
What is Few Shot Learning?



In AI, the ability to learn efficiently from limited data has become crucial. Enter Few Shot Learning, an approach that’s improving how AI models acquire knowledge and adapt to new tasks.
But what exactly is Few Shot Learning?
Defining Few Shot Learning
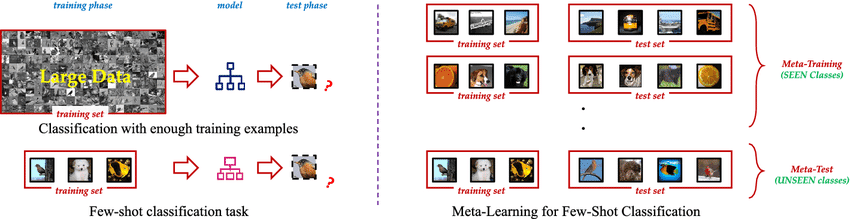
Few Shot Learning is an innovative machine learning paradigm that enables AI models to learn new concepts or tasks from only a few examples. Unlike traditional supervised learning methods that require vast amounts of labeled training data, Few Shot Learning techniques allow models to generalize effectively using just a small number of samples. This approach mimics the human ability to quickly grasp new ideas without the need for extensive repetition.
The essence of Few Shot Learning lies in its ability to leverage prior knowledge and adapt rapidly to new scenarios. By using techniques such as meta-learning, where the model “learns how to learn,” Few Shot Learning algorithms can tackle a wide range of tasks with minimal additional training. This flexibility makes it an invaluable tool in scenarios where data is scarce, expensive to obtain, or constantly evolving.
The Challenge of Data Scarcity in AI
Not all data is created equal, and high-quality, labeled data can be a rare and precious commodity. This scarcity poses a significant challenge for traditional supervised learning approaches, which typically require thousands or even millions of labeled examples to achieve satisfactory performance.
The data scarcity problem is particularly acute in specialized domains such as healthcare, where rare conditions may have limited documented cases, or in rapidly changing environments where new categories of data emerge frequently. In these scenarios, the time and resources required to collect and label large datasets can be prohibitive, creating a bottleneck in AI development and deployment.
Few Shot Learning vs. Traditional Supervised Learning
To fully appreciate the impact of Few Shot Learning, it’s essential to understand how it differs from traditional supervised learning methods and why this distinction matters in real-world applications.
Limitations of Conventional Approaches
Traditional supervised learning relies on a simple yet data-hungry principle: the more examples a model sees during training, the better it becomes at recognizing patterns and making predictions. While this approach has led to remarkable achievements in various fields, it comes with several significant drawbacks:
Data Dependency: Conventional models often struggle when faced with limited training data, leading to overfitting or poor generalization.
Inflexibility: Once trained, these models typically perform well only on the specific tasks they were trained for, lacking the ability to quickly adapt to new, related tasks.
Resource Intensity: Collecting and labeling large datasets is time-consuming, expensive, and often impractical, especially in specialized or rapidly evolving domains.
Continuous Updating: In dynamic environments where new categories of data frequently emerge, traditional models may require constant retraining to stay relevant.
