
Understanding LLM Pricing Structures: Inputs, Outputs, and Context Windows



For enterprise AI strategies, understanding large language model (LLM) pricing structures is crucial for effective cost management. The operational costs associated with LLMs can quickly escalate without proper oversight, potentially leading to unexpected cost spikes that can derail budgets and hinder widespread adoption. T
his blog post delves into the key components of LLM pricing structures, providing insights that will help you optimize your LLM usage and control expenses.
LLM pricing typically revolves around three main components: input tokens, output tokens, and context windows. Each of these elements plays a significant role in determining the overall cost of utilizing LLMs in your applications. By gaining a thorough understanding of these components, you’ll be better equipped to make informed decisions about model selection, usage patterns, and optimization strategies.
Basic Components of LLM Pricing
Input Tokens
Input tokens represent the text fed into the LLM for processing. This includes your prompts, instructions, and any additional context provided to the model. The number of input tokens directly impacts the cost of each API call, as more tokens require more computational resources to process.
Output Tokens
Output tokens are the text generated by the LLM in response to your input. The pricing for output tokens often differs from input tokens, reflecting the additional computational effort required for text generation. Managing output token usage is crucial for controlling costs, especially in applications that generate large volumes of text.
Context Windows
Context windows refer to the amount of previous text the model can consider when generating responses. Larger context windows allow for more comprehensive understanding but come at a higher cost due to increased token usage and computational requirements.
Input Tokens: What They Are and How They’re Charged
Input tokens are the fundamental units of text processed by an LLM. They typically correspond to parts of words, with common words often represented by a single token and less common words split into multiple tokens. For example, the sentence “The quick brown fox” might be tokenized as [“The”, “quick”, “bro”, “wn”, “fox”], resulting in 5 input tokens.
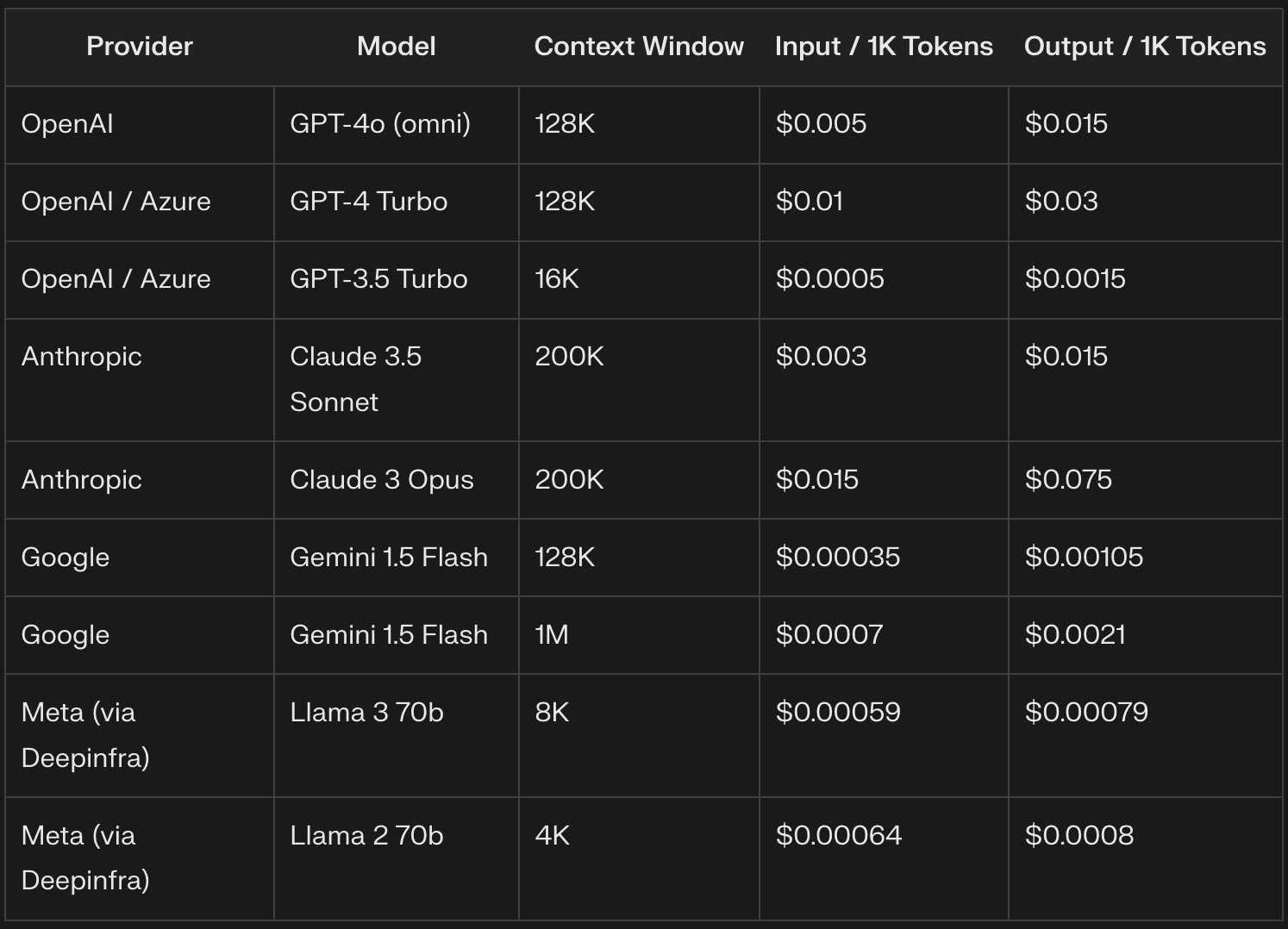
LLM providers often charge for input tokens based on a per-thousand tokens rate. For instance, GPT-4o charges $5 per 1 million input tokens, which equates to $0.005 per 1,000 input tokens. The exact pricing can vary significantly between providers and model versions, with more advanced models generally commanding higher rates.
