
Esercitazione: Come mettere a punto BERT per il riconoscimento di entità denominate (NER)



Esercitazione: Come mettere a punto il BERT per il NER
Pubblicato originariamente dal ricercatore di apprendimento automatico di Skim AI, Chris Tran.![]()
Introduzione
Questo articolo spiega come mettere a punto BERT per il riconoscimento di entità denominate (NER). In particolare, come addestrare una variante di BERT, SpanBERTa, per la NER. È la parte II di III di una serie sull'addestramento di modelli linguistici BERT personalizzati per lo spagnolo per diversi casi d'uso:
- Parte I: Come addestrare un modello linguistico RoBERTa per lo spagnolo partendo da zero
- Parte III: Come addestrare un modello linguistico ELECTRA per lo spagnolo partendo da zero
Nel mio precedente post sul blog, abbiamo discusso di come il mio team abbia preaddestrato SpanBERTa, un modello linguistico trasformatore per lo spagnolo, su un corpus di grandi dimensioni partendo da zero. Il modello ha dimostrato di essere in grado di prevedere correttamente le parole mascherate in una sequenza in base al loro contesto. In questo post, per sfruttare davvero la potenza dei modelli trasformatori, metteremo a punto SpanBERTa per un compito di riconoscimento di un'identità.
Secondo la sua definizione su WikipediaIl riconoscimento di entità denominate (NER) (noto anche come identificazione di entità, chunking di entità ed estrazione di entità) è un compito secondario dell'estrazione di informazioni che cerca di individuare e classificare le entità nominate in un testo non strutturato in categorie predefinite, come nomi di persone, organizzazioni, località, codici medici, espressioni temporali, quantità, valori monetari, percentuali, ecc.
Utilizzeremo lo script run_ner.py di Hugging Face e Set di dati CoNLL-2002 per mettere a punto SpanBERTa.
Impostazione
Scarica trasformatori e installare i pacchetti necessari.
%%capture
!git clone https://github.com/huggingface/transformers
%cd transformers
!pip install .
!pip install -r ./examples/requirements.txt
%cd ..
Dati
1. Scaricare i set di dati
Il comando seguente scarica e decomprime il set di dati. I file contengono i dati di addestramento e di test per tre parti del programma CoNLL-2002 compito condiviso:
- esp.testa: Dati di prova spagnoli per la fase di sviluppo
- esp.testb: dati di test spagnoli
- esp.train: Dati ferroviari spagnoli
%pture
!wget -O 'conll2002.zip' 'https://drive.google.com/uc?export=download&id=1Wrl1b39ZXgKqCeAFNM9EoXtA1kzwNhCe'
!unzip 'conll2002.zip'
La dimensione di ciascun set di dati:
wc -l conll2002/esp.train
wc -l conll2002/esp.testa
wc -l conll2002/esp.testb
273038 conll2002/esp.treno
54838 conll2002/esp.testa
53050 conll2002/esp.testb
Tutti i file di dati hanno tre colonne: parole, tag part-of-speech associati e tag named entity nel formato IOB2. Le interruzioni di frase sono codificate da righe vuote.
!head -n20 conll2002/esp.train
Melbourne NP B-LOC
( Fpa O
Australia NP B-LOC
) Fpt O
, Fc O
25 Z O
può NC O
( Fpa O
EFE NC B-ORG
) Fpt O
. Fp O
- Fg O
El DA O
Abogado NC B-PER
Generale AQ I-PER
del SP I-PER
Estado NC I-PER
, Fc O
Per i nostri dataset train, dev e test, conserveremo solo la colonna delle parole e quella dei tag delle entità denominate.
!"cat conll2002/esp.train | cut -d " " -f 1,3 > train_temp.txt
!cat conll2002/esp.testa | cut -d " -f 1,3 > dev_temp.txt
!cat conll2002/esp.testb | cut -d " -f 1,3 > test_temp.txt
2. Preelaborazione
Definiamo alcune variabili che ci servono per le successive fasi di pre-elaborazione e per l'addestramento del modello:
MAX_LENGTH = 120 #@param {type: "integer"}
MODEL = "chriskhanhtran/spanberta" #@param ["chriskhanhtran/spanberta", "bert-base-multilingual-cased"]
Lo script seguente divide le frasi più lunghe di LUNGHEZZA MASSIMA (in termini di token) in piccole frasi. In caso contrario, le frasi lunghe verranno troncate durante la tokenizzazione, causando la perdita di dati di addestramento e la mancata previsione di alcuni token nel set di test.
