
Що таке глибоке навчання?



Що таке глибинне навчання?
Глибоке навчання (ГН) - це підмножина машинного навчання (МН), яка в першу чергу фокусується на імітації здатності людського мозку навчатися та обробляти інформацію. У світі штучного інтелекту (ШІ), що стрімко розвивається, глибоке навчання стало революційною технологією, яка впливає практично на всі сфери - від охорони здоров'я до автономних систем.
Щоб досягти такої здатності до навчання та обробки інформації, глибоке навчання спирається на складну мережу взаємопов'язаних нейронів, які називаються штучними нейронними мережами (ШНМ). Використовуючи потужність ШНМ та їхню здатність автоматично адаптуватися і вдосконалюватися з часом, алгоритми глибокого навчання можуть виявляти складні закономірності, витягувати значущі ідеї та робити прогнози з надзвичайною точністю.
*Перш ніж читати цей блог про глибоке навчання, обов'язково ознайомтеся з нашим поясненням AI vs ML.
Складові елементи глибокого навчання
В основі глибокого навчання лежить концепція ШНМ, натхненна структурою і функціями людського мозку. ШНМ складаються з різних шарів взаємопов'язаних вузлів або нейронів, кожен з яких обробляє інформацію і передає її на наступний шар. Ці шари можуть навчатися та адаптуватися, регулюючи вагу зв'язків між нейронами.
ШНМ складається зі штучних нейронів, кожен з яких отримує вхідні дані від іншого перед тим, як обробити інформацію та надіслати вихідні дані підключеним нейронам. Сила цих зв'язків між нейронами називається вагами, і ці ваги визначають важливість кожного входу в загальних обчисленнях.
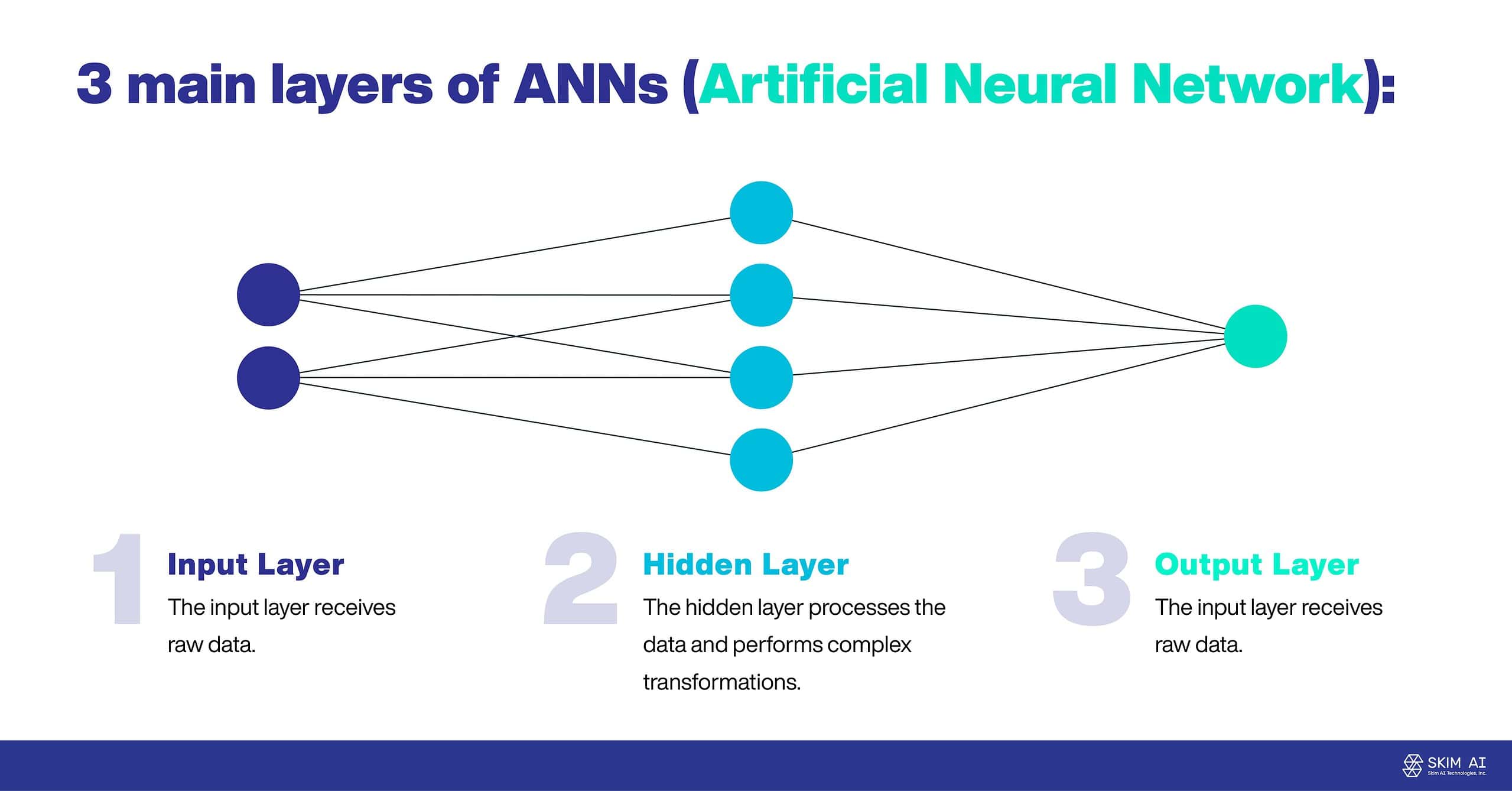
ANN часто складаються з трьох основних шарів:
Вхідний шар: Вхідний шар отримує необроблені дані.
