
Documento di ricerca sull'intelligenza artificiale riassunto: "Catena di pensieri?". Sollecitazione



Il prompt Chain-of-Thought (CoT) è stato salutato come una svolta per sbloccare le capacità di ragionamento dei modelli linguistici di grandi dimensioni (LLM). Questa tecnica, che consiste nel fornire esempi di ragionamento passo dopo passo per guidare gli LLM, ha suscitato una notevole attenzione nella comunità dell'intelligenza artificiale. Molti ricercatori e professionisti hanno affermato che il prompting della CoT consente agli LLM di affrontare compiti di ragionamento complessi in modo più efficace, colmando potenzialmente il divario tra il calcolo automatico e la risoluzione di problemi simili a quelli umani.
Tuttavia, un recente articolo intitolato "Catena di sconsideratezza? Un'analisi della CoT nella pianificazione" mette in discussione queste affermazioni ottimistiche. Questo documento di ricerca, incentrato su compiti di pianificazione, fornisce un esame critico dell'efficacia e della generalizzabilità dei prompt della CoT. Come professionisti dell'IA, è fondamentale comprendere questi risultati e le loro implicazioni per lo sviluppo di applicazioni di IA che richiedono sofisticate capacità di ragionamento.
Comprendere lo studio
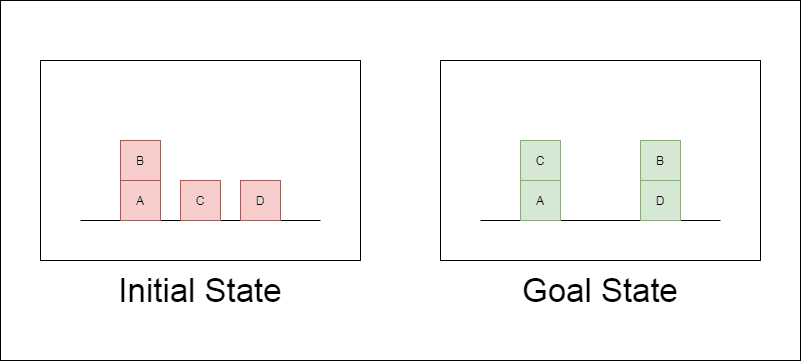
