
10 Proven Strategies to Cut Your LLM Costs



As organizations increasingly rely on large language models (LLMs) for various applications, from customer service chatbots to content generation, the challenge of LLM cost management has come to the forefront. The operational costs associated with deploying and maintaining LLMs can quickly spiral out of control without proper oversight and optimization strategies. Unexpected cost spikes can derail budgets and hinder the widespread adoption of these powerful tools.
This blog post will explore ten proven strategies to help your enterprise effectively manage LLM costs, ensuring you can harness the full potential of these models while maintaining cost efficiency and control over expenses.
Strategy 1: Smart Model Selection
One of the most impactful strategies for LLM cost management is selecting the right model for each task. Not every application requires the most advanced and largest models available. By matching model complexity to task requirements, you can significantly reduce costs without sacrificing performance.
When implementing LLM applications, it’s crucial to assess the complexity of each task and choose a model that meets those specific needs. For instance, simple classification tasks or basic question-answering may not require the full capabilities of GPT-4o or other large, resource-intensive models.
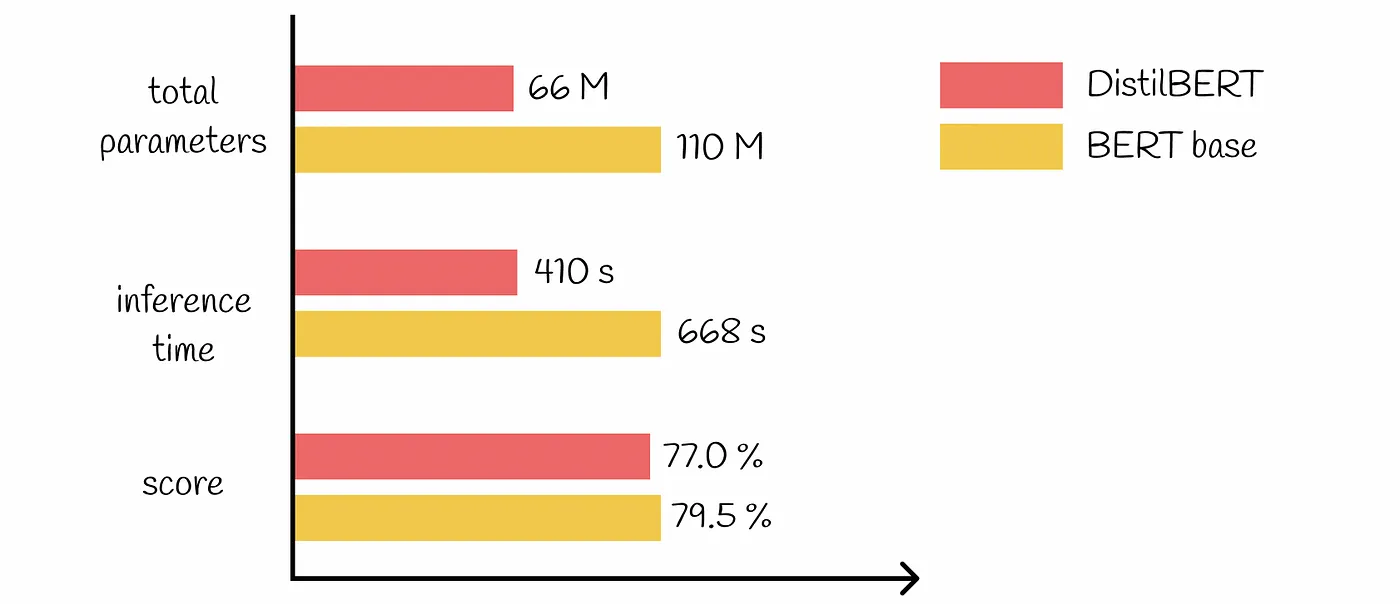
Many pre-trained models are available at various sizes and complexities. Opting for smaller, more efficient models for straightforward tasks can lead to substantial cost savings. For example, you might use a lightweight model like DistilBERT for sentiment analysis instead of a more complex model like BERT-Large.
Strategy 2: Implement Robust Usage Tracking
Effective LLM cost management begins with a clear understanding of how these models are being used across your organization. Implementing robust usage tracking mechanisms is essential for identifying areas of inefficiency and opportunities for optimization.
