
How to Build Powerful LLM Apps with Vector Databases + RAG – AI&YOU#55



Stat/Fact of the Week: 30% of enterprises will use vector databases to ground their generative AI models by 2026, up from 2% in 2023. (Gartner)
LLMs like GPT-4, Claude, and Llama 3 have emerged as powerful tools for enterprises implementing NLP, demonstrating remarkable capabilities in understanding and generating human-like text. However, they often struggle with context awareness and accuracy, especially when dealing with domain-specific information.
That’s why in this week’s edition of AI&YOU, we are exploring how these challenges are addressed through three blogs we published:
Combining vector databases and RAG for powerful LLM apps – AI&YOU #55
To address these challenges, researchers and developers have turned to innovative techniques like Retrieval Augmented Generation (RAG) and vector databases. RAG enhances LLMs by allowing them to access and retrieve relevant information from external knowledge bases, while vector databases provide an efficient and scalable solution for storing and querying high-dimensional data representations.
The Synergy between Vector Databases and RAG
Vector databases and RAG form a powerful synergy that enhances the capabilities of large language models. At the core of this synergy lies the efficient storage and retrieval of knowledge base embeddings. Vector databases are designed to handle high-dimensional vector representations of data. They enable fast and accurate similarity search, allowing LLMs to quickly retrieve relevant information from vast knowledge bases.
By integrating vector databases with RAG, we can create a seamless pipeline for augmenting LLM responses with external knowledge. When an LLM receives a query, RAG can efficiently search the vector database to find the most relevant information based on the query’s embedding. This retrieved information is then used to enrich the LLM’s context, enabling it to generate more accurate and informative responses in real-time.
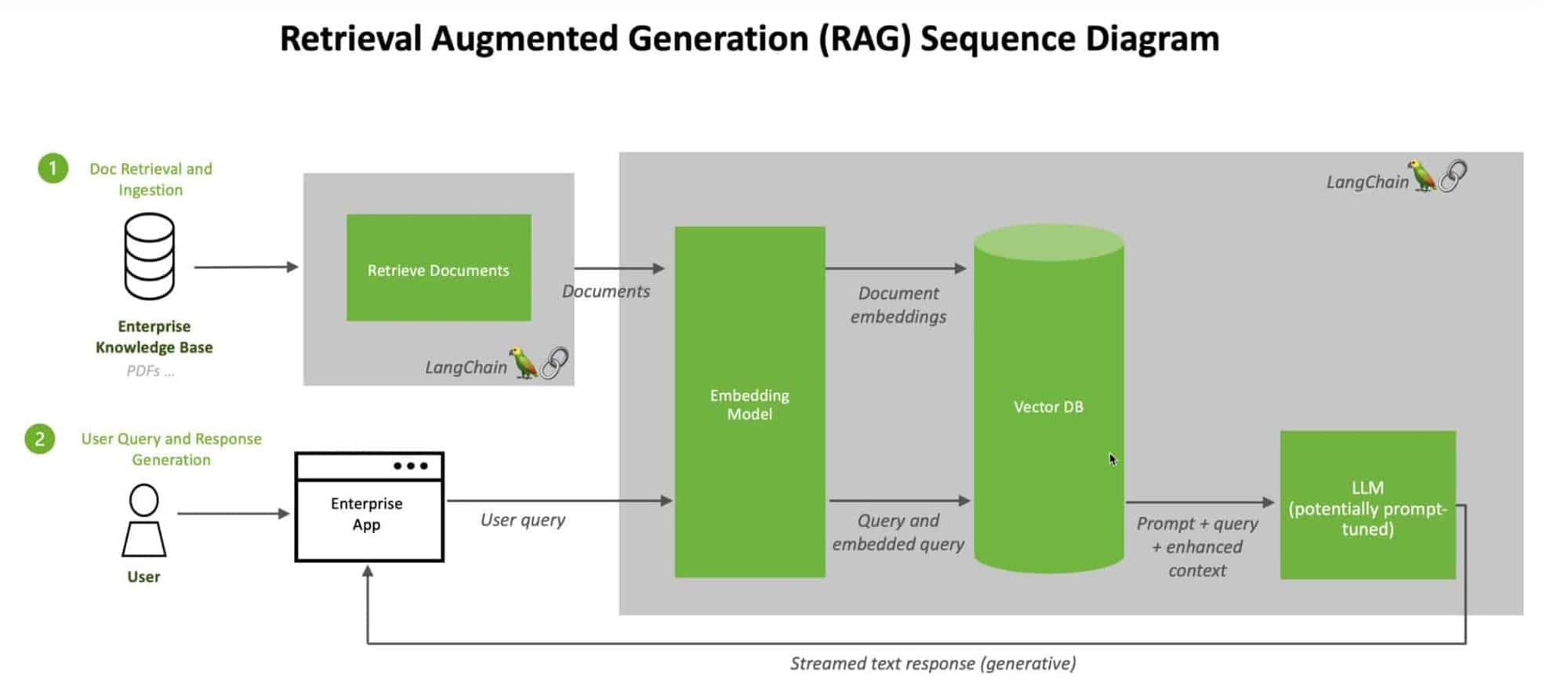
Benefits of combining vector databases and RAG
Combining vector databases and RAG offers several significant benefits for large language model applications:
Improved accuracy and reduced hallucinations
One of the primary benefits of combining vector databases and RAG is the significant improvement in the accuracy of LLM responses. By providing LLMs with access to relevant external knowledge, RAG helps reduce the occurrence of “hallucinations” – instances where the model generates inconsistent or factually incorrect information. With the ability to retrieve and incorporate domain-specific information from reliable sources, LLMs can produce more accurate and trustworthy outputs.