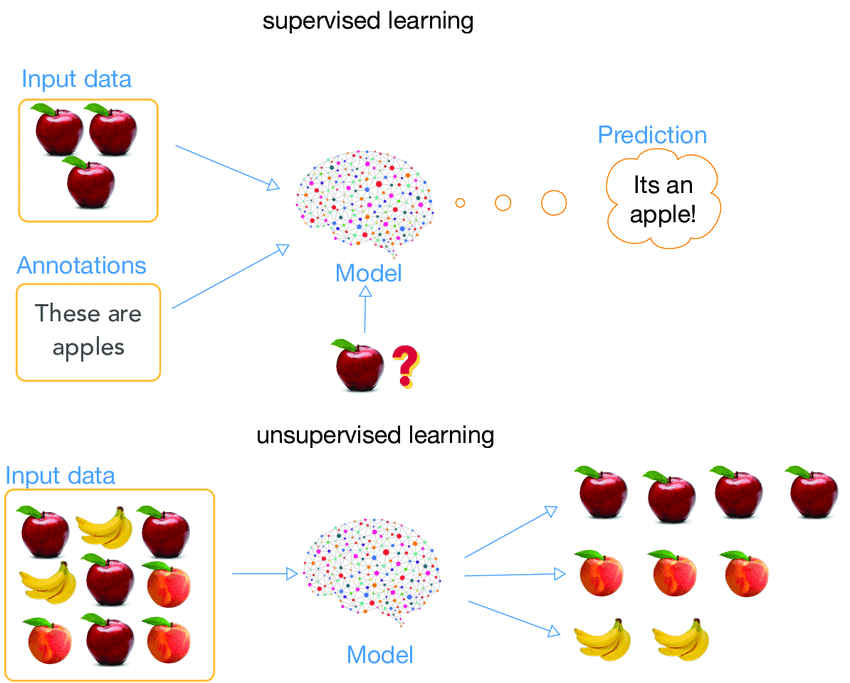
How Few Shot Learning Addresses These Challenges
Few Shot Learning offers a paradigm shift in tackling these limitations, providing a more flexible and efficient approach to machine learning:
Sample Efficiency: By leveraging meta-learning techniques, Few Shot Learning models can generalize from just a few examples, making them highly effective in data-scarce scenarios.
Rapid Adaptation: These models are designed to quickly adapt to new tasks or categories, often requiring only a small number of examples to achieve good performance.
Resource Optimization: With the ability to learn from limited data, Few Shot Learning reduces the need for extensive data collection and labeling, saving time and resources.
Continuous Learning: Few Shot Learning approaches are inherently more suitable for continuous learning scenarios, where models need to incorporate new knowledge without forgetting previously learned information.
Versatility: From computer vision tasks like few shot image classification to natural language processing applications, Few Shot Learning demonstrates remarkable versatility across various domains.
By addressing these challenges, Few Shot Learning opens up new possibilities in AI development, enabling the creation of more adaptable and efficient models.
The Spectrum of Sample-Efficient Learning
There’s a fascinating spectrum of approaches that aim to minimize the amount of training data required. This spectrum encompasses Zero Shot Learning, One Shot Learning, and Few Shot Learning, each offering unique capabilities in tackling the challenge of learning from limited examples.
Zero Shot Learning: Learning without examples
At the extreme end of sample efficiency lies Zero Shot Learning. This remarkable approach enables models to recognize or classify instances of classes they have never seen during training. Instead of relying on labeled examples, Zero Shot Learning leverages auxiliary information, such as textual descriptions or attribute-based representations, to make predictions about unseen classes.
For instance, a Zero Shot Learning model might be able to classify a new animal species it has never encountered before, based solely on a textual description of its characteristics. This capability is particularly valuable in scenarios where obtaining labeled examples for all possible classes is impractical or impossible.
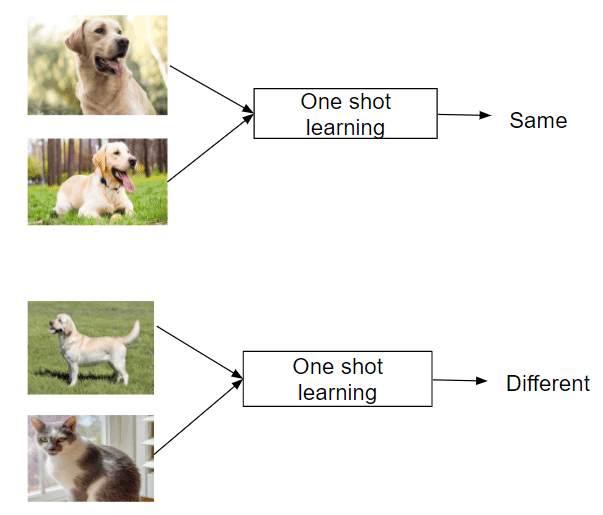
One Shot Learning: Learning from a single instance
Moving along the spectrum, we encounter One Shot Learning, a subset of Few Shot Learning where the model learns to recognize new classes from just a single example. This approach draws inspiration from human cognition, mimicking our ability to quickly grasp new concepts after seeing them only once.