Прихований шар: Прихований шар обробляє дані та виконує складні перетворення.
Вихідний шар: Вихідний шар створює кінцевий результат.
Ще одним важливим структурним елементом ШНМ є функції активації, які визначають вихід кожного нейрона на основі отриманих вхідних даних. Ці функції вносять нелінійність у мережу, дозволяючи їй вивчати складні закономірності та виконувати складні обчислення.
Глибоке навчання - це процес навчання, під час якого мережа налаштовує свої ваги, щоб мінімізувати похибку між своїми прогнозами та результатами. Цей процес навчання часто передбачає використання функції втрат, яка кількісно вимірює різницю між виходом мережі та істинними значеннями.
Різні типи навчальних архітектур
Незважаючи на все вищесказане, глибоке навчання не слідує одній навчальній архітектурі. Існує кілька основних типів архітектур, які використовуються для вирішення широкого кола завдань. Два з найпоширеніших - це згорткові нейронні мережі (CNN) та рекурентні нейронні мережі (RNN). Однак є й інші, такі як LSTM, GRU та автокодери.
Згорткові нейронні мережі (CNN)
ШНМ відіграють ключову роль у задачах комп'ютерного зору та розпізнавання зображень. До появи ШНМ ці задачі вимагали трудомістких і тривалих методів вилучення ознак для ідентифікації об'єктів на зображеннях. У контексті розпізнавання зображень основна функція ШНМ полягає в перетворенні зображень у більш керовану форму зі збереженням важливих ознак для точних прогнозів.
CNN часто перевершують інші нейронні мережі завдяки своїй винятковій продуктивності при обробці зображень, аудіосигналів або мови.
Для виконання своїх завдань вони використовують три основні типи шарів:
Шар згортки: Ідентифікує особливості в межах пікселів.
Шар об'єднання: Особливості рефератів для подальшого опрацювання.
Рівень повного з'єднання (FC): Використовує набуті ознаки для прогнозування.
Згортковий шар є найбільш фундаментальним компонентом ШНМ, де відбувається більшість обчислень. Цей шар складається з вхідних даних, фільтра та карти ознак. Згорткові шари виконують операцію згортки вхідних даних перед тим, як відправити результат до шару об'єднання.
У задачі розпізнавання зображень ця згортка конденсує всі пікселі в межах сприйнятливого поля в одне значення. Простіше кажучи, застосування згортки до зображення зменшує його розмір і об'єднує всю інформацію в межах поля в один піксель. Основні особливості, такі як горизонтальні та діагональні краї, виділяються в шарі згортки. Результат, який генерується шаром згортки, називається картою особливостей.
Основне призначення шару об'єднання - зменшити розмір карти об'єктів, тим самим зменшуючи обчислення і зв'язки між шарами.
Третім шаром у CNN є шар FC, який з'єднує нейрони між двома різними шарами. Часто перед вихідним шаром вхідні зображення з попередніх шарів згладжуються. Згладжене зображення зазвичай проходить через додаткові шари FC, де математичні функції ініціюють процес класифікації.
Рекурентні нейронні мережі (RNN)
Рекурентні нейронні мережі (RNN) є одними з найсучасніших розроблених алгоритмів, які використовуються в таких широко використовуваних технологіях, як Siri та голосовий пошук Google.
ШНМ - це перший алгоритм, здатний зберігати вхідні дані завдяки внутрішній пам'яті, що робить його цінним для задач машинного навчання, пов'язаних з послідовними даними, такими як мова, текст, фінансові дані, аудіо тощо. Унікальна архітектура RNN дозволяє їм ефективно фіксувати залежності та закономірності всередині послідовностей, що дає змогу робити точніші прогнози та покращувати загальну продуктивність у широкому спектрі застосувань.
