Навчальний посібник: Як налаштувати BERT для розпізнавання іменованих об'єктів (NER)



Навчальний посібник: Як налаштувати BERT для NER
Вперше опубліковано дослідником машинного навчання Skim AI, Крісом Траном.![]()
Вступ
Ця стаття про те, як налаштувати BERT для розпізнавання іменованих об'єктів (NER). Зокрема, про те, як тренувати варіацію BERT, SpanBERTa, для NER. Це друга частина третьої серії статей про навчання користувацьких мовних моделей BERT для іспанської мови для різноманітних випадків використання:
- Частина I: Як навчити мовну модель RoBERTa для іспанської мови з нуля
- Частина III: Як навчити мовну модель ELECTRA для іспанської мови з нуля
У моєму попередньому дописі в блозі ми обговорювали, як ми навчили SpanBERTa, мовну модель-трансформер для іспанської мови, на великому корпусі з нуля. Модель показала, що вона здатна правильно передбачати замасковані слова в послідовності, що базується на контексті. У цьому дописі блогу, щоб по-справжньому використати можливості моделей-трансформерів, ми налаштуємо SpanBERTa для завдання розпізнавання іменованих об'єктів.
Згідно з його визначенням на ВікіпедіяРозпізнавання іменованих об'єктів (NER) (також відоме як ідентифікація об'єктів, розбиття об'єктів на частини та вилучення об'єктів) - це підзадача вилучення інформації, яка має на меті знайти та класифікувати іменовані об'єкти, згадані в неструктурованому тексті, за попередньо визначеними категоріями, такими як імена людей, організації, місцезнаходження, медичні коди, часові вирази, кількості, грошові значення, відсотки тощо.
Ми використаємо скрипт run_ner.py Hugging Face та Набір даних CoNLL-2002 щоб налаштувати SpanBERTa.
Налаштування
Завантажити трансформатори і встановіть необхідні пакунки.
%%capture
!git clone https://github.com/huggingface/transformers
%cd transformers
!pip install .
!pip install -r ./examples/requirements.txt
%cd ..
Дані
1. Завантажити набори даних
Наведена нижче команда завантажить і розархівує набір даних. Файли містять дані поїздів і тестів для трьох частин CoNLL-2002 спільне завдання:
- esp.testa: Іспанські тестові дані для етапу розробки
- esp.testb: дані іспанського тесту
- esp.train: Дані про іспанські поїзди
%pture
!wget -O 'conll2002.zip' 'https://drive.google.com/uc?export=download&id=1Wrl1b39ZXgKqCeAFNM9EoXtA1kzwNhCe'
!розархівувати 'conll2002.zip'
Розмір кожного набору даних:
!wc -l conll2002/esp.train
!wc -l conll2002/esp.testa
!wc -l conll2002/esp.testb
273038 conll2002/esp.train
54838 conll2002/esp.testa
53050 conll2002/esp.testb
Усі файли даних мають три колонки: слова, пов'язані з ними теги частин мови та іменовані теги сутностей у форматі IOB2. Розриви речень кодуються порожніми рядками.
!head -n20 conll2002/esp.train
Мельбурнський НП B-LOC
( Fpa O
Австралія NP B-LOC
) Fpt O
, Fc O
25 Z O
may NC O
( Fpa O
EFE NC B-ORG
) Fpt O
. Fp O
- Fg O
El DA O
Abogado NC B-PER
General AQ I-PER
del SP I-PER
Estado NC I-PER
, Fc O
Ми збережемо лише стовпчик слів та стовпчик іменованих тегів сутностей для наших наборів даних train, dev та test.
!cat conll2002/esp.train | cut -d " " -f 1,3 > train_temp.txt
!cat conll2002/esp.testa | cut -d " " -f 1,3 > dev_temp.txt
!cat conll2002/esp.testb | cut -d " " -f 1,3 > test_temp.txt
2. Попередня обробка
Визначимо деякі змінні, які нам знадобляться для подальших кроків попередньої обробки та навчання моделі:
MAX_LENGTH = 120 #@param {type: "integer"}
MODEL = "chriskhanhtran/spanberta" #@param ["chriskhanhtran/spanberta", "bert-base-multilingual-cased"]
Наведений нижче скрипт розділить речення, довші за MAX_LENGTH (з точки зору токенів) на невеликі. В іншому випадку довгі речення будуть усікатися при токенізації, що призведе до втрати навчальних даних і непередбачуваності деяких токенів у тестовому наборі.
