
チュートリアル名前付き固有表現認識(NER)のためのBERTの微調整方法



チュートリアルBERTをNER用に微調整する方法
原文はSkim AIの機械学習研究者、クリス・トラン。![]()
はじめに
この記事では、名前付き固有表現認識(NER)のために BERT を微調整する方法について説明する。具体的には、BERT のバリエーションである SpanBERTa を NER 用に訓練する方法です。これは、さまざまなユースケースのためのスペイン語のカスタム BERT 言語モデルのトレーニングに関するシリーズの第Ⅲ部の第Ⅱ部である:
前回のブログ記事で、私のチームがスペイン語用の変換言語モデルであるSpanBERTaをゼロから大きなコーパスで事前学習した方法を紹介した。このモデルは、文脈に基づいて、連続する単語の中で正しくマスクされた単語を予測できることを示しました。今回のブログポストでは、変換モデルのパワーを本当に活用するために、SpanBERTaを名前付きエンティティ認識タスク用に微調整します。
その定義によると ウィキペディア名前付きエンティティ認識(NER)(エンティティ識別、エンティティチャンキング、エンティティ抽出とも呼ばれる)は、情報抽出のサブタスクであり、構造化されていないテキストで言及されている名前付きエンティティを探し出し、人名、組織、場所、医療コード、時間表現、数量、金額、パーセンテージなど、あらかじめ定義されたカテゴリに分類することを目指す。
スクリプト run_ner.py ハギング・フェイスと CoNLL-2002データセット SpanBERTaを微調整する。
セットアップ
ダウンロード 変圧器 をインストールし、必要なパッケージをインストールする。
%%capture
!git clone https://github.com/huggingface/transformers
%cd transformers
!pip install .
!pip install -r ./examples/requirements.txt
%cd ..
データ
1.データセットのダウンロード
以下のコマンドはデータセットをダウンロードし,解凍する.ファイルには、以下の3つの部分の訓練データとテストデータが含まれている。 CoNLL-2002 タスクを共有する:
- esp.testa:開発段階のスペイン語テストデータ
- esp.testb: スペインのテストデータ
- esp.train:スペインの列車データ
%%キャプチャ
!wget -O 'conll2002.zip' 'https://drive.google.com/uc?export=download&id=1Wrl1b39ZXgKqCeAFNM9EoXtA1kzwNhCe'
!unzip 'conll2002.zip'
各データセットのサイズ:
!wc -l conll2002/esp.train
!wc -l conll2002/esp.testa
!wc -l conll2002/esp.testb
273038 コンエル2002/ESP.トレイン
54838 conll2002/esp.testa
53050 conll2002/esp.testb
すべてのデータファイルには、単語、関連する品詞タグ、およびIOB2形式の名前付きエンティティタグの3つの列がある。文の区切りは空行でエンコードされる。
!.head -n20 conll2002/esp.train
メルボルン NP B-LOC
( Fpa O
オーストラリアNP B-LOC
)Fpt O
Fc
25 Z O
may NC O
( Fpa O
EFE NC B-ORG
)Fpt O
.Fp O
- Fg O
DA
アボガド NC B-PER
ゼネラルAQ I-PER
SP I-PER
国家 NC I-PER
Fc O
ここでは、訓練データセット、開発データセット、テストデータセットについて、単語列と名前付きエンティティ・タグ列のみを保持する。
!cat conll2002/esp.train | cut -d " " -f 1,3 > train_temp.txt
!cat conll2002/esp.testa | cut -d " " -f 1,3 > dev_temp.txt
!cat conll2002/esp.testb | cut -d " " -f 1,3 > test_temp.txt
2.前処理
さらなる前処理ステップとモデルのトレーニングに必要な変数を定義しよう:
MAX_LENGTH = 120 #@param {タイプ:整数}
MODEL = "chriskhanhtran/spanberta" #@param ["chriskhanhtran/spanberta", "bert-base-multilingual-cased"].