Scalability and performance
Vector databases are designed to scale efficiently, allowing them to handle large volumes of high-dimensional data. This scalability is crucial when dealing with extensive knowledge bases that need to be searched and retrieved in real-time. By leveraging the power of vector databases, RAG can perform fast and efficient similarity searches, enabling LLMs to generate responses quickly without compromising on the quality of the retrieved information.
Enabling domain-specific applications
The combination of vector databases and RAG opens up new possibilities for building domain-specific LLM applications. By curating knowledge bases specific to various domains, LLMs can be tailored to provide accurate and relevant information within those contexts. This enables the development of specialized AI assistants, chatbots, and knowledge management systems that can cater to the unique needs of different industries and use cases.

Implementing RAG with Vector Databases
To harness the power of combining vector databases and RAG, it’s essential to understand the implementation process.
Let’s explore the key steps involved in setting up a RAG system with a vector database:
Indexing and storing knowledge base embeddings: The first step is to convert the text data from the knowledge base into high-dimensional vectors using embedding models like BERT, and then index and store these embeddings in the vector database for efficient similarity search and retrieval.
Querying the vector database for relevant information: When an LLM receives a query, the RAG system transforms the query into a vector representation using the same embedding model, and the vector database performs a similarity search to retrieve the most relevant knowledge base embeddings based on a chosen similarity metric.
Integrating retrieved information into LLM responses: The relevant information retrieved from the vector database is integrated into the LLM’s response generation process, either by concatenating it with the original query or using techniques like attention mechanisms, allowing the LLM to generate more accurate and informative responses based on the augmented context.
Choosing the right vector database for your application: Selecting the appropriate vector database is crucial, considering factors like scalability, performance, ease of use, and compatibility with your existing technology stack, as well as your specific requirements such as knowledge base size, query volume, and desired response latency.
Best Practices and Considerations
To ensure the success of your RAG implementation with vector databases, there are several best practices and considerations to keep in mind.
Optimizing knowledge base embeddings for retrieval:
The quality of the knowledge base embeddings is crucial, requiring experimentation with different embedding models and techniques, fine-tuning on domain-specific data, and regularly updating and expanding the embeddings as new information becomes available to maintain relevance and accuracy.
Balancing retrieval speed and accuracy:
There’s a trade-off between retrieval speed and accuracy, necessitating techniques like approximate nearest neighbor search to speed up retrieval while maintaining acceptable accuracy, as well as caching frequently accessed embeddings and implementing load balancing strategies to optimize performance.
Ensuring data security and privacy:
Establishing secure data storage, access controls, and encryption techniques like homomorphic encryption is essential to prevent unauthorized access and protect sensitive data in the knowledge base embeddings, while adhering to relevant data protection regulations.
Monitoring and maintaining the system:
Continuously monitoring metrics such as query latency, retrieval accuracy, and resource utilization, implementing automated monitoring and alerting mechanisms, and establishing a robust maintenance schedule, including backups, updates, and performance tuning, are vital for ensuring the long-term performance and reliability of the RAG system.