One Shot Learning techniques often rely on comparing new instances to the single example they’ve seen, using sophisticated similarity measures. This method has shown remarkable success in areas like facial recognition, where a system can learn to identify a person from a single photo.
Few Shot Learning: Mastering tasks with minimal data
Few Shot Learning extends the concept of One Shot Learning to scenarios where a small number (typically 2-5) of labeled examples are available for each new class. This approach strikes a balance between the extreme data efficiency of Zero and One Shot Learning and the more data-hungry traditional supervised learning methods.
Few Shot Learning techniques enable models to rapidly adapt to new tasks or classes with only a few examples, making them invaluable in domains where data scarcity is a significant challenge. By leveraging meta-learning strategies, these models learn how to learn, allowing them to generalize effectively from limited data.
Core Concepts in Few Shot Learning
To fully grasp the power of Few Shot Learning, it’s essential to understand some fundamental concepts that underpin this innovative approach.
N-way K-shot classification explained
At the heart of Few Shot Learning lies the N-way K-shot classification framework. This terminology describes the structure of a Few Shot Learning task:
N-way refers to the number of classes the model needs to distinguish between in a given task.
K-shot indicates the number of examples provided for each class.
For instance, a 5-way 3-shot classification task would involve distinguishing between 5 different classes, with 3 examples provided for each class. This framework allows researchers and practitioners to systematically evaluate and compare different Few Shot Learning algorithms under consistent conditions.
The role of support and query sets
In Few Shot Learning, data is typically organized into two distinct sets:
Support Set: This contains the few labeled examples (K shots) for each of the N classes. The model uses this set to learn or adapt to the new task.
Query Set: This consists of additional examples from the same N classes, which the model must classify correctly. The model’s performance on the query set determines how well it has learned from the limited examples in the support set.
This structure enables the model to learn from a small number of examples (the support set) and then immediately test its ability to generalize to new, unseen examples (the query set) within the same task.
Approaches to Few Shot Learning
Researchers have developed various approaches to tackle the challenges of Few Shot Learning, each with its unique strengths and applications.
Data-level techniques
Data-level approaches focus on augmenting or generating additional training data to supplement the limited examples available. These techniques include:
Data augmentation: Applying transformations to existing samples to create new, synthetic examples.
Generative models: Using advanced AI models to generate realistic, artificial examples based on the limited real data available.
These methods aim to increase the effective size of the training set, helping models learn more robust representations from limited data.
Parameter-level strategies
Parameter-level approaches focus on optimizing the model’s parameters to enable quick adaptation to new tasks. These strategies often involve:
Initialization techniques: Finding optimal starting points for model parameters that allow rapid adaptation to new tasks.
Regularization methods: Constraining the model’s parameter space to prevent overfitting on the limited data available.
These approaches aim to make the model more flexible and adaptable, enabling it to learn effectively from just a few examples.
Metric-based methods
Metric-based Few Shot Learning techniques focus on learning a distance or similarity function that can effectively compare new examples to the limited labeled data available. Popular metric-based methods include:
Siamese Networks: Learning to compute similarity scores between pairs of inputs.
Prototypical Networks: Computing class prototypes and classifying new examples based on their distance to these prototypes.
These methods excel at tasks like few shot image classification by learning to measure similarities in a way that generalizes well to new classes.
Gradient-based meta-learning
Gradient-based meta-learning approaches, exemplified by Model Agnostic Meta-Learning (MAML), aim to learn how to learn. These methods typically involve a two-level optimization process:
Inner loop: Rapid adaptation to a specific task using a few gradient steps.
Outer loop: Optimization of the model’s initial parameters to enable quick adaptation across a range of tasks.
By learning a set of parameters that can be quickly fine-tuned for new tasks, these approaches enable models to adapt rapidly to new scenarios with only a few examples.
Each of these approaches to Few Shot Learning offers unique advantages, and researchers often combine multiple techniques to create more powerful and flexible models. As we continue to push the boundaries of AI, these sample-efficient learning methods are playing an increasingly crucial role in developing more adaptable and efficient machine learning systems.
Applications Across Industries
Few Shot Learning is not just a theoretical concept; it’s finding practical applications across various industries, changing how AI tackles real-world challenges.
