
How to Build Your Enterprises LLM Stack: Our 4-Tool Stack + Framework



Large language models (LLMs) have emerged as a key to building intelligent enterprise applications. However, harnessing the power of these language models requires a robust and efficient LLM application stack. At Skim AI, our LLM app stack enables us to create powerful applications with advanced natural language interaction capabilities. Our stack comprises carefully selected tools and frameworks, like LLM APIs, LangChain, and vector databases.
With such a tech stack, developers can seamlessly integrate domain-specific data, fine-tune models, create efficient data pipelines for retrieving contextual data, and more. This empowers businesses to build applications that understand and respond to user queries with unprecedented accuracy and context-awareness. At the same time, one of the main techniques to go along with this stack is to utilize existing tools and frameworks provided by the various components. This allows developers to focus on building applications rather than creating tools from scratch, saving valuable time and effort.
An LLM API Like GPT, Claude, Llama, or Mistral
At the core of your LLM application stack should be an LLM API. LLM APIs provide a way to integrate powerful language models into your applications without the need to train or host the models yourself. They act as a bridge between your software and the complex algorithms that power language models, enabling you to add advanced natural language processing capabilities to your applications with minimal effort.
One of the key advantages of using an LLM API is the ability to leverage state-of-the-art language models that have been trained on vast amounts of data. These models, such as GPT, Claude, Mistral, and Llama, are capable of understanding and generating human-like text with remarkable accuracy and fluency. By making API calls to these models, you can quickly add a wide range of capabilities, including text generation, sentiment analysis, question-answering, and much more to your applications.
Factors to Consider When Choosing an LLM API
When choosing an LLM API for your stack, there are several factors to consider:
Performance and accuracy: Ensure that the API can handle your workload and provide reliable results.
Customization and flexibility: Consider whether you need to fine-tune the model for your specific use case or integrate it with other components of your stack.
Scalability: If you anticipate high volumes of requests, make sure the API can scale accordingly.
Support and community: Evaluate the level of support and the size of the community around the API, as this can impact the long-term viability of your application.
To make effective use of an LLM API, it’s important to understand its key components and capabilities. At the heart of most LLM APIs are deep neural networks, typically based on transformer architectures, that are trained on massive amounts of text data. These models are accessed via an API interface, which handles tasks like authentication, request routing, and response formatting. LLM APIs also often include additional components for data processing, such as tokenization and normalization, as well as tools for fine-tuning and customization.
When integrating an LLM API into your application stack, it’s important to consider factors like data privacy and security. Depending on your use case, you may need to ensure that sensitive data is not sent to the API provider or used for model training. You should also carefully evaluate the cost structure of the API, as usage-based pricing can quickly add up for high-volume applications.
Despite these challenges, the benefits of using an LLM API are clear. By providing a simple, flexible way to integrate advanced language capabilities into your applications, LLM APIs can help you create more engaging, intelligent, and user-friendly software. Whether you’re building a chatbot, a content creation tool, or a knowledge management system, an LLM API is a crucial addition to your enterprise application stack.
LangChain
After selecting an LLM API for your LLM application stack, the next component to consider is LangChain. LangChain is a powerful framework designed to simplify the process of building applications on top of large language models. It provides a standardized interface for interacting with various LLM APIs, making it easier to integrate them into your LLM tech stack.
One of the key benefits of using LangChain is its modular architecture. LangChain consists of several components, such as prompts, chains, agents, and memory, which can be combined to create complex workflows. This modularity allows you to build applications that can handle a wide range of tasks, from simple question-answering to more advanced use cases like content generation and data analysis, enabling natural language interaction with your domain-specific data.
