reasoning demonstrated in the examples.
Key Findings Unveiled
The results of this study challenge many prevailing assumptions about CoT prompting:
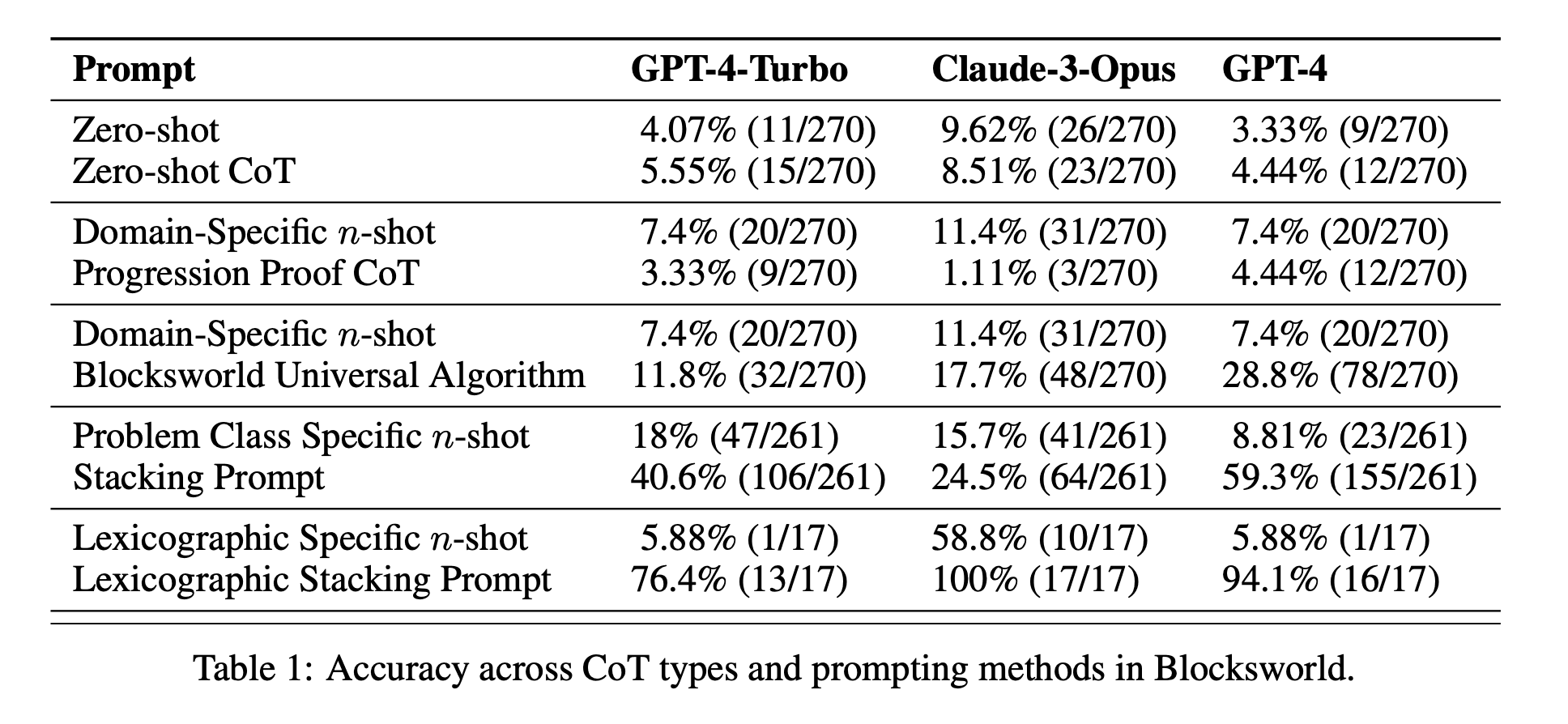
Limited Effectiveness of CoT: Contrary to previous claims, CoT prompting only showed significant performance improvements when the examples provided were extremely similar to the query problem. As soon as the problems deviated from the exact format shown in the examples, performance dropped sharply.
Rapid Performance Degradation: As the complexity of the problems increased (measured by the number of blocks involved), the accuracy of all models decreased dramatically, regardless of the CoT prompt used. This suggests that LLMs struggle to extend the reasoning demonstrated in simple examples to more complex scenarios.
Ineffectiveness of General Prompts: Surprisingly, more general CoT prompts often performed worse than standard prompting without any reasoning examples. This contradicts the idea that CoT helps LLMs learn generalizable problem-solving strategies.
Specificity Trade-off: The study found that highly specific prompts could achieve high accuracy, but only on a very narrow subset of problems. This highlights a sharp trade-off between performance gains and the applicability of the prompt.
Lack of True Algorithmic Learning: The results strongly suggest that LLMs are not learning to apply general algorithmic procedures from the CoT examples. Instead, they seem to rely on pattern matching, which breaks down quickly when faced with novel or more complex problems.
These findings have significant implications for AI practitioners and enterprises looking to leverage CoT prompting in their applications. They suggest that while CoT can boost performance in certain narrow scenarios, it may not be the panacea for complex reasoning tasks that many had hoped for.