I ricercatori hanno scelto un dominio di pianificazione classico chiamato Blocksworld come terreno di prova principale. In Blocksworld, il compito è quello di riorganizzare un insieme di blocchi da una configurazione iniziale a una configurazione finale, utilizzando una serie di azioni di spostamento. Questo dominio è ideale per testare le capacità di ragionamento e di pianificazione perché:
Permette di generare problemi di complessità variabile.
Ha soluzioni chiare e verificabili dal punto di vista algoritmico.
È improbabile che sia molto rappresentato nei dati di formazione di LLM.
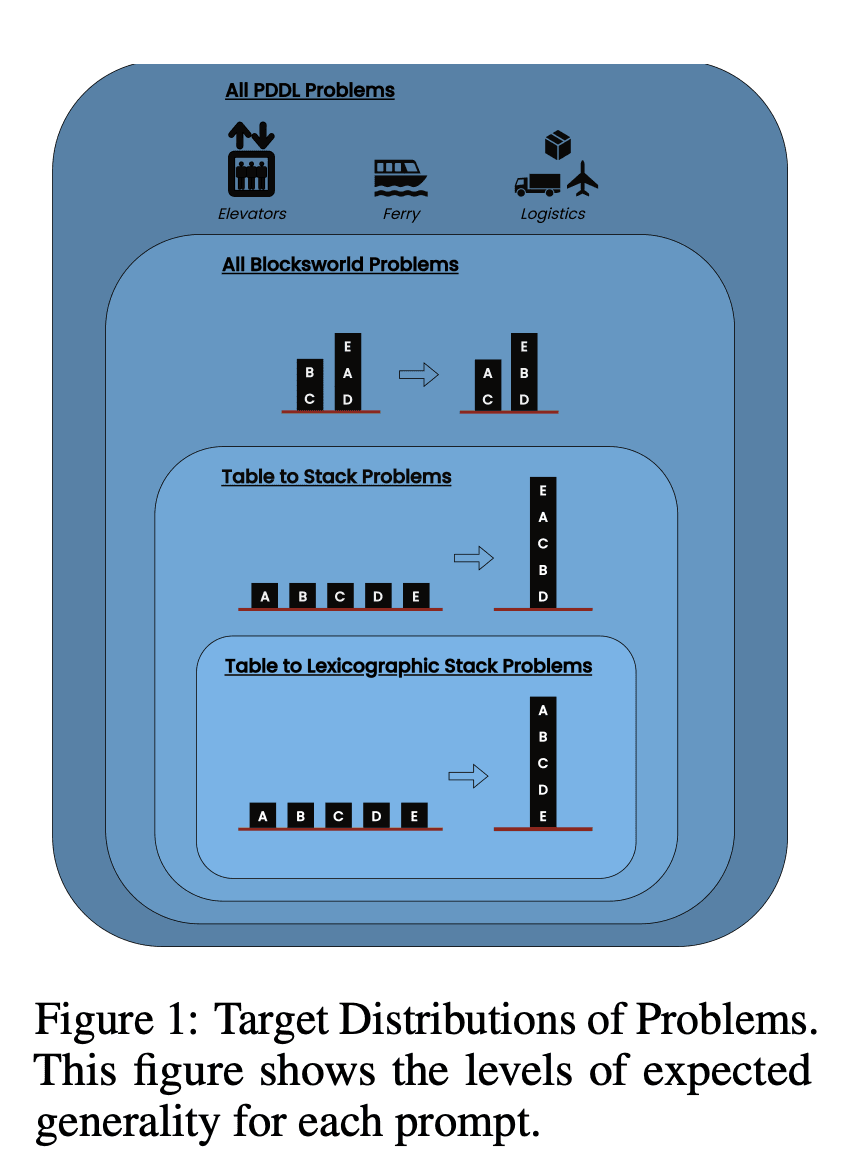
Lo studio ha esaminato tre LLM di ultima generazione: GPT-4, Claude-3-Opus e GPT-4-Turbo. Questi modelli sono stati testati utilizzando prompt di diversa specificità:
Catena di pensieri a colpo zero (Universale): Semplicemente aggiungendo "pensiamo passo dopo passo" al prompt.
Prova di progressione (specifica per la PDDL): Fornire una spiegazione generale della correttezza del piano con esempi.
Algoritmo universale di Blocksworld: Dimostrare un algoritmo generale per risolvere qualsiasi problema di Blocksworld.
Prompt di impilamento: Concentrarsi su una sottoclasse specifica di problemi di Blocksworld (table-to-stack).
Accatastamento lessicografico: Ulteriore restringimento a una particolare forma sintattica dello stato obiettivo.
Testando questi suggerimenti su problemi di complessità crescente, i ricercatori hanno voluto valutare quanto i LLM fossero in grado di generalizzare il ragionamento dimostrato negli esempi.
