
Diversi tipi di apprendimento automatico



Diversi tipi di apprendimento automatico
L'apprendimento automatico è un campo in rapida evoluzione che ha il potenziale di trasformare molti settori, dalla sanità alla finanza alla produzione. Al centro dell'apprendimento automatico ci sono quattro tipi principali di tecniche di apprendimento: apprendimento supervisionato, apprendimento non supervisionato, apprendimento semi-supervisionato, e apprendimento per rinforzo.
Ognuno di questi approcci ha i suoi punti di forza e di debolezza e la comprensione del loro funzionamento è fondamentale per il successo dell'implementazione di soluzioni di intelligenza artificiale (AI).
*Prima di immergersi in questo blog sull'apprendimento automatico, assicuratevi di dare un'occhiata al nostro articolo su AI vs. ML per imparare la differenza tra i due.
Apprendimento supervisionato

L'apprendimento supervisionato è un tipo di apprendimento automatico in cui l'algoritmo viene addestrato su un set di dati etichettati. Ciò significa che i dati di ingresso sono già stati classificati o etichettati dall'uomo e l'algoritmo impara a fare previsioni sulla base di questi dati etichettati. Nell'apprendimento supervisionato, l'algoritmo riceve sia i dati di ingresso che i corrispondenti dati di uscita e utilizza queste informazioni per imparare una funzione di mappatura tra i due.
Una delle applicazioni più comuni dell'apprendimento supervisionato è la classificazione. Nella classificazione, l'algoritmo viene addestrato a prevedere a quale categoria appartiene un dato in ingresso. Ad esempio, un algoritmo di apprendimento supervisionato potrebbe essere addestrato su un set di immagini di cani e gatti, con ogni immagine etichettata come "gatto" o "cane". Una volta addestrato, l'algoritmo può prendere in considerazione una nuova immagine e prevedere se si tratta di un gatto o di un cane.
Un'altra applicazione comune dell'apprendimento supervisionato è la regressione. Nella regressione, l'algoritmo viene addestrato a prevedere un risultato numerico continuo in base ai dati di ingresso. Ad esempio, un algoritmo di apprendimento supervisionato potrebbe essere addestrato su un set di dati relativi ai prezzi delle case, con ogni punto dati che include informazioni come la dimensione della casa, il numero di camere da letto e la posizione. L'algoritmo imparerebbe quindi a prevedere il prezzo di una nuova casa sulla base di queste caratteristiche.
Apprendimento non supervisionato

L'apprendimento non supervisionato è un altro tipo comune di apprendimento automatico in cui, a differenza dell'apprendimento supervisionato, l'algoritmo viene addestrato su un set di dati non etichettati. Nell'apprendimento non supervisionato, all'algoritmo non viene fornita alcuna informazione sull'output o sulle etichette dei dati in ingresso. Al contrario, impara a identificare schemi e strutture nei dati in modo autonomo.
Una delle applicazioni più comuni dell'apprendimento non supervisionato è il clustering. Gli algoritmi di clustering raggruppano punti di dati simili in base alle loro caratteristiche, senza alcuna conoscenza preliminare delle etichette dei dati. Questo può essere utile per attività come la segmentazione dei clienti, dove un'azienda può voler raggruppare i clienti in base alle loro abitudini di acquisto o ad altri comportamenti.
Un'altra applicazione dell'apprendimento non supervisionato è la riduzione della dimensionalità. Gli algoritmi di riduzione della dimensionalità sono utilizzati per ridurre il numero di caratteristiche in un set di dati, preservando il più possibile le informazioni originali. Questo può essere utile per compiti come il riconoscimento delle immagini e del parlato, dove i dati in ingresso possono essere altamente dimensionali e difficili da elaborare.
Apprendimento semi-supervisionato