%pture
!wget "https://raw.githubusercontent.com/stefan-it/fine-tuned-berts-seq/master/scripts/preprocess.py"
!python3 preprocess.py train_temp.txt $MODEL $MAX_LENGTH > train.txt
!python3 preprocess.py dev_temp.txt $MODEL $MAX_LENGTH > dev.txt
!python3 preprocess.py test_temp.txt $MODEL $MAX_LENGTH > test.txt
2020-04-22 23:02:05.747294: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Aperta con successo la libreria dinamica libcudart.so.10.1
Download: 100% 1.03k/1.03k [00:00<00:00, 704kB/s]
Download: 100% 954k/954k [00:00<00:00, 1.89MB/s]
Download: 100% 512k/512k [00:00<00:00, 1,19MB/s]
Download: 100% 16.0/16.0 [00:00<00:00, 12.6kB/s]
2020-04-22 23:02:23.409488: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Aperta con successo la libreria dinamica libcudart.so.10.1
2020-04-22 23:02:31.168967: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Aperta con successo la libreria dinamica libcudart.so.10.1
3. Etichette
Nei dataset CoNLL-2002/2003 sono presenti 9 classi di tag NER:
- O, Al di fuori di un'entità denominata
- B-MIS, Inizio di un'entità varia subito dopo un'altra entità varia
- I-MIS, entità varie
- B-PER, inizio del nome di una persona subito dopo il nome di un'altra persona
- I-PER, Nome della persona
- B-ORG, Inizio di un'organizzazione subito dopo un'altra organizzazione
- I-ORG, Organizzazione
- B-LOC, Inizio di una località subito dopo un'altra località
- I-LOC, Posizione
Se il vostro set di dati ha etichette diverse o più etichette rispetto ai set di dati CoNLL-2002/2003, eseguite la riga seguente per ottenere etichette uniche dai vostri dati e salvarle in etichette.txt. Questo file verrà utilizzato quando inizieremo a mettere a punto il nostro modello.
cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
Modello di messa a punto
Questi sono gli script di esempio di trasformatoriche useremo per mettere a punto il nostro modello per la NER. Dopo il 21/04/2020, Hugging Face ha aggiornato i suoi script di esempio per utilizzare un nuovo modello Allenatore classe. Per evitare qualsiasi conflitto futuro, usiamo la versione precedente agli aggiornamenti.
%pture
wget "https://raw.githubusercontent.com/chriskhanhtran/spanish-bert/master/ner/run_ner.py"
!wget "https://raw.githubusercontent.com/chriskhanhtran/spanish-bert/master/ner/utils_ner.py"
Ora è il momento dell'apprendimento per trasferimento. Nel mio post precedenteHo preaddestrato un modello linguistico RoBERTa su un corpus spagnolo molto ampio per prevedere le parole mascherate in base al contesto in cui si trovano. In questo modo, il modello ha appreso le proprietà intrinseche della lingua. Ho caricato il modello preaddestrato sul server di Hugging Face. Ora caricheremo il modello e inizieremo a metterlo a punto per il compito NER.
Di seguito sono riportati gli iperparametri di addestramento.
MAX_LENGTH = 128 #@param {type: "integer"}
MODEL = "chriskhanhtran/spanberta" #@param ["chriskhanhtran/spanberta", "bert-base-multilingual-cased"]
OUTPUT_DIR = "spanberta-ner" #@param ["spanberta-ner", "bert-base-ml-ner"]
BATCH_SIZE = 32 #@param {type: "integer"}
NUM_EPOCHS = 3 #@param {type: "integer"}
SAVE_STEPS = 100 #@param {type: "intero"}
LOGGING_STEPS = 100 #@param {type: "integer"}
SEED = 42 #@param {type: "integer"}
Iniziamo l'allenamento.