Svelati i risultati principali
I risultati di questo studio mettono in discussione molte delle ipotesi prevalenti sulla richiesta di CoT:
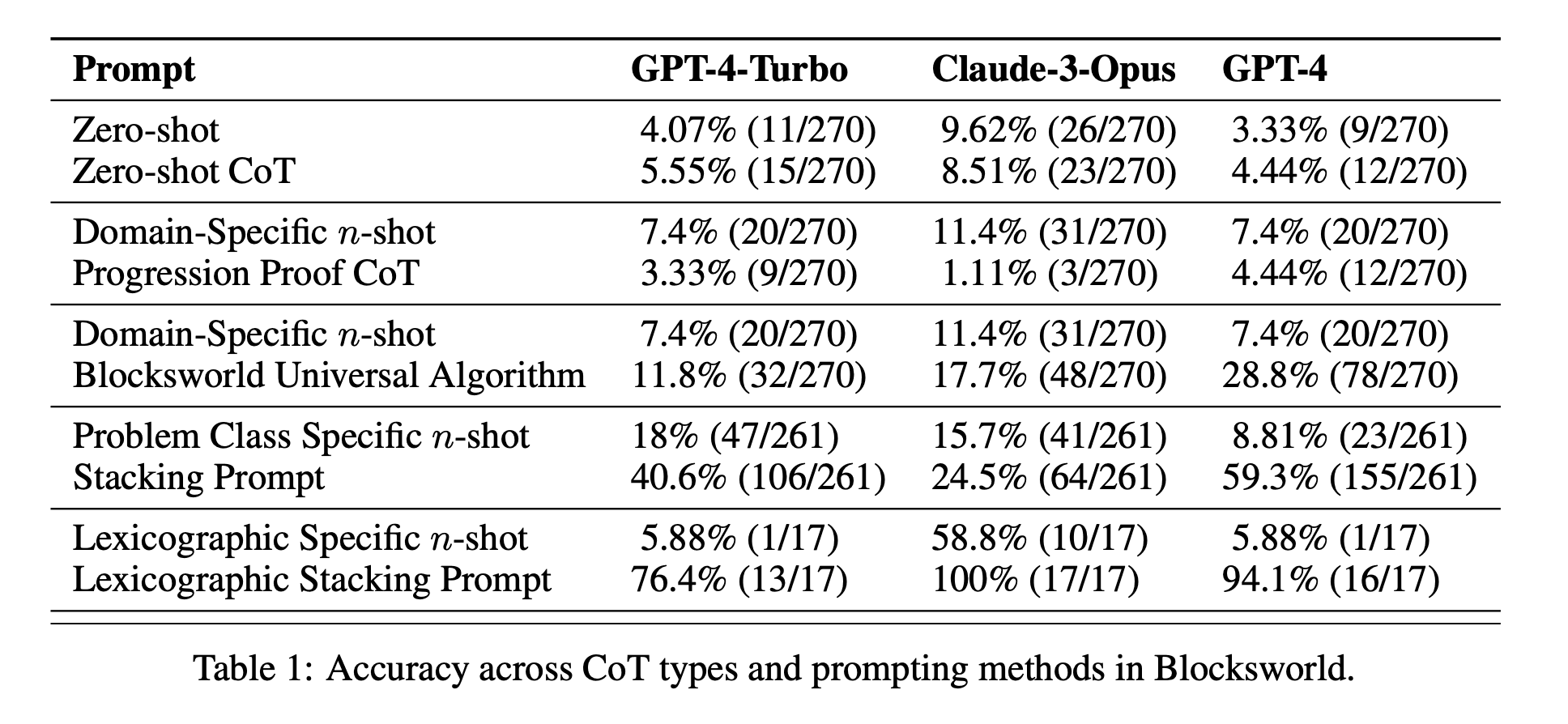
Efficacia limitata della CoT: Contrariamente a quanto affermato in precedenza, la richiesta di CoT ha mostrato miglioramenti significativi delle prestazioni solo quando gli esempi forniti erano estremamente simili al problema da interrogare. Non appena i problemi si discostano dall'esatto formato mostrato negli esempi, le prestazioni calano drasticamente.
Rapido degrado delle prestazioni: Con l'aumentare della complessità dei problemi (misurata in base al numero di blocchi coinvolti), l'accuratezza di tutti i modelli è diminuita drasticamente, indipendentemente dal prompt CoT utilizzato. Ciò suggerisce che i LLM faticano a estendere il ragionamento dimostrato in esempi semplici a scenari più complessi.
Inefficacia dei suggerimenti generali: Sorprendentemente, i suggerimenti più generali della CoT hanno spesso dato risultati peggiori rispetto a quelli standard senza esempi di ragionamento. Questo contraddice l'idea che la CoT aiuti i LLM ad apprendere strategie generalizzabili di risoluzione dei problemi.
Trade-off di specificità: Lo studio ha rilevato che i prompt altamente specifici possono raggiungere un'elevata accuratezza, ma solo su un sottoinsieme molto ristretto di problemi. Ciò evidenzia un forte compromesso tra l'aumento delle prestazioni e l'applicabilità del prompt.
