
10 Proven Strategies to Cut Your LLM Costs – AI&YOU #65



Stat of the Week: Using smaller LLMs like GPT-J in a cascade can reduce overall cost by 80% while improving accuracy by 1.5% compared to GPT-4. (Dataiku)
As organizations increasingly rely on large language models (LLMs) for various applications, the operational costs associated with deploying and maintaining them can quickly spiral out of control without proper oversight and optimization strategies.
Meta has also released Llama 3.1, which has been all the talk lately for being the most advanced open-source LLM to date.
In this week’s edition of AI&YOU, we are exploring insights from three blogs we published on the topics:
10 Proven Strategies to Cut Your LLM Costs – AI&YOU #65
This week, we explore ten proven strategies to help your enterprise effectively manage LLM costs, ensuring you can harness the full potential of these models while maintaining cost efficiency and control over expenses.
1. Smart Model Selection
Optimize your LLM costs by carefully matching model complexity to task requirements. Not every application needs the latest, largest model. For simpler tasks like basic classification or straightforward Q&A, consider using smaller, more efficient pre-trained models. This approach can lead to substantial savings without compromising performance.
For instance, employing DistilBERT for sentiment analysis instead of BERT-Large can significantly reduce computational overhead and associated expenses while maintaining high accuracy for the specific task at hand.
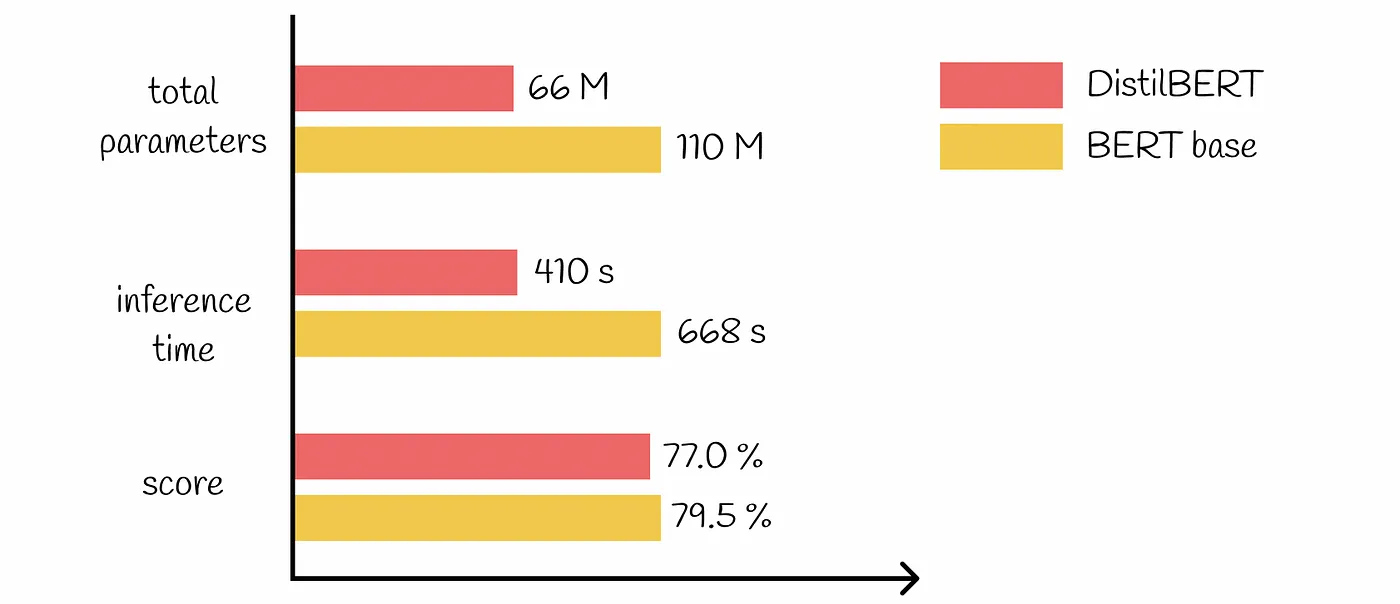
2. Implement Robust Usage Tracking
Gain a comprehensive view of your LLM usage by implementing multi-level tracking mechanisms. Monitor token usage, response times, and model calls at the conversation, user, and company levels. Leverage built-in analytics dashboards from LLM providers or implement custom tracking solutions integrated with your infrastructure.