以下のスクリプトは MAX_LENGTH (トークンに換算して)を小さなものに変換する。そうしないと、トークン化されたときに長い文が切り捨てられ、学習データが失われたり、テストセット内のいくつかのトークンが予測されなかったりする。
%%キャプチャ
!wget "https://raw.githubusercontent.com/stefan-it/fine-tuned-berts-seq/master/scripts/preprocess.py"
!python3 preprocess.py train_temp.txt $MODEL $MAX_LENGTH > train.txt
!python3 preprocess.py dev_temp.txt $MODEL $MAX_LENGTH > dev.txt
!python3 preprocess.py test_temp.txt $MODEL $MAX_LENGTH > test.txt
2020-04-22 23:02:05.747294:I tensorflow/stream_executor/platform/default/dso_loader.cc:44]。ダイナミックライブラリ libcudart.so.10.1 のオープンに成功しました。
ダウンロード中:100% 1.03k/1.03k [00:00<00:00, 704kB/s].
ダウンロード中100% 954k/954k [00:00<00:00, 1.89MB/s] をダウンロード中。
ダウンロード中100% 512k/512k [00:00<00:00, 1.19MB/s] の場合
ダウンロード中100% 16.0/16.0 [00:00<00:00, 12.6kB/s] ダウンロード中。
2020-04-22 23:02:23.409488: I tensorflow/stream_executor/platform/default/dso_loader.cc:44]ダイナミックライブラリ libcudart.so.10.1 のオープンに成功しました。
2020-04-22 23:02:31.168967:I tensorflow/stream_executor/platform/default/dso_loader.cc:44] 動的ライブラリのオープンに成功しました。ダイナミックライブラリ libcudart.so.10.1 のオープンに成功しました。
3.ラベル
CoNLL-2002/2003データセットでは、NERタグは9クラスある:
- O, 名前付きエンティティの外側
- B-MIS、他の雑多なエンティティの直後に雑多なエンティティの開始
- I-MIS、雑多なエンティティ
- B-PER、他の人の名前のすぐ後にある人の名前の冒頭部分
- I-PER、個人名
- B-ORG、他の組織のすぐ後にある組織の始まり
- I-ORG、組織
- B-LOC、他の場所の直後の場所の始まり
- I-LOC、ロケーション
もし、あなたのデータセットがCoNLL-2002/2003データセットと異なるラベルを持つか、それ以上のラベルを持つ場合は、以下の行を実行して、あなたのデータからユニークなラベルを取得し、それを以下に保存してください。 ラベル.txt.このファイルは、モデルの微調整を始めるときに使う。
cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
微調整モデル
以下は 変圧器のレポを使用して、NER用のモデルを微調整する。2020年4月21日以降、Hugging Faceはサンプルスクリプトを更新し、新しい トレーナー クラスを使用する。将来的な衝突を避けるために、これらのアップデートが行われる前のバージョンを使おう。
%%キャプチャ
!wget "https://raw.githubusercontent.com/chriskhanhtran/spanish-bert/master/ner/run_ner.py"
!wget "https://raw.githubusercontent.com/chriskhanhtran/spanish-bert/master/ner/utils_ner.py"
さあ、トランスファーラーニングの時間だ。私の 前のブログ記事私はRoBERTa言語モデルを非常に大規模なスペイン語コーパスに事前学習させ、文脈に基づいてマスクされた単語を予測するようにした。そうすることで、モデルは言語固有の特性を学習しました。学習済みのモデルをHugging Faceのサーバーにアップロードした。これからモデルをロードし、NERタスクのために微調整を開始する。
以下はトレーニングのハイパーパラメータである。
MAX_LENGTH = 128 #@param {タイプ:整数}
MODEL = "chriskhanhtran/spanberta" #@param ["chriskhanhtran/spanberta", "bert-base-multilingual-cased"].
OUTPUT_DIR = "spanberta-ner" #@param ["spanberta-ner", "bert-base-ml-ner"].