Mancanza di un vero apprendimento algoritmico: I risultati suggeriscono fortemente che i LLM non stanno imparando ad applicare procedure algoritmiche generali dagli esempi di CoT. Sembrano invece affidarsi alla corrispondenza dei modelli, che si rompe rapidamente quando si trovano di fronte a problemi nuovi o più complessi.
Questi risultati hanno implicazioni significative per i professionisti dell'intelligenza artificiale e per le aziende che desiderano sfruttare i prompt della CoT nelle loro applicazioni. Suggeriscono che, sebbene la CoT possa aumentare le prestazioni in alcuni scenari ristretti, potrebbe non essere la panacea per i compiti di ragionamento complessi che molti avevano sperato.
Oltre il mondo dei blocchi: Estendere l'indagine
Per assicurarsi che i loro risultati non fossero limitati al dominio di Blocksworld, i ricercatori hanno esteso la loro indagine a diversi domini di problemi sintetici comunemente usati in precedenti studi di CoT:
Moneta a rotazione: Un compito che prevede di prevedere lo stato di una moneta dopo una serie di lanci.
Ultima LetteraConcatenazione: Un compito di elaborazione del testo che richiede la concatenazione delle ultime lettere di parole date.
Aritmetica a più fasi: Problemi di semplificazione di espressioni aritmetiche complesse.
Questi domini sono stati scelti perché consentono di generare problemi di complessità crescente, simili a quelli di Blocksworld. I risultati di questi ulteriori esperimenti sono stati sorprendentemente coerenti con i risultati di Blocksworld:
Mancanza di generalizzazione: La richiesta di CoT ha mostrato miglioramenti solo su problemi molto simili agli esempi forniti. Con l'aumentare della complessità del problema, le prestazioni si sono rapidamente ridotte a livelli paragonabili o peggiori rispetto al prompt standard.
Pattern matching sintattico: Nel compito LastLetterConcatenation, il prompt della CoT ha migliorato alcuni aspetti sintattici delle risposte (come l'uso delle lettere corrette), ma non è riuscito a mantenere l'accuratezza all'aumentare del numero di parole.
Fallimento nonostante passi intermedi perfetti: Nei compiti aritmetici, anche quando i modelli riuscivano a risolvere perfettamente tutte le possibili operazioni a una cifra, non riuscivano a generalizzare a sequenze di operazioni più lunghe.
Questi risultati rafforzano ulteriormente la conclusione che gli attuali LLM non apprendono strategie di ragionamento generalizzabili dagli esempi di CoT. Al contrario, sembrano affidarsi in larga misura a una corrispondenza superficiale dei modelli, che si rompe di fronte a problemi che si discostano dagli esempi dimostrati.
Implicazioni per lo sviluppo dell'IA
I risultati di questo studio hanno implicazioni significative per lo sviluppo dell'IA, in particolare per le imprese che lavorano su applicazioni che richiedono capacità complesse di ragionamento o pianificazione:
Rivalutazione dell'efficacia della CTF: Lo studio mette in discussione l'idea che la richiesta di CoT "sblocchi" le capacità di ragionamento generale nei LLM. Gli sviluppatori di intelligenza artificiale dovrebbero essere cauti nell'affidarsi alla CoT per compiti che richiedono un vero pensiero algoritmico o la generalizzazione a scenari nuovi.
Limiti degli attuali LLM: Nonostante le loro impressionanti capacità in molte aree, i LLM di ultima generazione hanno ancora difficoltà a ragionare in modo coerente e generalizzabile. Ciò suggerisce che potrebbero essere necessari approcci alternativi per le applicazioni che richiedono una pianificazione robusta o la risoluzione di problemi in più fasi.
Il costo dell'ingegneria tempestiva: Sebbene i suggerimenti di CoT altamente specifici possano dare buoni risultati per insiemi di problemi ristretti, l'impegno umano richiesto per creare questi suggerimenti può superare i benefici, soprattutto in considerazione della loro limitata generalizzabilità.