This granular insight allows you to identify inefficiencies, such as departments overusing expensive models for simple tasks or patterns of redundant queries. By analyzing this data, you can uncover valuable cost-reduction strategies and optimize your overall LLM consumption.
3. Optimize Prompt Engineering
Refine your prompt engineering techniques to significantly reduce token usage and improve LLM efficiency. Craft clear, concise instructions in your prompts, implement error handling to address common issues without additional queries, and utilize proven prompt templates for specific tasks. Structure your prompts efficiently by avoiding unnecessary context, using formatting techniques like bullet points, and leveraging built-in functions to control output length.
These optimizations can substantially reduce token consumption and associated costs while maintaining or even improving the quality of your LLM outputs.
4. Leverage Fine-tuning for Specialization
Use the power of fine-tuning to create smaller, more efficient models tailored to your specific needs. While requiring an initial investment, this approach can lead to significant long-term savings. Fine-tuned models often require fewer tokens to achieve equal or better results, reducing inference costs and the need for retries or corrections.
Start with a smaller pre-trained model, use high-quality domain-specific data for fine-tuning, and regularly evaluate performance and cost-efficiency. This ongoing optimization ensures your models continue to deliver value while keeping operational costs in check.
5. Explore Free and Low-Cost Options
Leverage free or low-cost LLM options, especially during development and testing phases, to significantly reduce expenses without compromising quality. These alternatives are particularly valuable for prototyping, developer training, and non-critical or internal-facing services.
However, carefully evaluate the trade-offs, considering data privacy, security implications, and potential limitations in capabilities or customization. Assess long-term scalability and migration paths to ensure your cost-saving measures align with future growth plans and don’t become obstacles down the line.
6. Optimize Context Window Management
Effectively manage context windows to control costs while maintaining output quality. Implement dynamic context sizing based on task complexity, use summarization techniques to condense relevant information, and employ sliding window approaches for long documents or conversations. Regularly analyze the relationship between context size and output quality, adjusting windows based on specific task requirements.
Consider a tiered approach, using larger contexts only when necessary. This strategic management of context windows can significantly reduce token usage and associated costs without sacrificing the comprehension capabilities of your LLM applications.
7. Implement Multi-Agent Systems
Enhance efficiency and cost-effectiveness by implementing multi-agent LLM architectures. This approach involves multiple AI agents collaborating to solve complex problems, allowing for optimized resource allocation and reduced reliance on expensive, large-scale models.
Multi-agent systems enable targeted model deployment, improving overall system efficiency and response times while reducing token usage. To maintain cost-efficiency, implement robust debugging mechanisms, including logging inter-agent communications and analyzing token usage patterns.
By optimizing the division of labor among agents, you can minimize unnecessary token consumption and maximize the benefits of distributed task handling.
8. Utilize Output Formatting Tools
Leverage output formatting tools to ensure efficient token use and minimize additional processing needs. Implement forced function outputs to specify exact response formats, reducing variability and token waste. This approach decreases the likelihood of malformed outputs and the need for clarification API calls.
Consider using JSON outputs for their compact representation of structured data, easy parsing, and reduced token usage compared to natural language responses. By streamlining your LLM workflows with these formatting tools, you can significantly optimize token usage and reduce operational costs while maintaining high-quality outputs.
9. Integrate Non-LLM Tools
Complement your LLM applications with non-LLM tools to optimize costs and efficiency. Incorporate Python scripts or traditional programming approaches for tasks that don’t require the full capabilities of an LLM, such as simple data processing or rule-based decision-making.
When designing workflows, carefully balance LLM and conventional tools based on task complexity, required accuracy, and potential cost savings. Conduct thorough cost-benefit analyses considering factors like development costs, processing time, accuracy, and long-term scalability. This hybrid approach often yields the best results in terms of both performance and cost-efficiency.
10. Regular Auditing and Optimization
Implement a robust system of regular auditing and optimization to ensure ongoing LLM cost management. Consistently monitor and analyze your LLM usage to identify inefficiencies, such as redundant queries or excessive context windows. Use tracking and analysis tools to refine your LLM strategies and eliminate unnecessary token consumption.