Harnessing the Power of Vector Databases and RAG in Your Enterprise
As AI continues to shape our future, it is crucial for your enterprise to stay at the forefront of these technological advancements. By exploring and implementing cutting-edge techniques like vector databases and RAG, you can unlock the full potential of large language models and create AI systems that are more intelligent, adaptable, and provide greater ROI.
Top 10 Benefits of Using an Open-Source Vector Database
Among vector database solutions, open-source vector databases offer a compelling combination of flexibility, scalability, and cost-effectiveness. By harnessing the collective power of the open-source community, these specialized vector databases are redefining the way organizations approach data management and analysis.
This week, our blog also explored the top 10 benefits of using an open-source vector database:
🔸 Scalability and cost-effectiveness enable seamless growth without high costs, eliminating vendor lock-in and providing a budget-friendly solution.
🔸 Flexibility and customization allow tailoring the database to specific needs, modifying functionality, and integrating with existing systems.
🔸 Efficient handling of unstructured data leverages techniques like NLP and vector embeddings for effective storage, search, and analysis.
🔸 Powerful vector similarity search facilitates accurate retrieval based on semantic similarity, enabling applications like personalized recommendations and intelligent content discovery.
🔸 Integration with open-source ecosystems ensures interoperability with complementary tools and frameworks, enhancing productivity and fostering collaboration.
🔸 Robust security and data privacy measures prioritize transparency, encryption, access control, and adherence to compliance standards.
🔸 High-performance and efficient data management deliver lightning-fast query execution and versatility for diverse workloads.
🔸 Compatibility with advanced analytics and machine learning allows seamless integration with cutting-edge techniques and frameworks.
🔸 Future-proof and scalable architecture enables seamless growth and adaptation to emerging technologies and evolving data requirements.
🔸 Community-driven innovation and support foster continuous improvement, knowledge sharing, and invaluable resources for leveraging these powerful tools.
Top 5 Vector Databases for Your Enterprise
Besides the top benefits, this week we also published a blog on the top 5 vector databases for your enterprise:
1. Chroma
Chroma is designed for seamless integration with machine learning models and frameworks, simplifying the process of building AI-powered applications. It offers efficient vector storage, retrieval, similarity search, real-time indexing, and metadata storage. Supports various distance metrics and indexing algorithms for optimal performance across use cases like semantic search, recommendations, and anomaly detection.

2. Pinecone
Pinecone is a fully managed, serverless vector database prioritizing high performance and ease of use. It combines advanced vector search algorithms with filtering and distributed infrastructure for fast, reliable vector search at scale. Seamlessly integrates with machine learning frameworks and data sources for applications like semantic search, recommendations, anomaly detection, and question-answering.
3. Qdrant
Qdrant is an open-source, high-speed, and scalable vector similarity search engine written in Rust. It provides a convenient API for storing, searching, and managing vectors with metadata, enabling production-ready applications for matching, searching, recommending, and more. Features include real-time updates, advanced filtering, distributed indexes, and cloud-native deployment options.
4. Weaviate
Weaviate is an open-source vector database prioritizing speed, scalability, and ease of use. It allows storing both objects and vectors, combining vector search with structured filtering. Offers a GraphQL-based API, CRUD operations, horizontal scaling, and cloud-native deployment. Incorporates modules for NLP tasks, automatic schema configuration, and custom vectorization.
5. Milvus
Milvus is an open-source vector database designed for embedding management, similarity search, and scalable AI applications. It offers heterogeneous compute support, storage reliability, comprehensive metrics, and a cloud-native architecture. Provides a flexible API for indexes, distance metrics, and query types, and can scale to billions of vectors with custom plugins.
Choosing the Right Vector Database for Your Enterprise
Whether you’re building a semantic search engine, a recommendation system, or any other AI-powered application, vector databases provide the foundation for unlocking the full potential of machine learning models. By enabling fast similarity search, advanced filtering, and seamless integration with popular frameworks, these databases empower developers to focus on building innovative solutions without worrying about the underlying complexities of managing vector data.
For even more content on enterprise AI, including infographics, stats, how-to guides, articles, and videos, follow Skim AI on LinkedIn
Are you a Founder, CEO, Venture Capitalist, or Investor seeking AI Advisory or Due Diligence services? Get the guidance you need to make informed decisions about your company’s AI product strategy or investment opportunities.
We build custom AI solutions for Venture Capital and Private Equity backed companies in the following industries: Medical Technology, News/Content Aggregation, Film & Photo Production, Educational Technology, Legal Technology, Fintech & Cryptocurrency.