python3 run_ner.py
--data_dir ./
-tipo_modello bert
--labels ./labels.txt
-nome_modello_o_percorso $MODEL
--output_dir $OUTPUT_DIR
--lunghezza_seq_max $MAX_LENGTH
--num_train_epochs $NUM_EPOCHS
--per_gpu_train_batch_size $BATCH_SIZE
-passi di salvataggio $SAVE_STEPS
-passi di registrazione $LOGGING_STEPS
--semina $SEED
--do_train
--do_eval
--do_predict
--sovrascrivere_uscita_dir
Prestazioni sul dev set:
21/04/2020 02:24:31 - INFO - __main__ - ***** Risultati della valutazione *****
21/04/2020 02:24:31 - INFO - __main__ - f1 = 0.831027443864822
21/04/2020 02:24:31 - INFO - __main__ - perdita = 0.1004064822183894
21/04/2020 02:24:31 - INFO - __main__ - precisione = 0.8207885304659498
04/21/2020 02:24:31 - INFO - __main__ - recall = 0.8415250344510795
Prestazioni sul set di test:
21/04/2020 02:24:48 - INFO - __main__ - ***** Risultati della valutazione *****
21/04/2020 02:24:48 - INFO - __main__ - f1 = 0.8559533721898419
21/04/2020 02:24:48 - INFO - __main__ - perdita = 0.06848683688204177
21/04/2020 02:24:48 - INFO - __main__ - precisione = 0.845858475041141
04/21/2020 02:24:48 - INFO - __main__ - recall = 0.8662921348314607
Ecco le tavole tensoriali di fine-tuning spanberta e bert-base-multilingue-casuale per 5 epoche. Si può notare che i modelli si adattano eccessivamente ai dati di addestramento dopo 3 epoche.
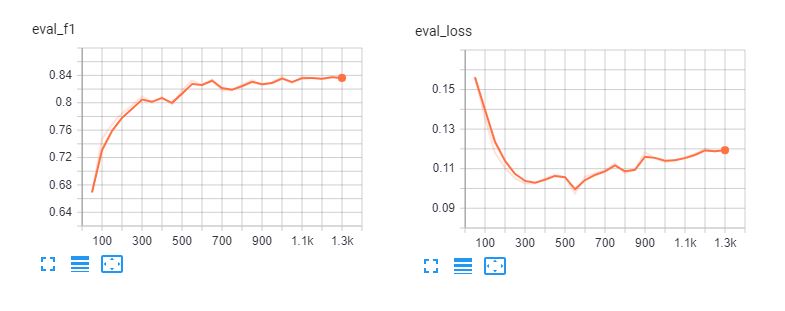
Rapporto di classificazione
Per capire quanto sia efficace il nostro modello, carichiamo le sue previsioni ed esaminiamo il rapporto di classificazione.
def read_examples_from_file(file_path):
"""Legge parole ed etichette da un file di dati CoNLL-2002/2003.
Args:
file_path (str): percorso del file di dati NER.
Restituisce:
esempi (dict): un dizionario con due chiavi: parole (elenco di elenchi)
tenendo le parole in ogni sequenza, e etichette (elenco di elenchi) con le
etichette corrispondenti.
"""
con open(file_path, encoding="utf-8") as f:
esempi = {"parole": [], "etichette": []}
parole = []
etichette = []
per riga in f:
se line.startswith("-DOCSTART-") o line == "" o line == "\n":
if parole:
esempi["parole"].append(parole)
esempi["etichette"].append(etichette)
parole = []
etichette = []
else:
splits = line.split(" ")
words.append(splits[0])
se len(splits) > 1:
labels.append(splits[-1].replace("\n", ""))
altrimenti:
# Gli esempi potrebbero non avere un'etichetta per mode = "test".
labels.append("O")
restituire gli esempi
Leggere i dati e le etichette dai file di testo grezzi:
y_true = read_examples_from_file("test.txt")["labels"]
y_pred = read_examples_from_file("spanberta-ner/test_predictions.txt")["labels"]
Stampare il rapporto di classificazione:
da seqeval.metrics import classification_report as classification_report_seqeval
print(classification_report_seqeval(y_true, y_pred))
precision recall f1-score support
LOC 0,87 0,84 0,85 1084
ORG 0,82 0,87 0,85 1401
MISC 0,63 0,66 0,65 340
PER 0,94 0,96 0,95 735
micro avg 0,84 0,86 0,85 3560
macro avg 0,84 0,86 0,85 3560
Le metriche che vediamo in questo rapporto sono state progettate specificamente per compiti NLP come NER e POS tagging, in cui tutte le parole di un'entità devono essere predette correttamente per essere conteggiate come una previsione corretta. Pertanto, le metriche in questo rapporto di classificazione sono molto più basse rispetto a quelle di Rapporto di classificazione di scikit-learn.