Quando si parla di apprendimento semi-supervisionato, si tratta di una combinazione di tecniche di apprendimento supervisionate e non supervisionate. L'algoritmo viene addestrato su un set di dati che contiene sia dati etichettati che non etichettati.
I dati etichettati vengono utilizzati per addestrare l'algoritmo in modo supervisionato, mentre i dati non etichettati vengono utilizzati per aiutare l'algoritmo a conoscere meglio la struttura sottostante dei dati. L'idea alla base dell'apprendimento semi-supervisionato è che i dati non etichettati possano essere utilizzati per migliorare l'accuratezza e la capacità di generalizzazione dell'algoritmo.
L'apprendimento semi-supervisionato è spesso utilizzato nell'elaborazione del linguaggio naturale (NLP), un campo dell'informatica e dell'IA che si concentra sulla capacità delle macchine di comprendere il linguaggio scritto e parlato in modo simile a quello umano. I modelli linguistici sono in genere addestrati su grandi quantità di dati testuali non etichettati, che possono essere utilizzati per migliorare l'accuratezza di compiti quali la classificazione dei testi e la traduzione linguistica.
L'apprendimento semi-supervisionato può essere utilizzato anche per compiti come il riconoscimento delle immagini e del parlato, dove la quantità di dati etichettati può essere limitata o costosa da ottenere. Sfruttando i dati non etichettati disponibili, l'algoritmo può migliorare le sue prestazioni nel compito da svolgere.
Apprendimento per rinforzo
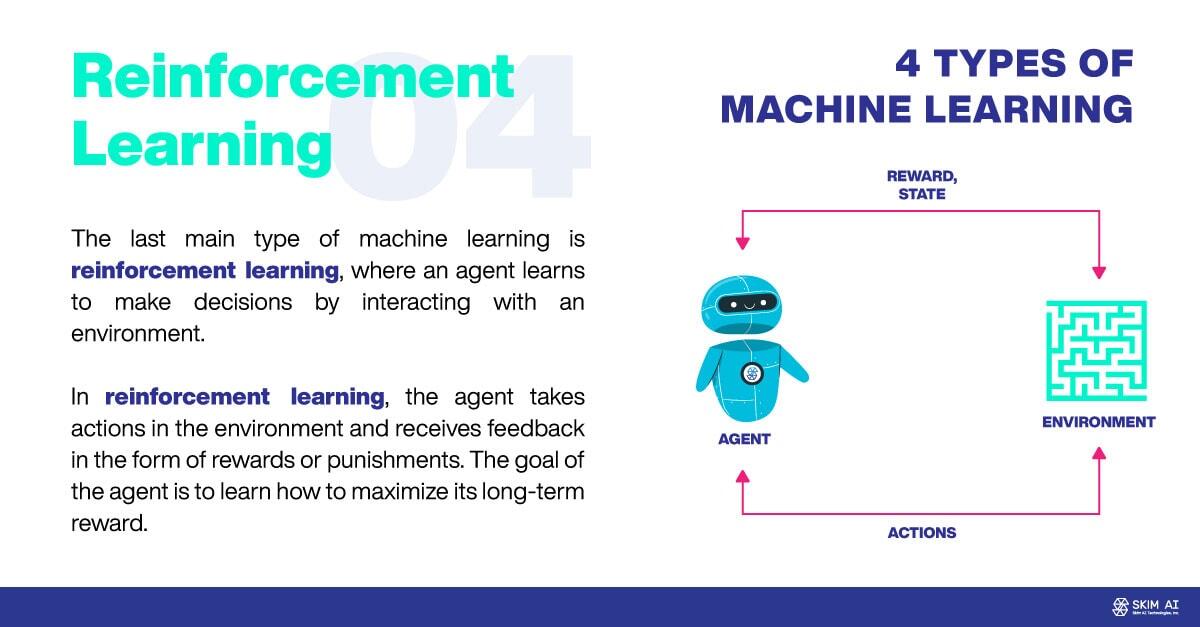
L'ultimo tipo di apprendimento automatico è l'apprendimento per rinforzo, in cui un agente impara a prendere decisioni interagendo con l'ambiente. Nell'apprendimento per rinforzo, l'agente compie azioni nell'ambiente e riceve un feedback sotto forma di premi o punizioni. L'obiettivo dell'agente è imparare a massimizzare la sua ricompensa a lungo termine.
Le maggiori applicazioni dell'apprendimento per rinforzo sono nel campo della robotica, dove un agente può imparare a controllare un robot fisico per eseguire un compito. L'agente compie azioni nell'ambiente, come muovere le braccia o le gambe del robot, e riceve un feedback sotto forma di ricompensa o penalità in base al grado di esecuzione del compito.
L'apprendimento per rinforzo può essere utilizzato anche per giochi e simulazioni, dove un agente può imparare a giocare a un gioco o a navigare in un ambiente virtuale. Ad esempio, l'apprendimento per rinforzo è stato utilizzato per addestrare gli agenti a giocare a videogiochi come i giochi Atari e il gioco del Go.
Un'altra area in cui l'apprendimento per rinforzo si è dimostrato promettente è quella della sanità, dove può essere utilizzato per ottimizzare i trattamenti di varie malattie. L'agente può imparare a prendere decisioni terapeutiche basate sui dati dei pazienti e ricevere un feedback sotto forma di risultati.
Trasformare le industrie
L'apprendimento automatico è un campo in rapida evoluzione che ha il potenziale per trasformare quasi tutti i settori e risolvere alcuni dei nostri problemi più complessi. La comprensione dei diversi tipi di apprendimento automatico, come l'apprendimento supervisionato, non supervisionato, semi-supervisionato e l'apprendimento per rinforzo, ci permette di continuare a superare i limiti e di avere un impatto sul nostro mondo guidato dai dati.