Beyond Blocksworld: Extending the Investigation
To ensure their findings weren’t limited to the Blocksworld domain, the researchers extended their investigation to several synthetic problem domains commonly used in previous CoT studies:
CoinFlip: A task involving predicting the state of a coin after a series of flips.
LastLetterConcatenation: A text processing task requiring the concatenation of the last letters of given words.
Multi-step Arithmetic: Problems involving the simplification of complex arithmetic expressions.
These domains were chosen because they allow for the generation of problems with increasing complexity, similar to Blocksworld. The results from these additional experiments were strikingly consistent with the Blocksworld findings:
Lack of Generalization: CoT prompting showed improvements only on problems very similar to the provided examples. As problem complexity increased, performance quickly degraded to levels comparable with or worse than standard prompting.
Syntactic Pattern Matching: In the LastLetterConcatenation task, CoT prompting improved certain syntactic aspects of the answers (like using the correct letters) but failed to maintain accuracy as the number of words increased.
Failure Despite Perfect Intermediate Steps: In the arithmetic tasks, even when models could perfectly solve all possible single-digit operations, they still failed to generalize to longer sequences of operations.
These results further reinforce the conclusion that current LLMs do not truly learn generalizable reasoning strategies from CoT examples. Instead, they appear to rely heavily on superficial pattern matching, which breaks down when faced with problems that deviate from the demonstrated examples.
Implications for AI Development
The findings of this study have significant implications for AI development, particularly for enterprises working on applications that require complex reasoning or planning capabilities:
Reassessing CoT Effectiveness: The study challenges the notion that CoT prompting “unlocks” general reasoning abilities in LLMs. AI developers should be cautious about relying on CoT for tasks that require true algorithmic thinking or generalization to novel scenarios.
Limitations of Current LLMs: Despite their impressive capabilities in many areas, state-of-the-art LLMs still struggle with consistent, generalizable reasoning. This suggests that alternative approaches may be necessary for applications requiring robust planning or multi-step problem-solving.
The Cost of Prompt Engineering: While highly specific CoT prompts can yield good results for narrow problem sets, the human effort required to craft these prompts may outweigh the benefits, especially given their limited generalizability.
Rethinking Evaluation Metrics: The study highlights the importance of testing AI models on problems of varying complexity and structure. Relying solely on static test sets may overestimate a model’s true reasoning capabilities.
The Gap Between Perception and Reality: There’s a significant discrepancy between the perceived reasoning abilities of LLMs (often anthropomorphized in popular discourse) and their actual capabilities as demonstrated in this study.
Recommendations for AI Practitioners
Given these insights, here are some key recommendations for AI practitioners and enterprises working with LLMs:
Rigorous Evaluation Practices:
Implement testing frameworks that can generate problems of varying complexity.
Don’t rely solely on static test sets or benchmarks that may be represented in training data.
Evaluate performance across a spectrum of problem variations to assess true generalization.
Realistic Expectations for CoT:
Use CoT prompting judiciously, understanding its limitations in generalization.
Be aware that performance improvements from CoT may be limited to narrow problem sets.
Consider the trade-off between prompt engineering effort and potential performance gains.
Hybrid Approaches:
For complex reasoning tasks, consider combining LLMs with traditional algorithmic approaches or specialized reasoning modules.
Explore methods that can leverage the strengths of LLMs (e.g., natural language understanding) while compensating for their weaknesses in algorithmic reasoning.
Transparency in AI Applications:
Clearly communicate the limitations of AI systems, especially when they involve reasoning or planning tasks.
Avoid overstating the capabilities of LLMs, particularly in safety-critical or high-stakes applications.
Continued Research and Development:
Invest in research aimed at improving the true reasoning capabilities of AI systems.
Explore alternative architectures or training methods that might lead to more robust generalization in complex tasks.
Domain-Specific Fine-tuning:
For narrow, well-defined problem domains, consider fine-tuning models on domain-specific data and reasoning patterns.
Be aware that such fine-tuning may improve performance within the domain but may not generalize beyond it.
By following these recommendations, AI practitioners can develop more robust and reliable AI applications, avoiding potential pitfalls associated with overestimating the reasoning capabilities of current LLMs. The insights from this study serve as a valuable reminder of the importance of critical evaluation and realistic assessment in the rapidly evolving field of AI.
The Bottom Line
This groundbreaking study on Chain-of-Thought prompting in planning tasks challenges our understanding of LLM capabilities and prompts a reevaluation of current AI development practices. By revealing the limitations of CoT in generalizing to complex problems, it underscores the need for more rigorous testing and realistic expectations in AI applications.
For AI practitioners and enterprises, these findings highlight the importance of combining LLM strengths with specialized reasoning approaches, investing in domain-specific solutions where necessary, and maintaining transparency about AI system limitations. As we move forward, the AI community must focus on developing new architectures and training methods that can bridge the gap between pattern matching and true algorithmic reasoning. This study serves as a crucial reminder that while LLMs have made remarkable progress, achieving human-like reasoning capabilities remains an ongoing challenge in AI research and development.