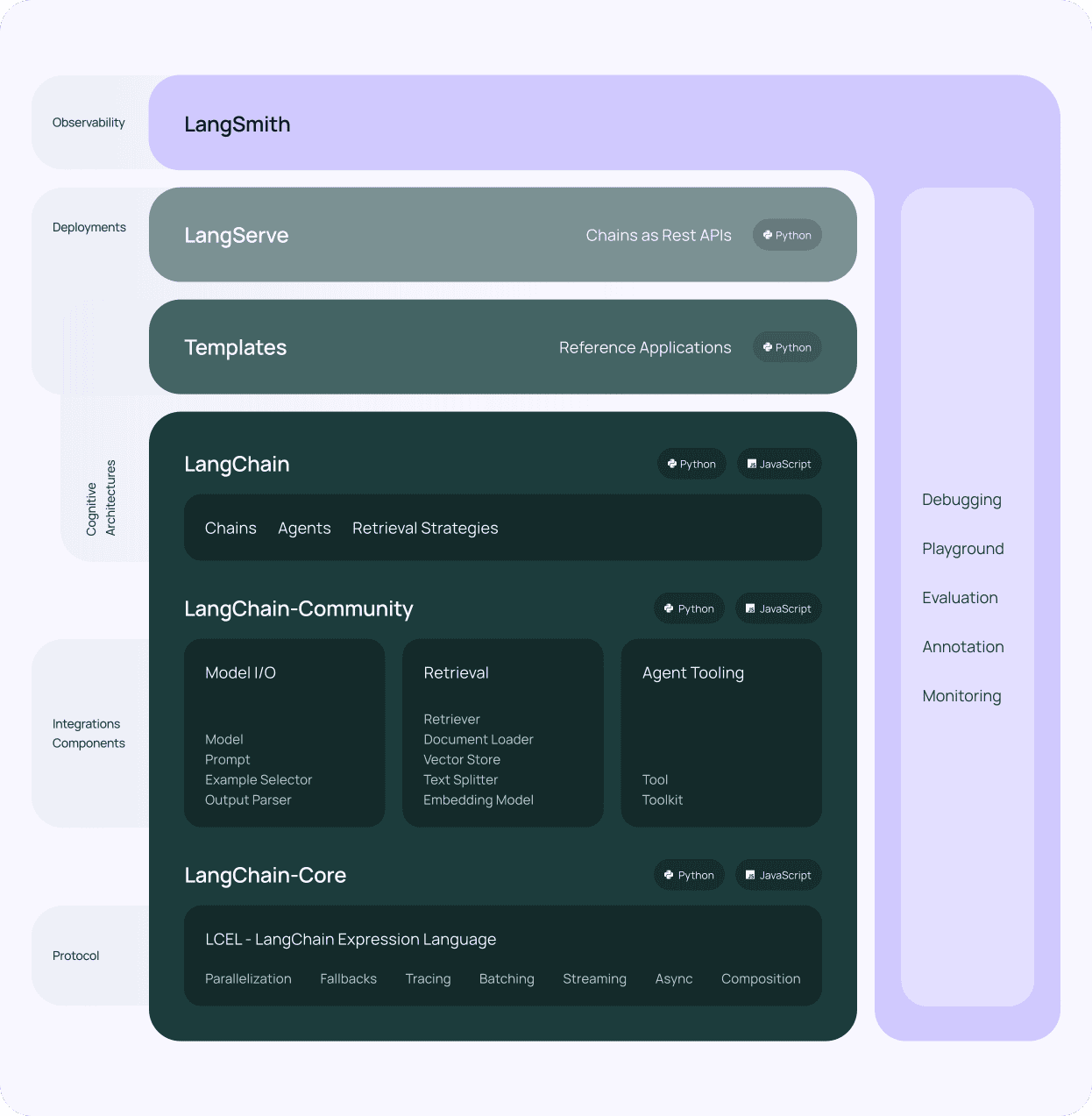
LangChain’s Various Tools and Support
LangChain also provides a variety of tools and utilities that streamline working with LLMs. For instance, it offers tools for working with embeddings, which are numerical representations of text used for tasks like semantic search and clustering. Additionally, LangChain includes utilities for managing prompts, which are the input strings used to guide the behavior of language models.
Another crucial feature of LangChain is its support for vector databases. By integrating with vector databases like Chroma (which is what we use), LangChain enables you to build applications that can efficiently store and retrieve large amounts of data. This integration allows you to create knowledge-intensive applications that can draw upon a wide range of information sources, enhancing the retrieval of contextual data for your LLM app stack.
LangChain also boasts an active community of developers and users who contribute to its ongoing development. This community offers a wealth of resources, including documentation, tutorials, and pre-built components that can accelerate the development of LLM-powered applications. Moreover, LangChain is compatible with open-source models, making it a versatile tool for your LLM tech stack.
LangChain is a vital component of any enterprise LLM application stack. Its modular design, powerful tools, and active community make it an indispensable tool for building sophisticated language-based applications. By leveraging LangChain alongside an LLM API and other components like vector databases, you can create enterprise applications that understand and generate human language with unparalleled accuracy and fluency, enabling seamless natural language interaction with your private data and domain-specific information.
A Vector Database Like Chroma
In addition to an LLM API and LangChain, another essential component of your LLM app stack is a vector database. Vector databases are specialized data stores optimized for storing and searching high-dimensional vectors, such as embeddings generated by large language models. By integrating a vector database into your LLM tech stack, you can enable fast, efficient retrieval of relevant data based on semantic similarity.