Foster a culture of cost-consciousness within your organization, encouraging teams to actively consider the cost implications of their LLM usage and seek optimization opportunities. By making cost-efficiency a shared responsibility, you can maximize the value of your AI investments while keeping expenses under control in the long term.
Understanding LLM Pricing Structures: Inputs, Outputs, and Context Windows
For enterprise AI strategies, understanding LLM pricing structures is crucial for effective cost management. The operational costs associated with LLMs can quickly escalate without proper oversight, potentially leading to unexpected cost spikes that can derail budgets and hinder widespread adoption.
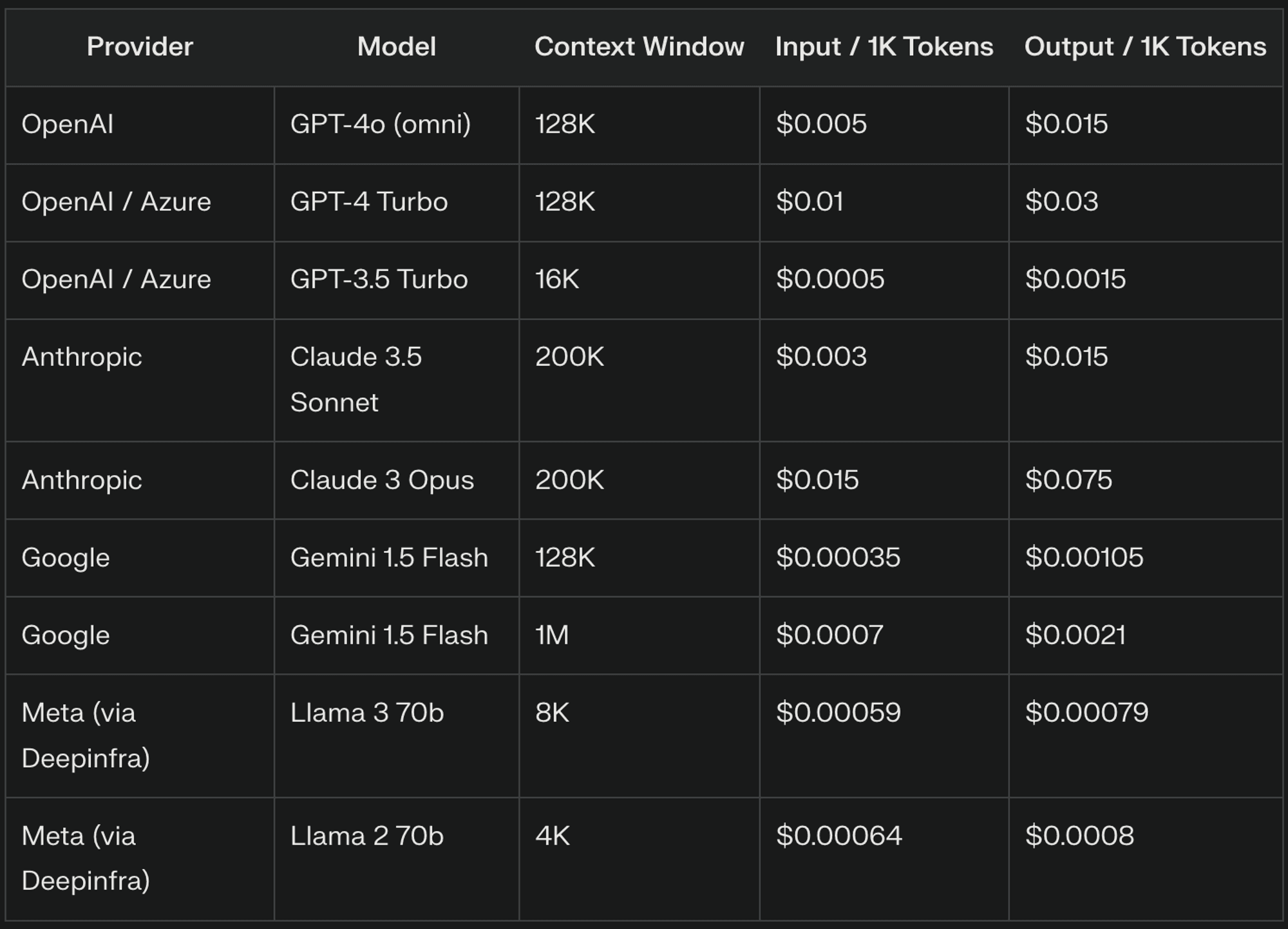
LLM pricing typically revolves around three main components: input tokens, output tokens, and context windows. Each of these elements plays a significant role in determining the overall cost of utilizing LLMs in your applications
Input Tokens: What They Are and How They’re Charged
Input tokens are the fundamental units of text processed by LLMs, typically corresponding to parts of words. For example, “The quick brown fox” might be tokenized as [“The”, “quick”, “bro”, “wn”, “fox”], resulting in 5 input tokens. LLM providers generally charge for input tokens based on a per-thousand tokens rate, with pricing varying significantly between providers and model versions.