importare numpy come np
da sklearn.metrics import classification_report
print(classification_report(np.concatenate(y_true), np.concatenate(y_pred))
precision recall f1-score support
B-LOC 0,88 0,85 0,86 1084
B-MISC 0,73 0,73 0,73 339
B-ORG 0,87 0,91 0,89 1400
B-PER 0,95 0,96 0,95 735
I-LOC 0,82 0,81 0,81 325
I-MISC 0,85 0,76 0,80 557
I-ORG 0,89 0,87 0,88 1104
I-PER 0,98 0,98 0,98 634
O 1.00 1.00 1.00 45355
precisione 0,98 51533
macro avg 0,89 0,87 0,88 51533
media ponderata 0,98 0,98 0,98 51533
Da quanto sopra riportato, il nostro modello ha una buona performance nella previsione di persone, luoghi e organizzazioni. Avremo bisogno di più dati per MISC per migliorare le prestazioni del nostro modello su queste entità.
Condotte
Dopo aver messo a punto i nostri modelli, possiamo condividerli con la comunità seguendo l'esercitazione in questa pagina. pagina. Ora possiamo iniziare a caricare il modello ottimizzato dal server di Hugging Face e usarlo per prevedere le entità denominate nei documenti spagnoli.
da transformers import pipeline, AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("skimai/spanberta-base-cased-ner-conll02")
tokenizer = AutoTokenizer.from_pretrained("skimai/spanberta-base-cased-ner-conll02")
ner_model = pipeline('ner', model=model, tokenizer=tokenizer)
L'esempio seguente è ottenuto da La Opinión e significa "La ripresa economica degli Stati Uniti dopo la pandemia di coronavirus sarà una questione di mesi, ha dichiarato il Segretario al Tesoro Steven Mnuchin."
sequence = "La ripresa economica degli Stati Uniti dopo la " ″pandemia″ del coronavirus sarà una questione di mesi.
"pandemia del coronavirus sarà una questione di mesi, ha dichiarato il " \
"Secretario del Tesoro, Steven Mnuchin".
ner_model(sequence)
[{'entità': 'B-ORG', 'punteggio': 0.9155661463737488, 'parola': 'ĠEstados'},
{'entità': 'I-ORG', 'punteggio': 0.800682544708252, 'parola': 'ĠUnidos'},
{'entità': 'I-MISC', 'punteggio': 0.5006815791130066, 'parola': 'Ġcorona'},
{'entità': 'I-MISC', 'punteggio': 0.510674774646759, 'parola': 'virus'},
{'entità': 'B-PER', 'punteggio': 0.5558510422706604, 'parola': 'ĠSegretario'},
{'entità': 'I-PER', 'punteggio': 0.7758238315582275, 'parola': 'Ġdel'},
{'entità': 'I-PER', 'punteggio': 0.7096233367919922, 'parola': 'ĠTesoro'},
{'entità': 'B-PER', 'punteggio': 0.9940345883369446, 'parola': 'ĠSteven'},
{'entità': 'I-PER', 'punteggio': 0.9962581992149353, 'parola': 'ĠM'},
{'entità': 'I-PER', 'punteggio': 0.9918380379676819, 'parola': 'n'},
{'entità': 'I-PER', 'punteggio': 0.9848328828811646, 'parola': 'uch'},
{'entità': 'I-PER', 'punteggio': 0.8513168096542358, 'parola': 'in'}]
Sembra perfetto! Il modello perfezionato riconosce tutte le entità del nostro esempio e riconosce anche il "virus corona".
Conclusione
Il riconoscimento dei nomi può aiutarci a estrarre rapidamente informazioni importanti dai testi. Pertanto, la sua applicazione nel mondo degli affari può avere un impatto diretto sul miglioramento della produttività umana nella lettura di contratti e documenti. Tuttavia, si tratta di un compito impegnativo per la PNL, perché il NER richiede una classificazione accurata a livello di parola, rendendo impossibile affrontare approcci semplici come il bag-of-word.
Abbiamo illustrato come sfruttare un modello BERT preaddestrato per ottenere rapidamente prestazioni eccellenti nel compito NER per lo spagnolo. Il modello SpanBERTa preaddestrato può essere messo a punto anche per altri compiti, come la classificazione dei documenti. Ho scritto un tutorial dettagliato per mettere a punto BERT per la classificazione delle sequenze e la sentiment analysis.
La prossima parte di questa serie è la terza, in cui parleremo di come utilizzare ELECTRA, un approccio di pre-addestramento più efficiente per i modelli di trasformatori che può raggiungere rapidamente prestazioni all'avanguardia. Restate sintonizzati!