%pture
!wget "https://raw.githubusercontent.com/stefan-it/fine-tuned-berts-seq/master/scripts/preprocess.py"
!python3 preprocess.py train_temp.txt $MODEL $MAX_LENGTH > train.txt
!python3 preprocess.py dev_temp.txt $MODEL $MAX_LENGTH > dev.txt
!python3 preprocess.py test_temp.txt $MODEL $MAX_LENGTH > test.txt
2020-04-22 23:02:05.747294: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Успішно відкрито динамічну бібліотеку libcudart.so.10.1
Завантаження: 100% 1.03k/1.03k [00:00<00:00, 704kB/s]
Завантаження: 100% 954k/954k [00:00<00:00, 1.89MB/s].
Завантажуємо: 100% 512k/512k [00:00<00:00, 1.19MB/s].
Завантажуємо: 100% 16.0/16.0 [00:00<00:00, 12.6 КБ/с].
2020-04-22 23:02:23.409488: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Успішно відкрито динамічну бібліотеку libcudart.so.10.1
2020-04-22 23:02:31.168967: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Успішно відкрито динамічну бібліотеку libcudart.so.10.1
3. Етикетки
У наборах даних CoNLL-2002/2003 є 9 класів тегів NER:
- O, За межами названого об'єкта
- B-MIS, Початок різної сутності одразу після іншої різної сутності
- I-MIS, Інша організація
- B-PER, Початок імені особи одразу після імені іншої особи
- I-PER, Ім'я особи
- B-ORG, створення організації одразу після іншої організації
- I-ORG, Організація
- B-LOC, Початок локації одразу після іншої локації
- I-LOC, місцезнаходження
Якщо ваш набір даних має інші мітки або більше міток, ніж набір даних CoNLL-2002/2003, запустіть рядок нижче, щоб отримати унікальні мітки з ваших даних і збережіть їх у папці labels.txt. Цей файл буде використано, коли ми почнемо точне налаштування нашої моделі.
!cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
Тонке налаштування моделі
Ось приклади скриптів з трансформаториякі ми будемо використовувати для доопрацювання нашої моделі для NER. Після 21.04.2020 Hugging Face оновили свої приклади скриптів, щоб використовувати новий Тренер клас. Щоб уникнути конфліктів у майбутньому, давайте використовувати версію до того, як вони зробили ці оновлення.
%pture
!wget "https://raw.githubusercontent.com/chriskhanhtran/spanish-bert/master/ner/run_ner.py"
!wget "https://raw.githubusercontent.com/chriskhanhtran/spanish-bert/master/ner/utils_ner.py"
Тепер настав час для трансферного навчання. У моєму попередня публікація в блозіЯ попередньо навчив мовну модель RoBERTa на дуже великому корпусі іспанської мови передбачати замасковані слова на основі контексту, в якому вони перебувають. Таким чином, модель навчилася властивостям, притаманним мові. Я завантажив попередньо навчену модель на сервер Hugging Face. Зараз ми завантажимо модель і почнемо її тонке налаштування для завдання NER.
Нижче наведені наші гіперпараметри тренування.
MAX_LENGTH = 128 #@param {type: "integer"}
MODEL = "chriskhanhtran/spanberta" #@param ["chriskhanhtran/spanberta", "bert-base-multilingual-cased"]
OUTPUT_DIR = "spanberta-ner" #@param ["spanberta-ner", "bert-base-ml-ner"]
BATCH_SIZE = 32 #@param {type: "integer"}
NUM_EPOCHS = 3 #@param {type: "integer"}
SAVE_STEPS = 100 #@param {type: "integer"}
LOGGING_STEPS = 100 #@param {type: "integer"}
SEED = 42 #@param {type: "integer"}
Почнемо тренування.