To optimize input token usage and reduce costs, consider these strategies:
Craft concise prompts: Focus on clear, direct instructions.
Use efficient encoding: Choose methods that represent text with fewer tokens.
Implement prompt templates: Develop optimized structures for common tasks.
Leverage compression techniques: Reduce input size without losing critical information.
Output Tokens: Understanding the Costs
Output tokens represent the text generated by the LLM in response to your input. The number of output tokens can vary significantly depending on the task and model configuration. LLM providers often price output tokens higher than input tokens due to the computational complexity of text generation.
To optimize output token usage and control costs:
Set clear output length limits in prompts or API calls.
Use “few-shot learning” to guide the model towards concise responses.
Implement post-processing to trim unnecessary content.
Consider caching frequently requested information.
Utilize output formatting tools to ensure efficient token use.
Context Windows: The Hidden Cost Driver
Context windows determine how much previous text the LLM considers when generating a response, crucial for maintaining coherence and referencing earlier information. Larger context windows increase the number of input tokens processed, leading to higher costs. For example, an 8,000-token context window might charge for 7,000 tokens in a conversation, while a 4,000-token window might only charge for 3,000.
To optimize context window usage:
Implement dynamic context sizing based on task requirements.
Use summarization techniques to condense relevant information.
Employ sliding window approaches for long documents.
Consider smaller, specialized models for tasks with limited context needs.
Regularly analyze the relationship between context size and output quality.
By carefully managing these components of LLM pricing structures, enterprises can reduce operational costs while maintaining the quality of their AI applications.
The Bottom Line
Understanding LLM pricing structures is essential for effective cost management in enterprise AI applications. By grasping the nuances of input tokens, output tokens, and context windows, your organization can make informed decisions about model selection and usage patterns. Implementing strategic cost management techniques, such as optimizing token usage and leveraging caching, can lead to significant savings.
Meta’s Llama 3.1: Pushing the Boundaries of Open-Source AI
In some recent big news, Meta has announced Llama 3.1, its most advanced open-source large language model to date. This release marks a significant milestone in the democratization of AI technology, potentially bridging the gap between open-source and proprietary models.
Llama 3.1 builds on its predecessors with several key advancements:
Increased model size: The introduction of the 405B parameter model pushes the boundaries of what’s possible in open-source AI.
Extended context length: From 4K tokens in Llama 2 to 128K in Llama 3.1, enabling more complex and nuanced understanding of longer texts.
Multilingual capabilities: Expanded language support allows for more diverse applications across different regions and use cases.
Improved reasoning and specialized tasks: Enhanced performance in areas like mathematical reasoning and code generation.