To manage LLM costs effectively, consider these strategies for optimizing input token usage:
Craft concise prompts: Eliminate unnecessary words and focus on clear, direct instructions.
Use efficient encoding: Choose an encoding method that represents your text with fewer tokens.
Implement prompt templates: Develop and reuse optimized prompt structures for common tasks.
By carefully managing your input tokens, you can significantly reduce the costs associated with LLM usage while maintaining the quality and effectiveness of your AI applications.
Output Tokens: Understanding the Costs
Output tokens represent the text generated by the LLM in response to your input. Similar to input tokens, output tokens are calculated based on the model’s tokenization process. However, the number of output tokens can vary significantly depending on the task and the model’s configuration. For instance, a simple question might generate a brief response with few tokens, while a request for a detailed explanation could result in hundreds of tokens.
LLM providers often price output tokens differently from input tokens, typically at a higher rate due to the computational complexity of text generation. For example, OpenAI charges $15 per 1 million tokens ($0.015 per 1,000 tokens) for GPT-4o.
To optimize output token usage and control costs:
Set clear output length limits in your prompts or API calls.
Use techniques like “few-shot learning” to guide the model towards more concise responses.
Implement post-processing to trim unnecessary content from LLM outputs.
Consider caching frequently requested information to reduce redundant LLM calls.
Context Windows: The Hidden Cost Driver
Context windows determine how much previous text the LLM can consider when generating a response. This feature is crucial for maintaining coherence in conversations and allowing the model to reference earlier information. The size of the context window can significantly impact the model’s performance, especially for tasks requiring long-term memory or complex reasoning.
Larger context windows directly increase the number of input tokens processed by the model, leading to higher costs. For example:
A model with a 4,000-token context window processing a 3,000-token conversation will charge for all 3,000 tokens.
The same conversation with an 8,000-token context window might charge for 7,000 tokens, including earlier parts of the conversation.
This scaling can lead to substantial cost increases, especially for applications handling lengthy dialogues or document analysis.
To optimize context window usage:
Implement dynamic context sizing based on task requirements.
Use summarization techniques to condense relevant information from longer conversations.
Employ sliding window approaches for processing long documents, focusing on the most relevant sections.
Consider using smaller, specialized models for tasks that don’t require extensive context.
By carefully managing context windows, you can strike a balance between maintaining high-quality outputs and controlling LLM costs. Remember, the goal is to provide sufficient context for the task at hand without unnecessarily inflating token usage and associated expenses.
Future Trends in LLM Pricing
As the LLM landscape evolves, we may see shifts in pricing structures:
Task-based pricing: Models charged based on the complexity of the task rather than token count.
Subscription models: Flat-rate access to LLMs with usage limits or tiered pricing.
Performance-based pricing: Costs tied to the quality or accuracy of outputs rather than just quantity.
Impact of technological advancements on costs
Ongoing research and development in AI may lead to:
More efficient models: Reduced computational requirements leading to lower operational costs.
Improved compression techniques: Enhanced methods for reducing input and output token counts.
Edge computing integration: Local processing of LLM tasks, potentially reducing cloud computing costs.
The Bottom Line
Understanding LLM pricing structures is essential for effective cost management in enterprise AI applications. By grasping the nuances of input tokens, output tokens, and context windows, organizations can make informed decisions about model selection and usage patterns. Implementing strategic cost management techniques, such as optimizing token usage and leveraging caching, can lead to significant savings.
As LLM technology continues to evolve, staying informed about pricing trends and emerging optimization strategies will be crucial for maintaining cost-effective AI operations. Remember, successful LLM cost management is an ongoing process that requires continuous monitoring, analysis, and adaptation to ensure maximum value from your AI investments.
If you want to learn about how your enterprise can more effectively leverage LLM pricing structures, feel free to reach out!