To gain a comprehensive view of your LLM usage, it’s crucial to track metrics at multiple levels:
Conversation level: Monitor token usage, response times, and model calls for individual interactions.
User level: Analyze patterns in model usage across different users or departments.
Company level: Aggregate data to understand overall LLM consumption and trends.
Several tools and platforms are available to help track LLM usage effectively. These may include:
Built-in analytics dashboards provided by LLM service providers
Third-party monitoring tools designed specifically for AI and ML applications
Custom-built tracking solutions integrated with your existing infrastructure
By analyzing usage data, you can uncover valuable insights that lead to cost reduction strategies. For example, you might discover that certain departments are overusing more expensive models for tasks that could be handled by lower-cost alternatives. Or you might identify patterns of redundant queries that could be addressed through caching or other optimization techniques.
Strategy 3: Optimize Prompt Engineering
Prompt engineering is a critical aspect of working with LLMs, and it can have a significant impact on both performance and cost. By optimizing your prompts, you can reduce token usage and improve the efficiency of your LLM applications.
To minimize the number of API calls and reduce associated costs:
Use clear and specific instructions in your prompts
Implement error handling to address common issues without requiring additional LLM queries
Utilize prompt templates that have been proven effective for specific tasks
The way you structure your prompts can significantly affect the number of tokens processed by the model. Some best practices include:
Being concise and avoiding unnecessary context
Using formatting techniques like bullet points or numbered lists to organize information efficiently
Leveraging built-in functions or parameters provided by the LLM service to control output length and format
By implementing these prompt optimization techniques, you can substantially reduce token usage and, consequently, the costs associated with your LLM applications.
Strategy 4: Leverage Fine-tuning for Specialization
Fine-tuning pre-trained models for specific tasks is a powerful technique in LLM cost management. By tailoring models to your unique needs, you can achieve better performance with smaller, more efficient models, leading to significant cost savings.
Instead of relying solely on large, general-purpose LLMs, consider fine-tuning smaller models for specialized tasks. This approach allows you to leverage the knowledge of pre-trained models while optimizing for your specific use case.
While fine-tuning requires an initial investment, it can lead to substantial long-term savings. Fine-tuned models often require fewer tokens to achieve the same or better results, reducing inference costs. They may also require fewer retries or corrections due to improved accuracy, further reducing costs. Additionally, specialized models can often be smaller, reducing computational overhead and associated expenses.
To maximize the benefits of fine-tuning, start with a smaller pre-trained model as your base. Use high-quality, domain-specific data for fine-tuning, and regularly evaluate the model’s performance and cost-efficiency. This ongoing optimization process ensures that your fine-tuned models continue to deliver value while keeping costs in check.
Strategy 5: Explore Free and Low-Cost Options
For many enterprises, especially during development and testing phases, leveraging free or low-cost LLM options can significantly reduce expenses without compromising on quality. These options are particularly valuable for prototyping new LLM applications, training developers on LLM implementation, and running non-critical or internal-facing services.
However, while free options can drastically cut costs, it’s crucial to consider the trade-offs. Data privacy and security implications should be carefully evaluated, especially when dealing with sensitive information. Additionally, be aware of potential limitations in model capabilities or customization options. Consider long-term scalability and migration paths to ensure that your cost-saving measures don’t become obstacles to future growth.
Strategy 6: Optimize Context Window Management
The size of the context window in LLMs can significantly impact both performance and costs. Effective management of context windows is crucial for controlling expenses while maintaining output quality. Larger context windows allow for more comprehensive understanding but come at a higher cost due to increased token usage per query and higher computational requirements.
To optimize context window usage, consider implementing dynamic context sizing based on task complexity. Use summarization techniques to condense relevant information, and employ sliding window approaches for long documents or conversations. These methods can help you find the sweet spot between comprehension and cost-efficiency.
Regularly analyze the relationship between context size and output quality to fine-tune your approach. Adjust context windows based on specific task requirements, and consider implementing a tiered approach, using larger contexts only when necessary. By carefully managing your context windows, you can significantly reduce token usage and associated costs without sacrificing the quality of your LLM outputs.