!python3 run_ner.py
--data_dir ./
--model_type bert
--labels ./labels.txt
--model_name_or_path $MODEL
--output_dir $OUTPUT_DIR
--max_seq_length $MAX_LENGTH
--num_train_epochs $NUM_EPOCHS
--per_gpu_train_batch_size $BATCH_SIZE
--save_steps $SAVE_STEPS
--logging_steps $LOGGING_STEPS
--seed $SEED
--do_train
--do_eval
--do_predict
--overwrite_output_dir
Виступ на знімальному майданчику:
04/21/2020 02:24:31 - INFO - __main__ - ***** Результати оцінки *****
04/21/2020 02:24:31 - INFO - __main__ - f1 = 0.831027443864822
04/21/2020 02:24:31 - INFO - __main__ - loss = 0.1004064822183894
04/21/2020 02:24:31 - INFO - __main__ - точність = 0.8207885304659498
04/21/2020 02:24:31 - INFO - __main__ - відкликання = 0.8415250344510795
Продуктивність на тестовому наборі:
04/21/2020 02:24:48 - INFO - __main__ - ***** Результати оцінки *****
04/21/2020 02:24:48 - INFO - __main__ - f1 = 0.8559533721898419
04/21/2020 02:24:48 - INFO - __main__ - loss = 0.06848683688204177
04/21/2020 02:24:48 - INFO - __main__ - точність = 0.845858475041141
04/21/2020 02:24:48 - INFO - __main__ - відкликання = 0.8662921348314607
Ось тензорні дошки тонкого налаштування спанберта і bert-base-multilingual-cased для 5 епох. Ми бачимо, що моделі підганяються під навчальні дані після 3 епох.
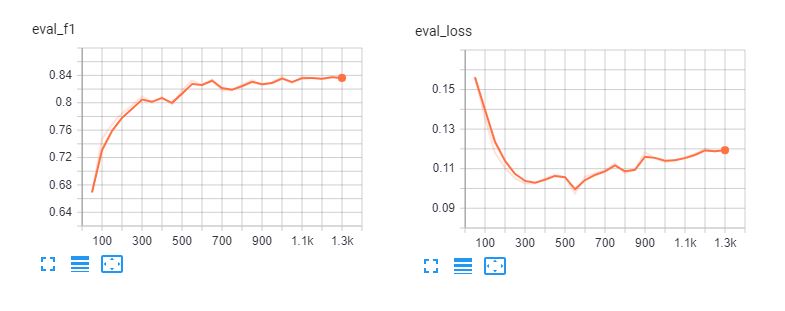
Звіт про класифікацію
Щоб зрозуміти, наскільки добре працює наша модель, завантажимо її прогнози і проаналізуємо звіт про класифікацію.
def read_examples_from_file(шлях до файлу):
"""Прочитати слова та мітки з файлу даних CoNLL-2002/2003.
Аргументи:
file_path (str): шлях до файлу даних NER.
Повертається:
examples (dict): словник з двома ключами: слова (список списків)
утримуючи слова у кожній послідовності, та етикетки (список списків), що мають
відповідні мітки.
"""
з open(шлях до файлу, кодування="utf-8") як f:
examples = {"words": [], "labels": []}
words = []
labels = []
for line in f:
if line.startswith("-DOCSTART-") or line == "" or line == "\n":
if words:
examples["words"].append(words)
examples["labels"].append(labels)
words = []
labels = []
else
splits = line.split(" ")
words.append(splits[0])
if len(splits) > 1:
labels.append(splits[-1].replace("\n", ""))
else:
# Приклади можуть не мати мітки для mode = "test"
labels.append("O")
повернути приклади
Зчитування даних і міток з необроблених текстових файлів:
y_true = read_examples_from_file("test.txt")["labels"].
y_pred = read_examples_from_file("spanberta-ner/test_predictions.txt")["labels"].
Роздрукуйте звіт про класифікацію:
from seqeval.metrics import classification_report as classification_report_seqeval
print(classification_report_seqeval(y_true, y_pred))
підтримка точного відкликання f1-score
LOC 0.87 0.84 0.85 1084
ORG 0.82 0.87 0.85 1401
MISC 0.63 0.66 0.65 340
PER 0.94 0.96 0.95 735
micro avg 0.84 0.86 0.85 3560
macro avg 0.84 0.86 0.85 3560
Метрики, які ми бачимо в цьому звіті, розроблені спеціально для завдань НЛП, таких як NER і POS-тегування, в яких всі слова сутності повинні бути правильно передбачені, щоб зарахувати їх як одне правильне передбачення. Тому метрики в цьому звіті про класифікацію набагато нижчі, ніж у Звіт про класифікацію scikit-learn.