Ripensare le metriche di valutazione: Lo studio evidenzia l'importanza di testare i modelli di intelligenza artificiale su problemi di varia complessità e struttura. Affidarsi esclusivamente a set di test statici può portare a sovrastimare le reali capacità di ragionamento di un modello.
Il divario tra percezione e realtà: C'è una discrepanza significativa tra le capacità di ragionamento percepite dei LLM (spesso antropomorfizzate nel discorso popolare) e le loro reali capacità, come dimostrato in questo studio.
Raccomandazioni per gli operatori dell'IA
Alla luce di queste considerazioni, ecco alcune raccomandazioni chiave per i professionisti dell'IA e per le imprese che lavorano con i LLM:
Pratiche di valutazione rigorose:
Implementare framework di test in grado di generare problemi di varia complessità.
Non affidatevi esclusivamente a set di test statici o a benchmark che possono essere rappresentati nei dati di formazione.
Valutare le prestazioni su uno spettro di variazioni del problema per valutare l'effettiva generalizzazione.
Aspettative realistiche per la CdT:
Usare il prompt della CoT con giudizio, comprendendo i suoi limiti nella generalizzazione.
Tenete presente che i miglioramenti delle prestazioni ottenuti con la CoT possono essere limitati a gruppi di problemi ristretti.
Considerate il compromesso tra lo sforzo di progettazione immediato e i potenziali guadagni di prestazioni.
Approcci ibridi:
Per compiti di ragionamento complessi, si può considerare di combinare gli LLM con approcci algoritmici tradizionali o con moduli di ragionamento specializzati.
Esplorare metodi che possano sfruttare i punti di forza dei LLM (ad esempio, la comprensione del linguaggio naturale) compensando le loro debolezze nel ragionamento algoritmico.
Trasparenza nelle applicazioni di IA:
Comunicare chiaramente i limiti dei sistemi di IA, soprattutto quando si tratta di compiti di ragionamento o di pianificazione.
Evitare di sopravvalutare le capacità degli LLM, in particolare nelle applicazioni critiche per la sicurezza o ad alto rischio.
Ricerca e sviluppo continui:
Investire nella ricerca per migliorare le reali capacità di ragionamento dei sistemi di IA.
Esplorare architetture o metodi di formazione alternativi che possano portare a una generalizzazione più robusta in compiti complessi.
Messa a punto specifica del dominio:
Per domini di problemi ristretti e ben definiti, si può pensare di affinare i modelli su dati e modelli di ragionamento specifici del dominio.
Tenete presente che questa messa a punto può migliorare le prestazioni all'interno del dominio, ma non può generalizzarsi al di fuori di esso.
Seguendo queste raccomandazioni, i professionisti dell'IA possono sviluppare applicazioni di IA più robuste e affidabili, evitando le potenziali insidie associate alla sopravvalutazione delle capacità di ragionamento degli attuali LLM. Le intuizioni di questo studio servono a ricordare l'importanza di una valutazione critica e realistica nel campo dell'IA in rapida evoluzione.
Il bilancio
Questo studio innovativo sulla sollecitazione della catena del pensiero nei compiti di pianificazione sfida la nostra comprensione delle capacità di LLM e richiede una rivalutazione delle attuali pratiche di sviluppo dell'IA. Rivelando i limiti della CoT nella generalizzazione a problemi complessi, sottolinea la necessità di test più rigorosi e di aspettative realistiche nelle applicazioni di IA.
Per gli operatori dell'IA e le imprese, questi risultati evidenziano l'importanza di combinare i punti di forza dell'LLM con approcci di ragionamento specializzati, di investire in soluzioni specifiche per il dominio, ove necessario, e di mantenere la trasparenza sui limiti dei sistemi di IA. La comunità dell'intelligenza artificiale deve concentrarsi sullo sviluppo di nuove architetture e metodi di addestramento in grado di colmare il divario tra la corrispondenza dei modelli e il vero ragionamento algoritmico. Questo studio serve a ricordare che, nonostante i notevoli progressi compiuti dalle LLM, il raggiungimento di capacità di ragionamento simili a quelle umane rimane una sfida continua nella ricerca e nello sviluppo dell'IA.