Strategy 7: Implement Multi-Agent Systems
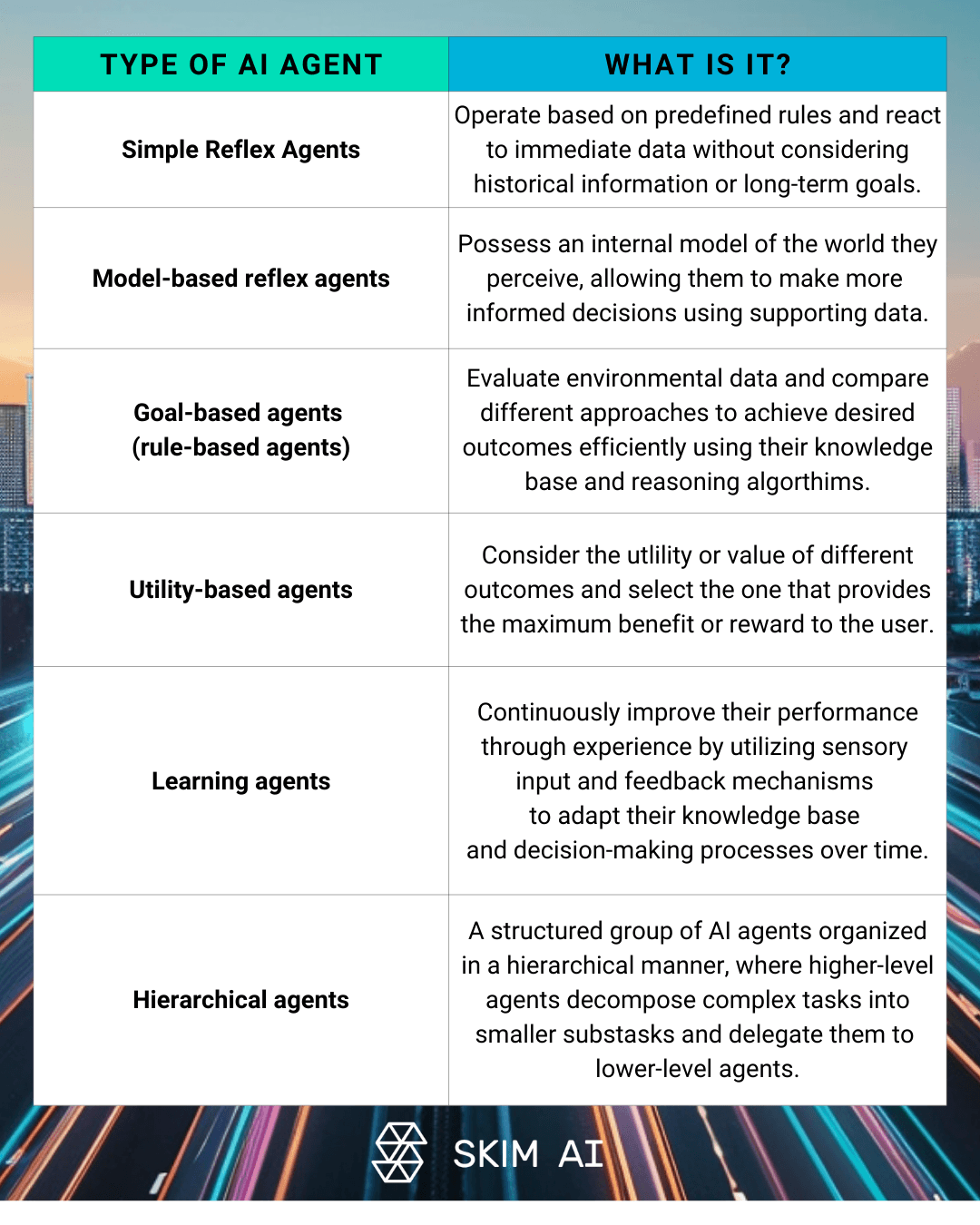
Multi-agent systems offer a powerful approach to enhancing the efficiency and cost-effectiveness of LLM applications. By distributing tasks among specialized agents, enterprises can optimize resource allocation and reduce overall LLM costs.
