
AI Research Paper Breakdown for ChainPoll: A High Efficacy Method for LLM Hallucination Detection



In this article, we are going to break down an important research paper that addresses one of the most pressing challenges facing large language models (LLMs): hallucinations. The paper, titled “ChainPoll: A High Efficacy Method for LLM Hallucination Detection,” introduces a novel approach to identifying and mitigating these AI-generated inaccuracies.
The ChainPoll paper, authored by researchers at Galileo Technologies Inc., presents a new methodology for detecting hallucinations in LLM outputs. This method, named ChainPoll, outperforms existing alternatives in both accuracy and efficiency. Additionally, the paper introduces RealHall, a carefully curated suite of benchmark datasets designed to evaluate hallucination detection metrics more effectively than previous benchmarks.
Hallucinations in LLMs refer to instances where these AI models generate text that is factually incorrect, nonsensical, or unrelated to the input data. As LLMs become increasingly integrated into various applications, from chatbots to content creation tools, the risk of propagating misinformation through these hallucinations grows exponentially. This issue poses a significant challenge to the reliability and trustworthiness of AI-generated content.
The ability to accurately detect and mitigate hallucinations is crucial for the responsible deployment of AI systems. This research provides a more robust method for identifying these errors, which can lead to improved reliability of AI-generated content, enhanced user trust in AI applications, and reduced risk of misinformation spread through AI systems. By addressing the hallucination problem, this research paves the way for more reliable and trustworthy AI applications across various industries.

Background and Problem Statement
Detecting hallucinations in LLM outputs is a complex task due to several factors. The sheer volume of text that LLMs can generate, combined with the often subtle nature of hallucinations, makes them difficult to distinguish from accurate information. Additionally, the context-dependent nature of many hallucinations and the lack of a comprehensive “ground truth” against which to check all generated content further complicate the detection process.
Prior to the ChainPoll paper, existing hallucination detection methods faced several limitations. Many lacked effectiveness across diverse tasks and domains, while others were too computationally expensive for real-time applications. Some methods were dependent on specific model architectures or training data, and most struggled to distinguish between different types of hallucinations, such as factual versus contextual errors.
Furthermore, the benchmarks used to evaluate these methods often failed to reflect the true challenges posed by state-of-the-art LLMs in real-world applications. Many were based on older, weaker models or focused on narrow, specific tasks that didn’t represent the full range of LLM capabilities and potential hallucinations.
To address these issues, the researchers behind the ChainPoll paper took a two-pronged approach:
Developing a new, more effective hallucination detection method (ChainPoll)
Creating a more relevant and challenging benchmark suite (RealHall)
This comprehensive approach aimed to not only improve the detection of hallucinations but also to establish a more robust framework for evaluating and comparing different detection methods.
Key Contributions of the Paper
The ChainPoll paper makes three primary contributions to the field of AI research and development, each addressing a critical aspect of the hallucination detection challenge.
Firstly, the paper introduces ChainPoll, a novel hallucination detection methodology. ChainPoll leverages the power of LLMs themselves to identify hallucinations, using a carefully engineered prompting technique and an aggregation method to improve accuracy and reliability. It employs chain-of-thought prompting to elicit more detailed and systematic explanations, runs multiple iterations of the detection process to increase reliability, and adapts to both open-domain and closed-domain hallucination detection scenarios.
Secondly, recognizing the limitations of existing benchmarks, the authors developed RealHall, a new suite of benchmark datasets. RealHall is designed to provide a more realistic and challenging evaluation of hallucination detection methods. It comprises four carefully selected datasets that are challenging even for state-of-the-art LLMs, focuses on tasks relevant to real-world LLM applications, and covers both open-domain and closed-domain hallucination scenarios.
Lastly, the paper provides a thorough comparison of ChainPoll against a wide range of existing hallucination detection methods. This comprehensive evaluation uses the newly developed RealHall benchmark suite, includes both established metrics and recent innovations in the field, and considers factors such as accuracy, efficiency, and cost-effectiveness. Through this evaluation, the paper demonstrates ChainPoll’s superior performance across various tasks and hallucination types.
By offering these three key contributions, the ChainPoll paper not only advances the state of the art in hallucination detection but also provides a more robust framework for future research and development in this critical area of AI safety and reliability.
Looking Into the ChainPoll Methodology
At its core, ChainPoll leverages the capabilities of large language models themselves to identify hallucinations in AI-generated text. This approach stands out for its simplicity, effectiveness, and adaptability across different types of hallucinations.
How ChainPoll works
The ChainPoll method operates on a straightforward yet powerful principle. It uses an LLM (specifically, GPT-3.5-turbo in the paper’s experiments) to evaluate whether a given text completion contains hallucinations.
The process involves three key steps:
First, the system prompts the LLM to assess the presence of hallucinations in the target text, using a carefully engineered prompt.
Next, this process is repeated multiple times, typically five, to ensure reliability.
Finally, the system calculates a score by dividing the number of “yes” responses (indicating the presence of hallucinations) by the total number of responses.
This approach allows ChainPoll to harness the language understanding capabilities of LLMs while mitigating individual assessment errors through aggregation.
