
Diferentes tipos de aprendizagem automática



Diferentes tipos de aprendizagem automática
A aprendizagem automática é um domínio em rápida evolução que tem o potencial de transformar muitos sectores, desde os cuidados de saúde às finanças e à indústria transformadora. No centro da aprendizagem automática estão quatro tipos principais de técnicas de aprendizagem: aprendizagem supervisionada, aprendizagem não supervisionada, aprendizagem semi-supervisionada, e aprendizagem por reforço.
Cada uma destas abordagens tem os seus próprios pontos fortes e fracos, e compreender como funcionam é crucial para a implementação bem sucedida de soluções de inteligência artificial (IA).
*Antes de mergulhar neste blogue sobre aprendizagem automática, não se esqueça de consultar o nosso artigo sobre IA vs. ML para saber a diferença entre os dois.
Aprendizagem supervisionada

A aprendizagem supervisionada é um tipo de aprendizagem automática em que o algoritmo é treinado num conjunto de dados rotulados. Isto significa que os dados de entrada já foram classificados ou etiquetados por humanos e o algoritmo aprende a fazer previsões com base nestes dados etiquetados. Na aprendizagem supervisionada, o algoritmo recebe os dados de entrada e os dados de saída correspondentes, e utiliza esta informação para aprender uma função de mapeamento entre os dois.
Uma das aplicações mais comuns da aprendizagem supervisionada é a classificação. Na classificação, o algoritmo é treinado para prever a que categoria pertence um ponto de dados de entrada. Por exemplo, um algoritmo de aprendizagem supervisionada pode ser treinado num conjunto de dados de imagens de gatos e cães, com cada imagem rotulada como "gato" ou "cão". Uma vez treinado, o algoritmo pode então receber uma nova imagem e prever se é um gato ou um cão.
Outra aplicação comum da aprendizagem supervisionada é a regressão. Na regressão, o algoritmo é treinado para prever um resultado numérico contínuo com base nos dados de entrada. Por exemplo, um algoritmo de aprendizagem supervisionada pode ser treinado num conjunto de dados de preços de casas, em que cada ponto de dados inclui informações como o tamanho da casa, o número de quartos e a localização. O algoritmo aprenderia então a prever o preço de uma nova casa com base nestas características.
Aprendizagem não supervisionada

A aprendizagem não supervisionada é outro tipo comum de aprendizagem automática em que, ao contrário da aprendizagem supervisionada, o algoritmo é treinado num conjunto de dados não rotulados. Na aprendizagem não supervisionada, o algoritmo não recebe qualquer informação sobre o resultado ou as etiquetas dos dados de entrada. Em vez disso, aprende a identificar padrões e estruturas nos dados por si próprio.
Uma das aplicações mais comuns da aprendizagem não supervisionada é o agrupamento. Os algoritmos de agrupamento agrupam pontos de dados semelhantes com base nas suas características, sem qualquer conhecimento prévio das etiquetas dos dados. Isto pode ser útil para tarefas como a segmentação de clientes, em que uma empresa pode querer agrupar clientes com base nos seus hábitos de compra ou noutros comportamentos.
Outra aplicação da aprendizagem não supervisionada é a redução da dimensionalidade. Os algoritmos de redução da dimensionalidade são utilizados para reduzir o número de características num conjunto de dados, preservando o máximo possível da informação original. Isto pode ser útil para tarefas como o reconhecimento de imagens e de voz, em que os dados de entrada podem ser altamente dimensionais e difíceis de processar.
Aprendizagem Semi-Supervisionada