BATCH_SIZE = 32 #@param {type:整数}
NUM_EPOCHS = 3 #@param {type:整数}
SAVE_STEPS = 100 #@param {type:整数}
LOGGING_STEPS = 100 #@param {type:整数}
SEED = 42 #@param {type:整数}
トレーニングを始めよう
!python3 run_ner.py
--data_dir ./
--モデルタイプ bert
--ラベル ./labels.txt
--モデル名またはパス $MODEL
--output_dir $OUTPUT_DIR
-max_seq_length $MAX_LENGTH
--num_train_epochs $NUM_EPOCHS
--per_gpu_train_batch_size $BATCH_SIZE
-セーブステップ数 $SAVE_STEPS
--ロギングステップ $LOGGING_STEPS
--seed $SEED
--トレーニング
--評価
--予測
--overwrite_output_dir
開発セットでのパフォーマンス
04/21/2020 02:24:31 - INFO - __main__ - ***** 評価結果 *****
04/21/2020 02:24:31 - INFO - __main__ - f1 = 0.831027443864822
04/21/2020 02:24:31 - INFO - __main__ - loss = 0.1004064822183894
04/21/2020 02:24:31 - INFO - __main__ - 精度 = 0.8207885304659498
04/21/2020 02:24:31 - INFO - __main__ - 回収 = 0.8415250344510795
テストセットでのパフォーマンス:
04/21/2020 02:24:48 - INFO - __main__ - ***** 評価結果 *****
04/21/2020 02:24:48 - INFO - __main__ - f1 = 0.8559533721898419
04/21/2020 02:24:48 - INFO - __main__ - loss = 0.06848683688204177
04/21/2020 02:24:48 - INFO - __main__ - 精度 = 0.845858475041141
04/21/2020 02:24:48 - INFO - __main__ - 回収 = 0.8662921348314607
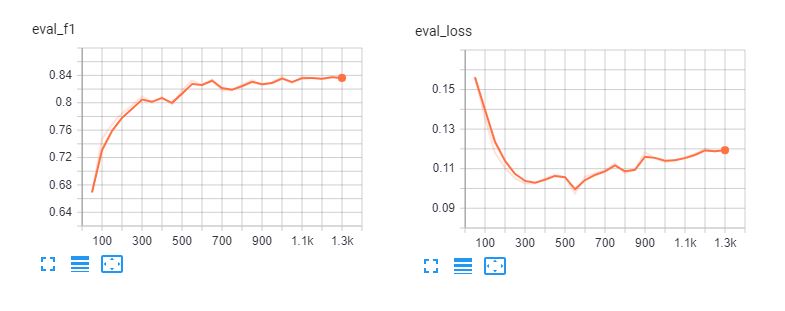
微調整のテンソルボードは以下の通り。 スパンベルタ そして バートベース多言語ケース を5エポッシュに渡って計算した。モデルは3エポッシュ後にトレーニングデータにオーバーフィットしていることがわかる。
分類レポート
このモデルの実際の性能を理解するために、予測値をロードして分類レポートを調べてみよう。
def read_examples_from_file(file_path):
"""CoNLL-2002/2003データファイルから単語とラベルを読み込む。
引数
file_path (str): NERデータファイルへのパス。
戻り値
examples (dict): 2つのキーを持つ辞書:words (リストのリスト)
各シーケンスで単語を保持し ラベル (リストのリスト
対応するラベルを保持する
"""
with open(file_path, encoding="utf-8") as f:
examples = {"words":単語": [], "ラベル":[]}
単語 = [], ラベル = [].
ラベル = [].
for line in f:
if line.startswith("-DOCSTART-") or line == "" or line == "♪n":
if words:
examples["words"].append(words)
例["ラベル"].append(ラベル)
words = [] (単語)
labels = [] (ラベル)
else:
splits = line.split(" ")
words.append(splits[0])
if len(splits) > 1:
labels.append(splits[-1].replace("\n", ""))
else:
# Example could have no label for mode = "test".
labels.append("O")
return examples
生テキストファイルからデータとラベルを読み込む:
y_true = read_examples_from_file("test.txt")["labels"].
y_pred = read_examples_from_file("spanberta-ner/test_predictions.txt")["labels"].
分類レポートを印刷する:
from seqeval.metrics import classification_report as classification_report_seqeval
print(classification_report_seqeval(y_true, y_pred))
精度 回想 f1 スコア サポート
loc 0.87 0.84 0.85 1084
org 0.82 0.87 0.85 1401
misc 0.63 0.66 0.65 340
0.94 0.96 0.95 735
マイクロアベレージ 0.84 0.86 0.85 3560
マクロ平均 0.84 0.86 0.85 3560
このレポートにあるメトリクスは、NERや品詞タグ付けのようなNLPタスクのために特別に設計されたもので、エンティティのすべての単語が正しく予測されなければ、1つの正しい予測としてカウントされない。したがって、この分類レポートのメトリクスは scikit-learnの分類レポート.