Особливістю ШНМ є його здатність підтримувати прихований стан, який функціонує як внутрішня пам'ять, що дозволяє йому запам'ятовувати інформацію з попередніх часових кроків. Ця здатність пам'яті дозволяє ШНМ вивчати та використовувати довгострокові залежності у вхідній послідовності, що робить їх особливо ефективними для таких завдань, як аналіз часових рядів, НЛП та розпізнавання мови.
Структура ШНМ складається з серії взаємопов'язаних шарів, де кожен шар відповідає за обробку одного часового кроку вхідної послідовності. Вхідними даними для кожного часового кроку є комбінація поточної точки даних і прихованого стану з попереднього часового кроку. Потім ця інформація обробляється шаром RNN, який оновлює прихований стан і генерує вихід. Прихований стан діє як пам'ять, зберігаючи інформацію з попередніх часових кроків, щоб впливати на подальшу обробку.
Виклики глибокого навчання
Незважаючи на значні успіхи глибокого навчання, залишається кілька викликів і сфер для майбутніх досліджень, які потребують подальшого вивчення з метою розвитку галузі та забезпечення відповідального впровадження цих технологій.
Зрозумілість та пояснюваність
Одним з основних обмежень моделей глибокого навчання є їхній характер "чорної скриньки", що означає непрозорість і складність їхньої внутрішньої роботи. Це ускладнює розуміння та інтерпретацію практиками, користувачами та регуляторами причин, що лежать в основі їхніх прогнозів та рішень. Розвиваємо техніки для кращої інтерпретованості та пояснюваність має вирішальне значення для вирішення цих проблем, і це має кілька важливих наслідків.

Покращена інтерпретованість і пояснюваність допоможе користувачам і зацікавленим сторонам краще зрозуміти, як моделі глибокого навчання отримують свої прогнози або рішення, тим самим сприяючи підвищенню довіри до їх можливостей і надійності. Це особливо важливо в таких чутливих додатках, як охорона здоров'яфінанси та кримінальне правосуддя, де наслідки рішень штучного інтелекту можуть суттєво вплинути на життя людей.
Здатність інтерпретувати та пояснювати моделі глибокого навчання може також полегшити виявлення та пом'якшення потенційних упереджень, помилок або непередбачуваних наслідків. Надаючи уявлення про внутрішню роботу моделей, фахівці можуть приймати обґрунтовані рішення щодо вибору моделі, навчання та розгортання, щоб забезпечити відповідальне та етичне використання систем штучного інтелекту.
Розуміння внутрішніх процесів моделей глибокого навчання може допомогти фахівцям виявити проблеми або помилки, які можуть впливати на їхню продуктивність. Розуміючи фактори, які впливають на прогнози моделі, фахівці можуть точно налаштувати її архітектуру, навчальні дані або гіперпараметри, щоб підвищити загальну продуктивність і точність.
Вимоги до даних та обчислень для глибокого навчання
Глибинне навчання є неймовірно потужним, але з цією потужністю приходять значні вимоги до даних та обчислень. Ці вимоги іноді можуть створювати проблеми для впровадження глибокого навчання.

Однією з головних проблем глибокого навчання є потреба у великих обсягах маркованих навчальних даних. Моделі глибокого навчання часто потребують величезних обсягів даних для ефективного навчання та узагальнення. Це пов'язано з тим, що ці моделі призначені для автоматичного вилучення і вивчення особливостей з необроблених даних, і чим більше даних вони мають доступ, тим краще вони можуть виявляти і фіксувати складні закономірності і взаємозв'язки.
Однак збір і маркування таких величезних обсягів даних може бути тривалим, трудомістким і дорогим процесом. У деяких випадках маркованих даних може бути недостатньо або їх важко отримати, особливо у спеціалізованих галузях, таких як медична візуалізація або рідкісні мови. Щоб вирішити цю проблему, дослідники вивчали різні методи, такі як доповнення даних, навчання з перенесенням, а також неконтрольоване або напівконтрольоване навчання, які мають на меті покращити продуктивність моделі з обмеженою кількістю маркованих даних.
Моделі глибокого навчання також вимагають значних обчислювальних ресурсів для навчання та висновків. Ці моделі, як правило, включають велику кількість параметрів і шарів, які вимагають потужного обладнання та спеціалізованих процесорів, таких як GPU або TPU, для ефективного виконання необхідних обчислень.
Обчислювальні вимоги моделей глибокого навчання можуть бути непосильними для деяких додатків або організацій з обмеженими ресурсами, що призводить до збільшення часу навчання і збільшення витрат. Щоб пом'якшити ці проблеми, дослідники і практики досліджують методи оптимізації моделей глибокого навчання і зменшення розміру і складності моделі, зберігаючи при цьому її продуктивність, що в кінцевому підсумку призводить до скорочення часу навчання і зниження потреб у ресурсах.