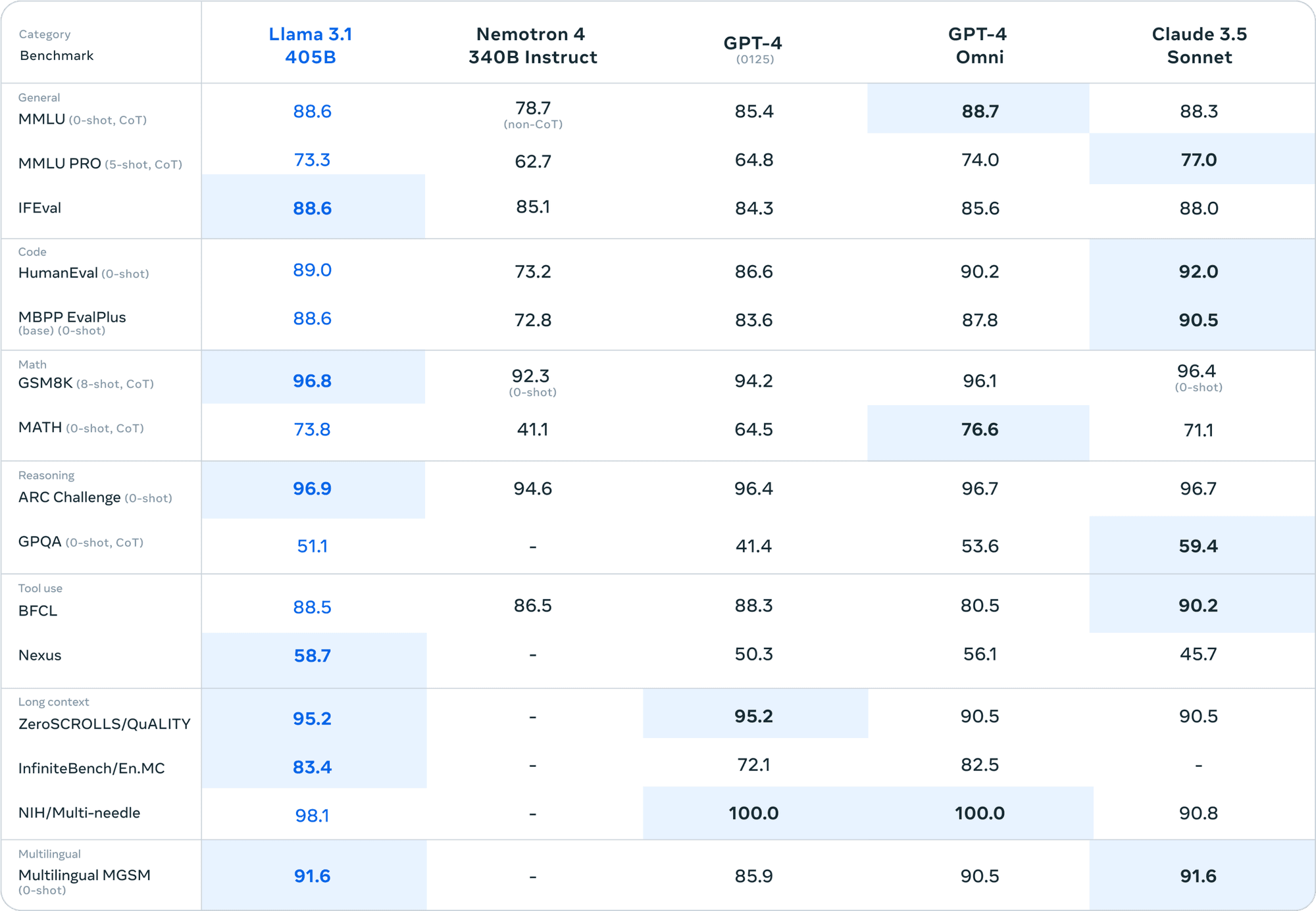
When compared to closed-source models like GPT-4 and Claude 3.5 Sonnet, Llama 3.1 405B holds its own in various benchmarks. This level of performance in an open-source model is unprecedented.
Technical Specifications of Llama 3.1
Diving into the technical details, Llama 3.1 offers a range of model sizes to suit different needs and computational resources:
8B parameter model: Suitable for lightweight applications and edge devices.
70B parameter model: A balance of performance and resource requirements.
405B parameter model: The flagship model, pushing the limits of open-source AI capabilities.
The training methodology for Llama 3.1 involved a massive dataset of over 15 trillion tokens, significantly larger than its predecessors.
Architecturally, Llama 3.1 maintains a decoder-only transformer model, prioritizing training stability over more experimental approaches like mixture-of-experts.
However, Meta has implemented several optimizations to enable efficient training and inference at this unprecedented scale:
Scalable training infrastructure: Utilizing over 16,000 H100 GPUs to train the 405B model.