Multi-agent LLM architectures involve multiple AI agents working collaboratively to solve complex problems. This approach can include specialized agents for different aspects of a task, hierarchical structures with oversight and worker agents, or collaborative problem-solving among multiple LLMs. By implementing such systems, organizations can reduce their reliance on expensive, large-scale models for every task.
The cost benefits of distributed task handling are significant. Multi-agent systems allow for:
Optimized resource allocation based on task complexity
Improved overall system efficiency and response times
Reduced token usage through targeted model deployment
However, to maintain cost-efficiency in multi-agent systems, it’s crucial to implement robust debugging mechanisms. This includes logging and monitoring inter-agent communications, analyzing token usage patterns to identify redundant exchanges, and optimizing the division of labor among agents to minimize unnecessary token consumption.
Strategy 8: Utilize Output Formatting Tools
Proper output formatting is a key factor in LLM cost management. By ensuring efficient use of tokens and minimizing the need for additional processing, enterprises can significantly reduce their operational costs.
These tools offer powerful capabilities for forced function outputs, allowing developers to specify exact formats for LLM responses. This approach reduces variability in outputs and minimizes token waste by ensuring the model generates only the necessary information.
Reducing variability in LLM outputs has a direct impact on associated costs. Consistent, well-structured responses decrease the likelihood of malformed or unusable outputs, which in turn reduces the need for additional API calls to clarify or reformat information.
Implementing JSON outputs can be particularly effective for efficiency. JSON offers compact representation of structured data, easy parsing and integration with various systems, and reduced token usage compared to natural language responses. By leveraging these output formatting tools, enterprises can streamline their LLM workflows and optimize token usage.
Strategy 9: Integrate Non-LLM Tools
While LLMs are powerful, they’re not always the most cost-effective solution for every task. Integrating non-LLM tools into your workflows can significantly reduce operational costs while maintaining high-quality outputs.
Incorporating Python scripts to handle specific tasks that don’t require the full capabilities of an LLM can lead to substantial cost savings. For instance, simple data processing or rule-based decision-making can often be more efficiently handled by traditional programming approaches.
When balancing LLM and traditional tools in workflows, consider the complexity of the task, the required accuracy, and the potential cost savings. A hybrid approach that leverages the strengths of both LLMs and conventional tools often yields the best results in terms of performance and cost-efficiency.
Conducting a thorough cost-benefit analysis of hybrid approaches is crucial. This analysis should consider factors such as:
Development and maintenance costs of custom tools
Processing time and resource requirements
Accuracy and reliability of outputs
Long-term scalability and flexibility
Strategy 10: Regular Auditing and Optimization
Establishing LLM cost management techniques is an ongoing process that requires constant vigilance and optimization. Regular auditing of your LLM usage and costs is crucial for identifying inefficiencies and implementing improvements for cost control.
The importance of ongoing cost management and cost reduction cannot be overstated. As your LLM applications evolve and scale, new challenges and opportunities for optimization will emerge. By consistently monitoring and analyzing your LLM usage, you can stay ahead of potential cost overruns and ensure that your AI investments deliver maximum value.
To identify wasted tokens, implement robust tracking and analysis tools. Look for patterns of redundant queries, excessive context windows, or inefficient prompt designs. Use this data to refine your LLM strategies and eliminate unnecessary token consumption.
Finally, fostering a culture of cost-consciousness within your organization is key to long-term success in LLM efficient resource management. Encourage teams to consider the cost implications of their LLM usage and to actively seek out opportunities for optimization and to control expenses. By making cost-efficiency a shared responsibility, you can ensure that your enterprise reaps the full benefits of LLM technology while keeping expenses under control.
The Bottom Line
As large language models continue to impact enterprise AI applications, mastering LLM cost management becomes crucial for long-term success. By implementing the ten strategies outlined in this article, from smart model selection to regular auditing and optimization, your organization can significantly reduce LLM costs while maintaining or even improving performance. Remember that effective cost management is an ongoing process that requires continuous monitoring, analysis, and adaptation. By fostering a culture of cost-consciousness and leveraging the right tools and techniques, you can harness the full potential of LLMs while keeping operational costs under control, ensuring that your AI investments deliver maximum value to your enterprise.
Don’t hesitate to reach out to learn more about LLM cost management.