The role of chain-of-thought prompting
A crucial innovation in ChainPoll is its use of chain-of-thought (CoT) prompting. This technique encourages the LLM to provide a step-by-step explanation of its reasoning when determining whether a text contains hallucinations. The authors found that a carefully engineered “detailed CoT” prompt consistently elicited more systematic and reliable explanations from the model.
By incorporating CoT, ChainPoll not only improves the accuracy of hallucination detection but also provides valuable insights into the model’s decision-making process. This transparency can be crucial for understanding why certain texts are flagged as containing hallucinations, potentially aiding in the development of more robust LLMs in the future.
Differentiating between open-domain and closed-domain hallucinations
One of ChainPoll’s strengths is its ability to address both open-domain and closed-domain hallucinations. Open-domain hallucinations refer to false claims about the world in general, while closed-domain hallucinations involve inconsistencies with a specific reference text or context.
To handle these different types of hallucinations, the authors developed two variants of ChainPoll: ChainPoll-Correctness for open-domain hallucinations and ChainPoll-Adherence for closed-domain hallucinations. These variants differ primarily in their prompting strategy, allowing the system to adapt to different evaluation contexts while maintaining the core ChainPoll methodology.
The RealHall Benchmark Suite
Recognizing the limitations of existing benchmarks, the authors also developed RealHall, a new benchmark suite designed to provide a more realistic and challenging evaluation of hallucination detection methods.
Criteria for dataset selection (Challenge, Realism, Task Diversity)
The creation of RealHall was guided by three key principles:
Challenge: The datasets should pose significant difficulties even for state-of-the-art LLMs, ensuring that the benchmark remains relevant as models improve.
Realism: The tasks should closely reflect real-world applications of LLMs, making the benchmark results more applicable to practical scenarios.
Task Diversity: The suite should cover a wide range of LLM capabilities, providing a comprehensive evaluation of hallucination detection methods.
These criteria led to the selection of four datasets that collectively offer a robust testing ground for hallucination detection methods.
Overview of the four datasets in RealHall
RealHall comprises two pairs of datasets, each addressing a different aspect of hallucination detection:
RealHall Closed: This pair includes the COVID-QA with retrieval dataset and the DROP dataset. These focus on closed-domain hallucinations, testing a model’s ability to remain consistent with provided reference texts.
RealHall Open: This pair consists of the Open Assistant prompts dataset and the TriviaQA dataset. These target open-domain hallucinations, assessing a model’s ability to avoid making false claims about the world.
Each dataset in RealHall was chosen for its unique challenges and relevance to real-world LLM applications. For instance, the COVID-QA dataset mimics retrieval-augmented generation scenarios, while DROP tests discrete reasoning abilities.
How RealHall addresses limitations of previous benchmarks
RealHall represents a significant improvement over previous benchmarks in several ways. Firstly, it uses more recent and powerful LLMs to generate responses, ensuring that the hallucinations being detected are representative of those produced by current state-of-the-art models. This addresses a common issue with older benchmarks that used outdated models producing easily detectable hallucinations.
Secondly, RealHall’s focus on task diversity and realism means that it provides a more comprehensive and practically relevant evaluation of hallucination detection methods. This contrasts with many previous benchmarks that focused on narrow, specific tasks or artificial scenarios.