Chroma is a popular open-source choice for a vector database in LLM application stacks, and we use it here at Skim AI. It is designed to work seamlessly with LangChain and other components of your stack, providing a robust and scalable solution for storing and retrieving embeddings.
One of the key advantages of using Chroma is its ability to handle large volumes of data efficiently. Chroma uses advanced indexing techniques to enable fast similarity search, even on massive datasets. This makes it an ideal choice for applications that need to store and search through large amounts of textual data, such as document repositories, knowledge bases, and content management systems.
Another benefit of Chroma is its flexibility and ease of use. Chroma provides a simple, intuitive API for storing and retrieving embeddings, making it easy to integrate into your LLM application stack. It also supports various similarity metrics, such as cosine similarity and Euclidean distance, allowing you to choose the most appropriate metric for your specific use case.
Chroma also offers advanced features like filtering and metadata support. You can store additional metadata alongside your embeddings, such as document IDs, timestamps, or custom attributes. This metadata can be used to filter search results, enabling more precise and targeted retrieval of contextual data.

Integrating Chroma Into Your Enterprise LLM Stack
Integrating Chroma into your LLM app stack is straightforward, thanks to its compatibility with LangChain and other popular tools and frameworks. LangChain provides built-in support for Chroma, making it easy to store and retrieve embeddings generated by your language models. This integration allows you to build powerful retrieval mechanisms that can quickly surface relevant information based on natural language interaction.
Using a vector database like Chroma in conjunction with LLMs opens up new possibilities for building intelligent, context-aware applications. By leveraging the power of embeddings and similarity search, you can create applications that can understand and respond to user queries with unprecedented accuracy and relevance. This is particularly valuable for domains like customer support, content recommendation, and knowledge management, where surfacing the right information at the right time is critical.
When combined with LangChain and an LLM API, Chroma forms a powerful foundation for building intelligent, data-driven applications that can transform the way we interact with enteprise data and domain-specific information.
crewAI for Multi-Agent Systems
crewAI is another powerful tool that you can add to your LLM app stack to enhance the capabilities of your applications. crewAI is a framework that enables you to create multi-agent systems, where multiple AI agents work together to accomplish complex tasks. By integrating crewAI into your stack, you can build applications that can handle more sophisticated workflows and decision-making processes, further enhancing the natural language interaction capabilities of your enterprise LLM application stack.
At its core, crewAI is designed to facilitate collaboration between multiple AI agents, each with its own specific role and expertise. These agents can communicate and coordinate with each other to break down complex problems into smaller, more manageable subtasks. This approach allows you to create applications that can tackle a wide range of real-world challenges, from customer support and content creation to data analysis and decision support, all while leveraging the power of large language models.

Leveraging the Power of Specialization
One of the key advantages of using crewAI in your LLM tech stack is its ability to leverage the power of specialization. By assigning specific roles and tasks to different agents, you can create a system that is more efficient and effective than a single, monolithic AI model. Each agent can be trained and optimized for its particular task, allowing it to perform at a higher level than a general-purpose model, and enabling more targeted retrieval of contextual data from your domain-specific datasets.
crewAI also provides a flexible and extensible architecture that allows you to easily integrate different types of agents into your system. This includes agents based on language models, as well as agents that use other AI techniques such as computer vision, speech recognition, or reinforcement learning. By combining these different types of agents, you can create applications that can perceive, understand, and interact with the world in more natural and intuitive ways, further enhancing the natural language interaction capabilities of your LLM application stack.
Integrating crewAI into your LLM app stack is made easier by its compatibility with other popular tools and frameworks, such as LangChain and vector databases. This allows you to create end-to-end workflows that can handle tasks from data ingestion and processing to natural language interaction and decision-making, all while leveraging the power of open-source models and frameworks.
Using crewAI in combination with other components of your LLM tech stack can help you to unlock new possibilities for building intelligent, multi-agent systems that can handle complex real-world tasks. By leveraging the power of specialization and collaboration, you can create applications that are more efficient, effective, and user-friendly than traditional single-model approaches.
Unlocking the Power of LLMs with the Right Application Stack
Building intelligent, context-aware applications that leverage the power of large language models requires a well-designed LLM application stack. By combining powerful tools like LLM APIs, LangChain, vector databases like Chroma, and multi-agent frameworks like crewAI, you can create incredibly powerful and valuable workflows.
This stack allows you to seamlessly integrate domain-specific data, enable efficient retrieval of contextual information, and build sophisticated workflows that can tackle complex real-world challenges. By leveraging the power of these tools and frameworks, you can push the boundaries of what is possible with language-based AI applications and create truly intelligent systems that can transform the way your enterprise interacts with data and technology.