import numpy as np
from sklearn.metrics import classification_report
print(classification_report(np.concatenate(y_true), np.concatenate(y_pred)))
підтримка точного відкликання f1-score
B-LOC 0.88 0.85 0.86 1084
B-MISC 0.73 0.73 0.73 339
B-ORG 0.87 0.91 0.89 1400
B-PER 0.95 0.96 0.95 735
I-LOC 0.82 0.81 0.81 325
I-MISC 0,85 0,76 0,80 557
I-ORG 0,89 0,87 0,88 1104
I-PER 0,98 0,98 0,98 634
O 1.00 1.00 1.00 45355
accuracy 0.98 51533
macro avg 0.89 0.87 0.88 51533
середньозважена 0.98 0.98 0.98 51533
З наведених вище звітів випливає, що наша модель має хороші показники в прогнозуванні особи, місцезнаходження та організації. Нам знадобиться більше даних для MISC для покращення ефективності нашої моделі на цих підприємствах.
Трубопровід
Після доопрацювання наших моделей ми можемо поділитися ними зі спільнотою, дотримуючись інструкцій у цьому посібнику сторінка. Тепер ми можемо почати завантажувати доопрацьовану модель з сервера Hugging Face і використовувати її для прогнозування іменованих сутностей в іспанських документах.
з конвеєра імпорту трансформаторів, AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("skimai/spanberta-base-cased-ner-conll02")
tokenizer = AutoTokenizer.from_pretrained("skimai/spanberta-base-cased-ner-conll02")
ner_model = pipeline('ner', model=model, tokenizer=tokenizer)
Приклад, наведений нижче, взято з La Opinion і означає "Економічне відновлення Сполучених Штатів після пандемії коронавірусу буде питанням кількох місяців, заявив міністр фінансів Стівен Мнучін."
sequence = "La recuperación económica de los Estados Unidos despuis de la " \
"пандемії коронавірусу буде питанням кількох місяців, стверджує " \
"Секретар Тесоро, Стівен Мнучін."
ner_model(sequence)
[{ 'entity': 'B-ORG', 'score': 0.9155661463737488, 'word': 'ĠEstados'},
{ 'entity': 'I-ORG', 'score': 0.800682544708252, 'word': 'ĠUnidos'},
{ 'entity': 'I-MISC', "score": 0.5006815791130066, "word": 'Ġcorona'},
{'entity': 'I-MISC', 'score': 0.510674774646759, 'word': 'virus'},
{'entity': 'B-PER', "score": 0.5558510422706604, "word": 'ĠSecretario'},
{'entity': 'I-PER', 'score': 0.7758238315582275, 'word': 'Ġdel'},
{'entity': 'I-PER', 'score': 0.7096233367919922, 'word': 'ĠTesoro'},
{'entity': 'B-PER', 'score': 0.9940345883369446, 'word': 'ĠSteven'},
{'entity': 'I-PER', 'score': 0.9962581992149353, 'word': 'ĠM'},
{'entity': 'I-PER', 'score': 0.9918380379676819, 'word': 'n'},
{'entity': 'I-PER', 'score': 0.9848328828811646, 'word': 'uch'},
{'entity': 'I-PER', 'score': 0.8513168096542358, 'word': 'in'}]
Виглядає чудово! Налаштована модель успішно розпізнає всі сутності в нашому прикладі, і навіть розпізнає "вірус корони".
Висновок
Розпізнавання іменованих об'єктів може допомогти нам швидко витягувати важливу інформацію з текстів. Тому його застосування в бізнесі може мати прямий вплив на підвищення продуктивності людини при читанні контрактів і документів. Однак це складне завдання для НЛП, оскільки NER вимагає точної класифікації на рівні слів, що унеможливлює використання простих підходів, таких як мішок слів, для вирішення цього завдання.
Ми розглянули, як можна використовувати попередньо навчену модель BERT для швидкого отримання відмінних результатів у завданні NER для іспанської мови. Попередньо навчену модель SpanBERTa також можна налаштувати для інших завдань, таких як класифікація документів. Я написав детальний посібник з налаштування BERT для класифікації послідовностей та аналізу настроїв.
У наступній частині цієї серії ми обговоримо, як використовувати ELECTRA, більш ефективний підхід до попереднього навчання моделей трансформаторів, який дозволяє швидко досягти найсучасніших характеристик. Залишайтеся з нами!