Iterative post-training procedure: Employing supervised fine-tuning and direct preference optimization to enhance specific capabilities.
Quantization techniques: Reducing the model from 16-bit to 8-bit numerics for more efficient inference, enabling deployment on single server nodes.
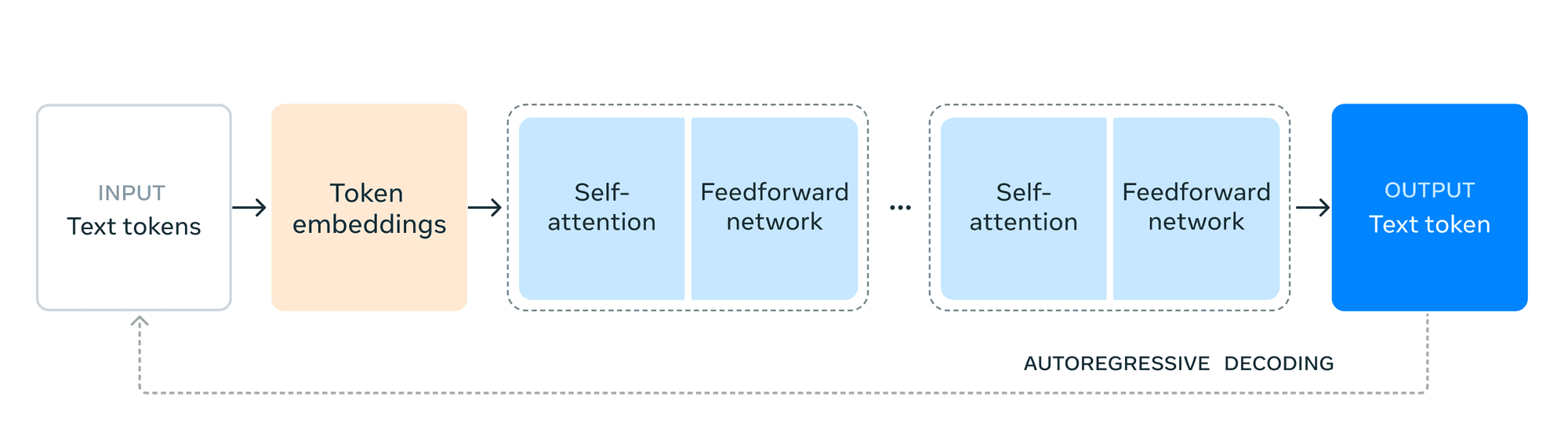
Breakthrough Capabilities
Llama 3.1 introduces several groundbreaking capabilities that set it apart in the AI landscape:
Expanded Context Length: The jump to a 128K token context window is a game-changer. This expanded capacity allows Llama 3.1 to process and understand much longer pieces of text.
Multilingual Support: Llama 3.1’s support for eight languages significantly broadens its global applicability.
Advanced Reasoning and Tool Use: The model demonstrates sophisticated reasoning capabilities and the ability to use external tools effectively.
Code Generation and Math Prowess: Llama 3.1 showcases remarkable abilities in technical domains:
Generating high-quality, functional code across multiple programming languages
Solving complex mathematical problems with accuracy
Assisting in algorithm design and optimization
Llama 3.1’s Promise and Potential
Meta’s release of Llama 3.1 marks a pivotal moment in the AI landscape, democratizing access to frontier-level AI capabilities. By offering a 405B parameter model with state-of-the-art performance, multilingual support, and extended context length, all within an open-source framework, Meta has set a new standard for accessible, powerful AI. This move not only challenges the dominance of closed-source models but also paves the way for unprecedented innovation and collaboration in the AI community.
Thank you for taking the time to read AI & YOU!
For even more content on enterprise AI, including infographics, stats, how-to guides, articles, and videos, follow Skim AI on LinkedIn
Are you a Founder, CEO, Venture Capitalist, or Investor seeking AI Advisory, Fractional AI Development or Due Diligence services? Get the guidance you need to make informed decisions about your company’s AI product strategy & investment opportunities.
We build custom AI solutions for Venture Capital and Private Equity backed companies in the following industries: Medical Technology, News/Content Aggregation, Film & Photo Production, Educational Technology, Legal Technology, Fintech & Cryptocurrency.


