
Few-Shot Prompting vs Fine-Tuning LLM for Generative AI Solutions



The true potential of large language models (LLMs) lies not just in their vast knowledge base, but in their ability to adapt to specific tasks and domains with minimal additional training. This is where the concepts of few-shot prompting and fine-tuning come into play, improving how we harness the power of LLMs in real-world scenarios.
While LLMs are trained on massive datasets encompassing a broad spectrum of knowledge, they often struggle when faced with highly specialized tasks or domain-specific jargon. Traditional supervised learning approaches would require large amounts of labeled data to adapt these models, which is often impractical or impossible in many real-world situations. This challenge has led researchers and practitioners to explore more efficient methods of tailoring LLMs to specific use cases using only a small number of examples.
Brief Overview of Few-Shot Prompting and Fine-Tuning
Two powerful techniques exist to address this challenge: few-shot prompting and fine-tuning. Few-shot prompting involves crafting clever input prompts that include a small number of examples, guiding the model to perform a specific task without any additional training. Fine-tuning, on the other hand, involves updating the model’s parameters using a limited amount of task-specific data, allowing it to adapt its vast knowledge to a particular domain or application.
Both approaches fall under the umbrella of few-shot learning, a paradigm that enables models to learn new tasks or adapt to new domains using just a few examples. By leveraging these techniques, we can dramatically enhance the performance and versatility of LLMs, making them more practical and effective tools for a wide range of applications in natural language processing and beyond.
Few-Shot Prompting: Unleashing LLM Potential
Few-shot prompting is a powerful technique that allows us to guide LLMs towards specific tasks or domains without the need for additional training. This method capitalizes on the model’s inherent ability to understand and follow instructions, effectively “programming” the LLM through carefully crafted prompts.
At its core, few-shot prompting involves providing the LLM with a small number of examples (typically 1-5) that demonstrate the desired task, followed by a new input for which we want the model to generate a response. This approach leverages the model’s ability to recognize patterns and adapt its behavior based on the given examples, enabling it to perform tasks it wasn’t explicitly trained for.
The key principle behind few-shot prompting is that by presenting the model with a clear pattern of inputs and outputs, we can guide it to apply similar reasoning to new, unseen inputs. This technique taps into the LLM’s capacity for in-context learning, allowing it to quickly adapt to new tasks without updating its parameters.
Types of few-shot prompts (zero-shot, one-shot, few-shot)
Few-shot prompting encompasses a spectrum of approaches, each defined by the number of examples provided:
Zero-shot prompting: In this scenario, no examples are provided. Instead, the model is given a clear instruction or description of the task. For instance, “Translate the following English text to French: [input text].”
One-shot prompting: Here, a single example is provided before the actual input. This gives the model a concrete instance of the expected input-output relationship. For example: “Classify the sentiment of the following review as positive or negative. Example: ‘This movie was fantastic!’ – Positive Input: ‘I couldn’t stand the plot.’ – [model generates response]”
Few-shot prompting: This approach provides multiple examples (typically 2-5) before the actual input. This allows the model to recognize more complex patterns and nuances in the task. For example: “Classify the following sentences as questions or statements: ‘The sky is blue.’ – Statement ‘What time is it?’ – Question ‘I love ice cream.’ – Statement Input: ‘Where can I find the nearest restaurant?’ – [model generates response]”
Designing effective few-shot prompts
Crafting effective few-shot prompts is both an art and a science. Here are some key principles to consider:
Clarity and consistency: Ensure your examples and instructions are clear and follow a consistent format. This helps the model recognize the pattern more easily.
Diversity: When using multiple examples, try to cover a range of possible inputs and outputs to give the model a broader understanding of the task.
Relevance: Choose examples that are closely related to the specific task or domain you’re targeting. This helps the model focus on the most relevant aspects of its knowledge.
Conciseness: While it’s important to provide enough context, avoid overly long or complex prompts that might confuse the model or dilute the key information.
Experimentation: Don’t be afraid to iterate and experiment with different prompt structures and examples to find what works best for your specific use case.
By mastering the art of few-shot prompting, we can unlock the full potential of LLMs, enabling them to tackle a wide range of tasks with minimal additional input or training.