Computer Vision: From image classification to object detection
In the realm of computer vision, Few Shot Learning is pushing the boundaries of what’s possible with limited data:
Image Classification: Few shot image classification techniques enable models to recognize new object categories from just a handful of examples, crucial for applications like wildlife monitoring or industrial quality control.
Object Detection: Few shot object detection methods are enhancing systems’ ability to locate and identify novel objects in images or video streams, with applications ranging from autonomous vehicles to security systems.
Facial Recognition: One shot learning approaches have significantly improved facial recognition systems, allowing them to identify individuals from a single reference image.
Natural Language Processing: Adapting language models
Few Shot Learning is also making waves in Natural Language Processing (NLP), enabling more flexible and efficient language models:
Text Classification: Models can quickly adapt to new text categories or sentiment analysis tasks with minimal examples, crucial for applications like content moderation or customer feedback analysis.
Machine Translation: Few shot techniques are enhancing translation systems’ ability to handle low-resource languages or domain-specific terminology.
Question Answering: Few shot learning approaches are improving AI’s ability to answer questions on new topics with limited training data.
Robotics: Quick adaptation in new environments
In robotics, the ability to learn and adapt quickly is crucial. Few Shot Learning is enabling robots to:
Master new tasks with minimal demonstrations, enhancing their versatility in manufacturing and service roles.
Adapt to new environments or unexpected situations, crucial for deployment in dynamic real-world settings.
Learn new grasping techniques for novel objects, expanding their utility in warehousing and logistics.
Healthcare: Tackling rare conditions with limited data
Few Shot Learning is particularly valuable in healthcare, where data for rare conditions is often scarce:
Disease Diagnosis: Models can learn to identify rare diseases from limited medical imaging data, potentially speeding up diagnosis and treatment.
Drug Discovery: Few shot techniques are aiding in the identification of potential drug candidates for rare diseases, where traditional data-heavy approaches may fall short.
Personalized Medicine: By quickly adapting to individual patient data, Few Shot Learning models are contributing to more personalized treatment plans.
Challenges and Future Directions in Few Shot Learning
While Few Shot Learning has made remarkable strides, several challenges and exciting research directions remain.
Current limitations:
Generalization across domains: Many Few Shot Learning models struggle when the distribution of the new task differs significantly from the training tasks.
Scalability: Some approaches, particularly metric-based methods, can become computationally expensive as the number of classes increases.
Robustness: Few Shot Learning models can be sensitive to the choice of support set examples, potentially leading to inconsistent performance.
Interpretability: As with many deep learning approaches, the decision-making process in Few Shot Learning models can be opaque, limiting their applicability in sensitive domains.
Promising research areas:
Cross-domain Few Shot Learning: Developing methods that can generalize across vastly different domains, enhancing the versatility of Few Shot Learning models.
Incorporating unlabeled data: Exploring semi-supervised Few Shot Learning approaches to leverage the abundance of unlabeled data available in many domains.
Continual Few Shot Learning: Creating models that can continually learn new tasks without forgetting previously learned information, mimicking human-like learning more closely.
Explainable Few Shot Learning: Developing interpretable Few Shot Learning models to enhance trust and applicability in critical domains like healthcare and finance.
Few Shot Learning in reinforcement learning: Expanding Few Shot Learning principles to reinforcement learning scenarios for quicker adaptation in complex environments.
The Bottom Line
Few Shot Learning has emerged as a transformative force, reshaping how we approach machine learning challenges. By enabling AI systems to learn efficiently from limited data, Few Shot Learning is bridging the gap between human-like cognitive flexibility and the data-hungry nature of traditional deep learning. From enhancing computer vision and natural language processing to advancing robotics and healthcare, Few Shot Learning is proving its worth across diverse industries, opening up new frontiers of innovation.
As researchers continue to tackle current limitations and explore promising directions, we can anticipate even more powerful and versatile AI systems in the future. The ability to learn and adapt quickly from just a few examples will be crucial as we move towards more general artificial intelligence, aligning machine learning more closely with human cognitive abilities and unlocking new possibilities in our rapidly changing world.