Надійність і безпека
Моделі глибокого навчання продемонстрували виняткову продуктивність в різних додатках; однак вони залишаються вразливими до ворожі атаки. Ці атаки передбачають створення шкідливих вхідних зразків, навмисно розроблених для того, щоб обдурити модель і змусити її генерувати неправильні прогнози або результати. Усунення цих вразливостей і підвищення надійності та безпеки моделей глибинного навчання, захищених від прикладів противника та інших потенційних ризиків, є критично важливим завданням для спільноти ШІ-спеціалістів. Наслідки таких атак можуть бути далекосяжними, особливо в таких сферах, як автономні транспортні засоби, кібербезпека та охорона здоров'я, де цілісність і надійність систем ШІ мають першорядне значення.
Зловмисники використовують чутливість моделей глибокого навчання до невеликих, часто непомітних збурень у вхідних даних. Навіть незначні зміни у вихідних даних можуть призвести до кардинально відмінних прогнозів або класифікацій, незважаючи на те, що вхідні дані здаються практично ідентичними для людини-спостерігача. Це явище викликає занепокоєння щодо стабільності та надійності моделей глибокого навчання в реальних умовах, коли зловмисники можуть маніпулювати вхідними даними, щоб скомпрометувати продуктивність системи.
Застосування глибинного навчання
Глибоке навчання продемонструвало свій трансформаційний потенціал у широкому спектрі застосувань і галузей. Деякі з найбільш помітних застосувань включають
- Розпізнавання зображень і комп'ютерний зір: Глибоке навчання значно підвищило точність і ефективність розпізнавання зображень і завдань комп'ютерного зору. Зокрема, CNN досягли успіху в класифікації зображень, виявленні об'єктів і сегментації. Ці досягнення проклали шлях для таких додатків, як розпізнавання облич, автономні транспортні засоби та аналіз медичних зображень.
- NLP: Глибоке навчання зробило революцію в обробці природної мови, уможлививши розробку більш досконалих мовних моделей і додатків. Різні моделі використовуються для досягнення найсучасніших результатів у таких завданнях, як машинний переклад, аналіз настроїв, узагальнення тексту та системи відповідей на запитання.
- Розпізнавання та генерація мовлення: Глибоке навчання також досягло значних успіхів у розпізнаванні та генеруванні мовлення. Такі технології, як RNN і CNN, були використані для розробки більш точних і ефективних систем автоматичного розпізнавання мови (ASR), які перетворюють усну мову в письмовий текст. Моделі глибокого навчання також уможливили високоякісний синтез мовлення, генеруючи людську мову з тексту.
- Навчання з підкріпленням: Глибоке навчання в поєднанні з навчанням з підкріпленням призвело до розвитку навчання з глибоким підкріпленням (DRL) алгоритми. DRL використовується для навчання агентів, здатних засвоювати оптимальні стратегії для прийняття рішень і управління. Застосування DRL охоплює робототехніку, фінанси та ігри.
- Генеративні моделі: Генеративні моделі глибокого навчання, такі як Генеративні змагальні мережі (GAN)показали неабиякий потенціал для генерування реалістичних зразків даних. Ці моделі використовуються для таких завдань, як синтез зображень, передача стилю, доповнення даних і виявлення аномалій.
- Охорона здоров'я: Глибоке навчання також зробило значний внесок у сферу охорони здоров'я, революціонізувавши діагностику, пошук ліків та персоналізовану медицину. Наприклад, алгоритми глибокого навчання використовуються для аналізу медичних зображень з метою раннього виявлення захворювань, прогнозування результатів лікування та визначення потенційних кандидатів у ліки.
Революційні зміни в галузях та сферах застосування
Глибоке навчання стало революційною технологією з потенціалом революціонізувати широкий спектр галузей і застосувань. По суті, глибоке навчання використовує штучні нейронні мережі, щоб імітувати здатність людського мозку до навчання та обробки інформації. CNN і RNN - це дві видатні архітектури, які уможливили значний прогрес у таких галузях, як розпізнавання зображень, НЛП, розпізнавання мови та охорона здоров'я.
Глибоке навчання все ще стикається з проблемами, які необхідно вирішити, щоб забезпечити його відповідальне та етичне розгортання. Ці виклики включають покращення інтерпретованості та пояснюваності моделей глибокого навчання, вирішення питань, пов'язаних з даними та обчислювальними вимогами, а також підвищення надійності та захищеності цих моделей від атак зловмисників.
Оскільки дослідники і практики продовжують досліджувати і розробляти інноваційні методи для вирішення цих проблем, сфера глибокого навчання, безсумнівно, буде продовжувати розвиватися, створюючи нові можливості і додатки, які змінять те, як ми живемо, працюємо і взаємодіємо з навколишнім світом. Завдяки своєму величезному потенціалу, глибоке навчання відіграватиме все більш важливу роль у формуванні майбутнього штучного інтелекту і стимулюванні технологічного прогресу в різних сферах