Quando se trata de aprendizagem semi-supervisionada, é uma combinação de técnicas de aprendizagem supervisionadas e não supervisionadas. O algoritmo é treinado num conjunto de dados que contém dados etiquetados e não etiquetados.
Os dados etiquetados são utilizados para treinar o algoritmo de forma supervisionada, enquanto os dados não etiquetados são utilizados para ajudar o algoritmo a aprender mais sobre a estrutura subjacente dos dados. A ideia subjacente à aprendizagem semi-supervisionada é que os dados não rotulados podem ser utilizados para melhorar a precisão e a capacidade de generalização do algoritmo.
A aprendizagem semi-supervisionada é frequentemente utilizada no processamento de linguagem natural (PNL), que é um domínio da informática e da IA que se centra em permitir que as máquinas compreendam a linguagem escrita e falada de forma semelhante à dos seres humanos. Os modelos linguísticos são normalmente treinados em grandes quantidades de dados de texto não rotulados, que podem ser utilizados para melhorar a precisão de tarefas como a classificação de textos e a tradução de línguas.
A aprendizagem semi-supervisionada também pode ser utilizada em tarefas como o reconhecimento de imagens e de voz, em que a quantidade de dados etiquetados pode ser limitada ou dispendiosa de obter. Ao tirar partido dos dados não rotulados disponíveis, o algoritmo pode melhorar o seu desempenho na tarefa em causa.
Aprendizagem por reforço
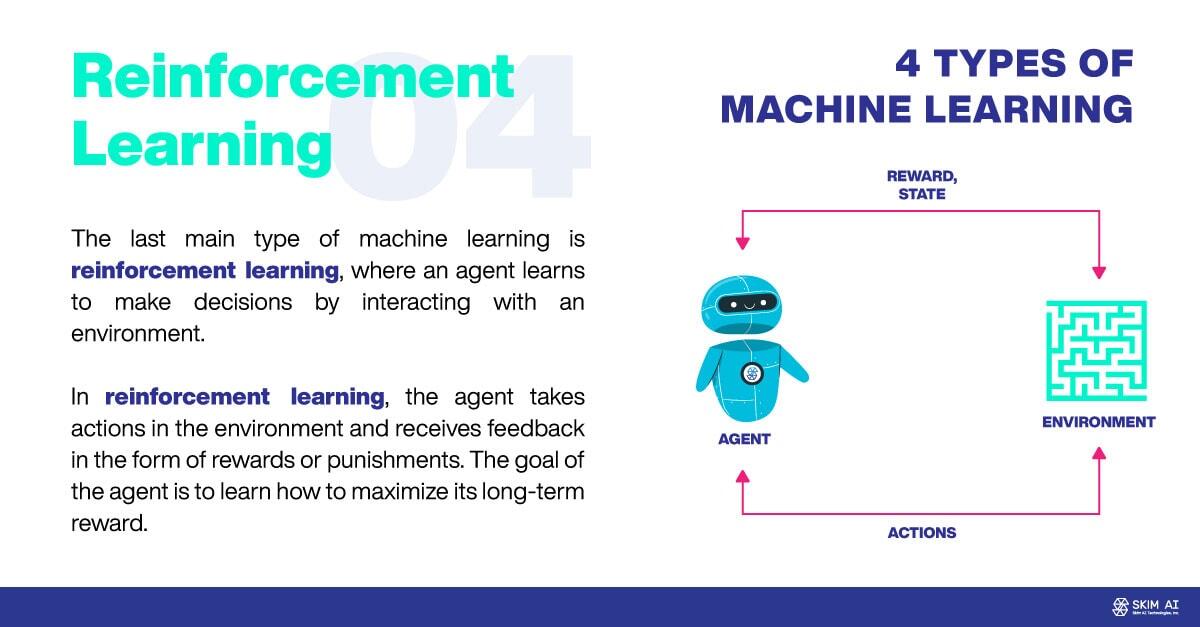
O último tipo principal de aprendizagem automática é a aprendizagem por reforço, em que um agente aprende a tomar decisões através da interação com um ambiente. Na aprendizagem por reforço, o agente realiza acções no ambiente e recebe feedback sob a forma de recompensas ou castigos. O objetivo do agente é aprender a maximizar a sua recompensa a longo prazo.
As maiores aplicações da aprendizagem por reforço são no domínio da robótica, em que um agente pode aprender a controlar um robô físico para realizar uma tarefa. O agente executa acções no ambiente, como mover os braços ou as pernas do robô, e recebe feedback sob a forma de uma recompensa ou de uma penalização com base na sua capacidade de executar a tarefa.
A aprendizagem por reforço também pode ser utilizada para jogos e simulações, em que um agente pode aprender a jogar um jogo ou a navegar num ambiente virtual. Por exemplo, a aprendizagem por reforço tem sido utilizada para treinar agentes para jogar videojogos como os jogos Atari e o jogo Go.
Outra área em que a aprendizagem por reforço se tem revelado promissora é a dos cuidados de saúde, onde pode ser utilizada para otimizar tratamentos para várias doenças. O agente pode aprender a tomar decisões de tratamento com base nos dados do doente e receber feedback sob a forma de resultados do doente.
Indústrias transformadoras
A aprendizagem automática é um domínio em rápida evolução que tem o potencial de transformar quase todos os sectores e resolver alguns dos nossos problemas mais complexos. Compreender os diferentes tipos de aprendizagem automática, como a aprendizagem supervisionada, não-supervisionada, semi-supervisionada e por reforço, permite-nos continuar a alargar os limites e a ter impacto no nosso mundo baseado em dados.