npとしてnumpyをインポート
from sklearn.metrics import classification_report
print(classification_report(np.concatenate(y_true), np.concatenate(y_pred)))
精度 回想 f1 スコア サポート
b-loc 0.88 0.85 0.86 1084
b-misc 0.73 0.73 0.73 339
b-org 0.87 0.91 0.89 1400
B-per 0.95 0.96 0.95 735
アイロック 0.82 0.81 0.81 325
i-misc 0.85 0.76 0.80 557
i-org 0.89 0.87 0.88 1104
i-per 0.98 0.98 0.98 634
O 1.00 1.00 1.00 45355
精度 0.98 51533
マクロ平均 0.89 0.87 0.88 51533
加重平均 0.98 0.98 0.98 51533
以上の報告から、我々のモデルは、人物、場所、組織の予測において良好なパフォーマンスを持っている。私たちは MISC エンティティのパフォーマンスを向上させる。
パイプライン
モデルを微調整したら、次のチュートリアルに従って、コミュニティと共有することができる。 ページ.これで、Hugging Faceのサーバーから微調整されたモデルをロードし、それを使ってスペイン語文書の名前付きエンティティを予測できるようになった。
from transformers import pipeline, AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("skimai/spanberta-base-cased-ner-conll02")
tokenizer = AutoTokenizer.from_pretrained("skimai/spanberta-base-cased-ner-conll02")
ner_model = pipeline('ner', model=model, tokenizer=tokenizer)
以下の例は ラ・オピニオン を意味する。スティーブン・ムニューシン財務長官は、コロナウイルスのパンデミック後の米国の経済回復は数ヶ月の問題であると述べた。"
sequence = "La recuperación económica de los Estados Unidos después de la" "コロナウイルスによるパンデミックからの回復には数ヶ月かかる。
"コロナウィルスの大流行は数カ月後の問題であると、スティーブン・ムニューシン"
"スティーブン・ムニューシン財務長官は"
ner_model(sequence)
[{'エンティティ':'B-ORG', 'score': 0.9155661463737488, 'word': 'ĠEstados'}、
{'entity':'I-ORG', 'score': 0.800682544708252, 'word': 'ĠUnidos'}、
{'entity':'I-MISC', 'score': 0.5006815791130066, 'word': 'Ġcorona'}、
{'entity':'I-MISC', 'score': 0.510674774646759, 'word': 'virus'}、
{'entity':'B-PER', 'score': 0.5558510422706604, 'word': 'ĠSecretario'}、
{'entity':'I-PER', 'score': 0.7758238315582275, 'word': 'Ġdel'}、
{'entity':'I-PER', 'score': 0.7096233367919922, 'word': 'ĠTesoro'}、
{'entity':B-PER', 'score': 0.9940345883369446, 'word': 'ĠSteven'}、
{'entity':'I-PER', 'score': 0.9962581992149353, 'word': 'ĠM'}、
{'entity':'I-PER', 'score': 0.9918380379676819, 'word': 'n'}、
{'entity':'entity': 'I-PER', 'score': 0.9848328828811646, 'word': 'uch'}、
{'entity':'I-PER', 'score': 0.8513168096542358, 'word': 'in'}].
素晴らしい!微調整されたモデルは、例のすべてのエンティティをうまく認識し、"コロナ・ウイルス "さえも認識する。
結論
名前付きエンティティ認識は、テキストから重要な情報を素早く抽出するのに役立つ。そのため、ビジネスへの応用は、契約書や文書を読む際の人間の生産性向上に直接的な影響を与える。しかし、NERは単語レベルでの正確な分類を必要とするため、Bag-of-Wordのような単純なアプローチではこのタスクに対処できない。
事前に訓練された BERT モデルを活用して、スペイン語の NER タスクで優れたパフォーマンスを素早く得る方法を説明した。事前に訓練された SpanBERTa モデルは、文書分類などの他のタスク用に微調整することもできます。シーケンス分類とセンチメント分析のために BERT を微調整する詳細なチュートリアルを書きました。
次回はパート3として、トランス・モデルの事前学習アプローチとしてより効率的で、迅速に最先端の性能を達成できるELECTRAの使用方法について説明します。ご期待ください!