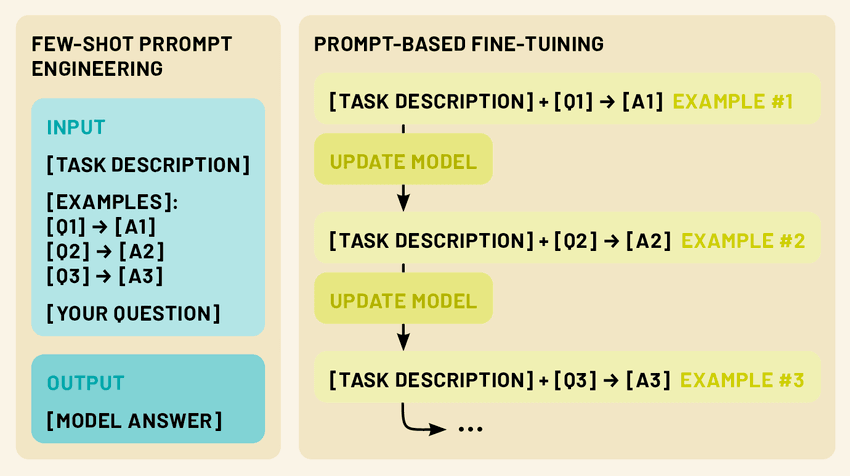
Fine-Tuning LLMs: Tailoring Models with Limited Data
While few-shot prompting is a powerful technique for adapting LLMs to new tasks without modifying the model itself, fine-tuning offers a way to update the model’s parameters for even better performance on specific tasks or domains. Fine-tuning allows us to leverage the vast knowledge encoded in pre-trained LLMs while tailoring them to our specific needs using only a small amount of task-specific data.
Understanding fine-tuning in the context of LLMs
Fine-tuning an LLM involves taking a pre-trained model and further training it on a smaller, task-specific dataset. This process allows the model to adapt its learned representations to the nuances of the target task or domain. The key advantage of fine-tuning is that it builds upon the rich knowledge and language understanding already present in the pre-trained model, requiring far less data and computational resources than training a model from scratch.
In the context of LLMs, fine-tuning typically focuses on adjusting the weights of the upper layers of the network, which are responsible for more task-specific features, while leaving the lower layers (which capture more general language patterns) largely unchanged. This approach, often called “transfer learning,” allows the model to retain its broad language understanding while developing specialized capabilities for the target task.
Few-shot fine-tuning techniques
Few-shot fine-tuning takes the concept of fine-tuning a step further by attempting to adapt the model using only a very small number of examples – typically in the range of 10 to 100 samples per class or task. This approach is particularly valuable when labeled data for the target task is scarce or expensive to obtain. Some key techniques in few-shot fine-tuning include:
Prompt-based fine-tuning: This method combines the ideas of few-shot prompting with parameter updates. The model is fine-tuned on a small dataset where each example is formatted as a prompt-completion pair, similar to few-shot prompts.
Meta-learning approaches: Techniques like Model-Agnostic Meta-Learning (MAML) can be adapted for few-shot fine-tuning of LLMs. These methods aim to find a good initialization point that allows the model to quickly adapt to new tasks with minimal data.
Adapter-based fine-tuning: Instead of updating all model parameters, this approach introduces small “adapter” modules between the layers of the pre-trained model. Only these adapters are trained on the new task, reducing the number of trainable parameters and the risk of catastrophic forgetting.
In-context learning: Some recent approaches attempt to fine-tune LLMs to better perform in-context learning, enhancing their ability to adapt to new tasks through prompts alone.
Few-Shot Prompting vs. Fine-Tuning: Choosing the Right Approach
When adapting LLMs to specific tasks, both few-shot prompting and fine-tuning offer powerful solutions. However, each method has its own strengths and limitations, and choosing the right approach depends on various factors.
Strengths and limitations of each method
Few-Shot Prompting: Strengths:
Requires no model parameter updates, preserving the original model
Highly flexible and can be adapted on-the-fly
No additional training time or computational resources needed
Useful for quick prototyping and experimentation
Limitations:
Performance may be less consistent, especially for complex tasks
Limited by the model’s original capabilities and knowledge
May struggle with highly specialized domains or tasks
Fine-Tuning: Strengths:
Often achieves better performance on specific tasks
Can adapt the model to new domains and specialized vocabulary
More consistent results across similar inputs
Potential for continual learning and improvement
Limitations:
Requires additional training time and computational resources
Risk of catastrophic forgetting if not carefully managed
May overfit on small datasets
Less flexible; requires retraining for significant task changes
Factors to consider when selecting a technique
There are several factors you should consider when selecting a technique:
Data availability: If you have a small amount of high-quality, task-specific data, fine-tuning might be preferable. For tasks with very limited or no specific data, few-shot prompting could be the better choice.
Task complexity: Simple tasks that are close to the model’s pre-training domain might work well with few-shot prompting. More complex or specialized tasks often benefit from fine-tuning.