Lastly, by including both open-domain and closed-domain tasks, RealHall allows for a more nuanced evaluation of hallucination detection methods. This is particularly important as many real-world LLM applications require both types of hallucination detection.
Through these improvements, RealHall provides a more rigorous and relevant benchmark for evaluating hallucination detection methods, setting a new standard in the field.
Experimental Results and Analysis
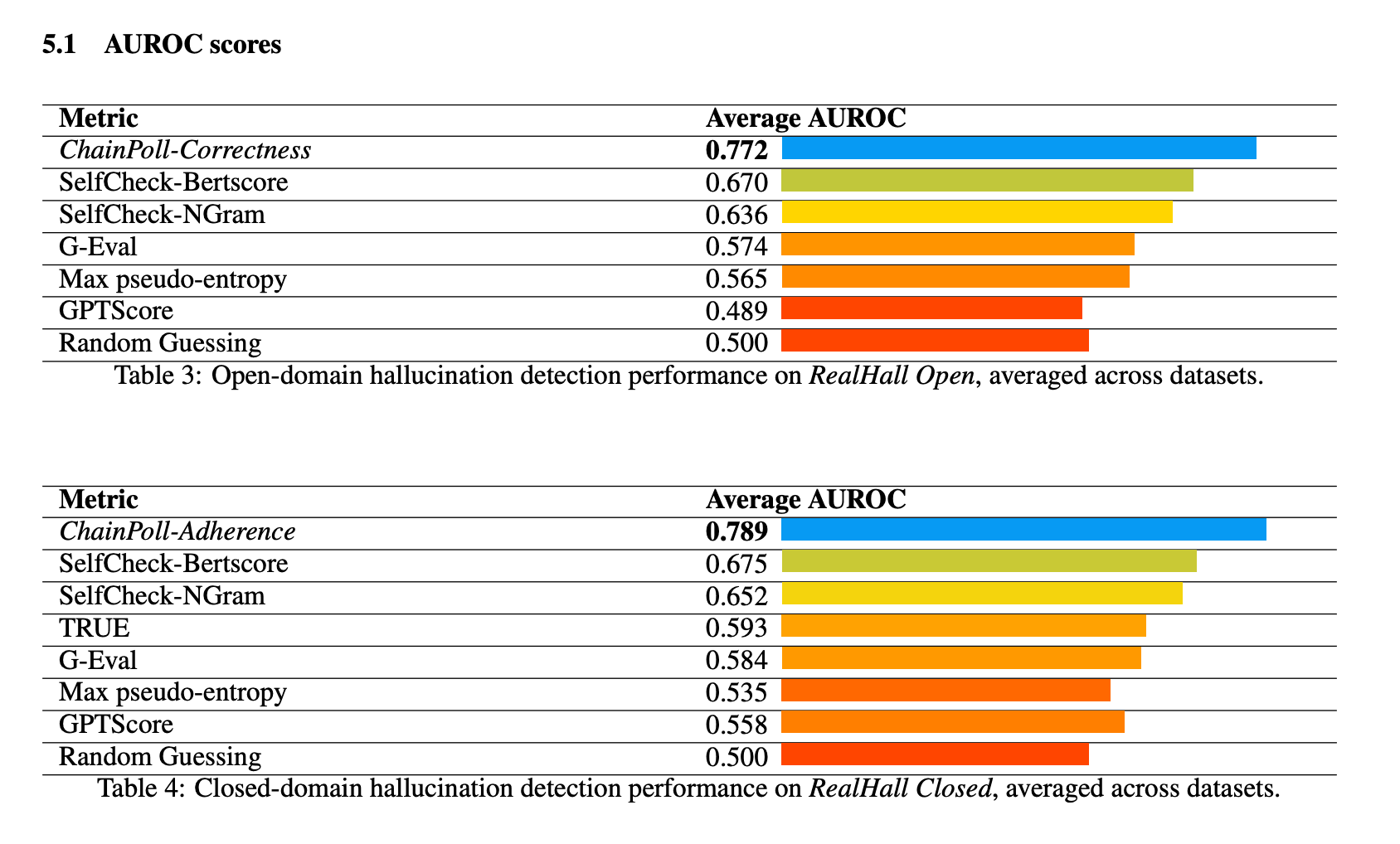
ChainPoll demonstrated superior performance across all benchmarks in the RealHall suite. It achieved an aggregate AUROC (Area Under the Receiver Operating Characteristic curve) of 0.781, significantly outperforming the next best method, SelfCheck-BertScore, which scored 0.673. This substantial improvement of over 10% represents a significant leap in hallucination detection capability.
Other methods tested included SelfCheck-NGram, G-Eval, and GPTScore, all of which performed notably worse than ChainPoll. Interestingly, some methods that had shown promise in previous studies, such as GPTScore, performed poorly on the more challenging and diverse RealHall benchmarks.

ChainPoll’s performance was consistently strong across both open-domain and closed-domain hallucination detection tasks. For open-domain tasks (using ChainPoll-Correctness), it achieved an average AUROC of 0.772, while for closed-domain tasks (using ChainPoll-Adherence), it scored 0.789.
The method showed particular strength in challenging datasets like DROP, which requires discrete reasoning.
Beyond its superior accuracy, ChainPoll also proved to be more efficient and cost-effective than many competing methods. It achieves its results while using only 1/4 as much LLM inference as the next-best method, SelfCheck-BertScore. Additionally, ChainPoll doesn’t require the use of additional models like BERT, further reducing computational overhead.
This efficiency is crucial for practical applications, as it allows for real-time hallucination detection in production environments without incurring prohibitive costs or latency.
Implications and Future Work
ChainPoll represents a significant advance in the field of hallucination detection for LLMs. Its success demonstrates the potential of using LLMs themselves as tools for improving AI safety and reliability. This approach opens new avenues for research into self-improving and self-checking AI systems.
The efficiency and accuracy of ChainPoll make it well-suited for integration into a wide range of AI applications. It could be used to enhance the reliability of chatbots, improve the accuracy of AI-generated content in fields like journalism or technical writing, and increase the trustworthiness of AI assistants in critical domains such as healthcare or finance.
While ChainPoll shows impressive results, there’s still room for further research and improvement. Future work could explore:
Adapting ChainPoll to work with a wider range of LLMs and language tasks
Investigating ways to further improve efficiency without sacrificing accuracy
Exploring the potential of ChainPoll for other types of AI-generated content beyond text
Developing methods to not just detect, but also correct or prevent hallucinations in real-time
The ChainPoll paper makes significant contributions to the field of AI safety and reliability through its introduction of a novel hallucination detection method and a more robust evaluation benchmark. By demonstrating superior performance in detecting both open-domain and closed-domain hallucinations, ChainPoll paves the way for more trustworthy AI systems. As LLMs continue to play an increasingly important role in various applications, the ability to accurately detect and mitigate hallucinations becomes crucial. This research not only advances our current capabilities but also opens up new avenues for future exploration and development in the critical area of AI hallucination detection.