Resource constraints: Consider your available computational resources and time constraints. Few-shot prompting is generally quicker and less resource-intensive.
Flexibility requirements: If you need to quickly adapt to various tasks or frequently change your approach, few-shot prompting offers more flexibility.
Performance requirements: For applications requiring high accuracy and consistency, fine-tuning often provides better results, especially with sufficient task-specific data.
Privacy and security: If working with sensitive data, few-shot prompting might be preferable as it doesn’t require sharing data for model updates.
Practical Applications of Few-Shot Techniques for LLMs
Few-shot learning techniques have opened up a wide range of applications for LLMs across various domains, enabling these models to adapt quickly to specific tasks with minimal examples.
Natural Language Processing tasks:
Text Classification: Few-shot techniques enable LLMs to categorize text into predefined classes with just a few examples per category. This is useful for content tagging, spam detection, and topic modeling.
Sentiment Analysis: LLMs can quickly adapt to domain-specific sentiment analysis tasks, understanding the nuances of sentiment expression in different contexts.
Named Entity Recognition (NER): Few-shot learning allows LLMs to identify and classify named entities in specialized domains, such as identifying chemical compounds in scientific literature.
Question Answering: LLMs can be tailored to answer questions in specific domains or formats, enhancing their utility in customer service and information retrieval systems.
Domain-specific adaptations:
Legal: Few-shot techniques enable LLMs to understand and generate legal documents, classify legal cases, and extract relevant information from contracts with minimal domain-specific training.
Medical: LLMs can be adapted to tasks such as medical report summarization, disease classification from symptoms, and drug interaction prediction using only a small number of medical examples.
Technical: In fields like engineering or computer science, few-shot learning allows LLMs to understand and generate specialized technical content, debug code, or explain complex concepts using domain-specific terminology.
Multilingual and cross-lingual applications:
Low-resource language translation: Few-shot techniques can help LLMs perform translation tasks for languages with limited available data.
Cross-lingual transfer: Models trained on high-resource languages can be adapted to perform tasks in low-resource languages using few-shot learning.
Multilingual task adaptation: LLMs can quickly adapt to perform the same task across multiple languages with just a few examples in each language.
Challenges and Limitations of Few-Shot Techniques
While few-shot techniques for LLMs offer tremendous potential, they also come with several challenges and limitations that need to be addressed.
Consistency and reliability issues:
Performance variability: Few-shot methods can sometimes produce inconsistent results, especially with complex tasks or edge cases.
Prompt sensitivity: Small changes in prompt wording or example selection can lead to significant variations in output quality.
Task-specific limitations: Some tasks may be inherently difficult to learn from just a few examples, leading to suboptimal performance.
Ethical considerations and biases:
Amplification of biases: Few-shot learning might amplify biases present in the limited examples provided, potentially leading to unfair or discriminatory outputs.
Lack of robustness: Models adapted with few-shot techniques might be more susceptible to adversarial attacks or unexpected inputs.
Transparency and explainability: It can be challenging to understand and explain how the model arrives at its conclusions in few-shot scenarios.
Computational resources and efficiency:
Model size limitations: As LLMs grow larger, the computational requirements for fine-tuning become increasingly demanding, potentially limiting accessibility.
Inference time: Complex few-shot prompts can increase inference time, potentially impacting real-time applications.
Energy consumption: The computational resources required for large-scale deployment of few-shot techniques raise concerns about energy efficiency and environmental impact.
Addressing these challenges and limitations is crucial for the continued development and responsible deployment of few-shot learning techniques in LLMs. As research progresses, we can expect to see innovative solutions that enhance the reliability, fairness, and efficiency of these powerful methods.
The Bottom Line
Few-shot prompting and fine-tuning represent groundbreaking approaches, enabling LLMs to adapt swiftly to specialized tasks with minimal data. As we’ve explored, these techniques offer unprecedented flexibility and efficiency in tailoring LLMs to diverse applications across industries, from enhancing natural language processing tasks to enabling domain-specific adaptations in fields like healthcare, law, and technology.
While challenges remain, particularly in consistency, ethical considerations, and computational efficiency, the potential of few-shot learning in LLMs is undeniable. As research continues to advance, addressing current limitations and uncovering new optimization strategies, we can anticipate even more powerful and versatile applications of these techniques. The future of AI lies not just in bigger models, but in smarter, more adaptable ones – and few-shot learning is paving the way for this new era of intelligent, efficient, and highly specialized language models that can truly understand and respond to our ever-evolving needs.


