
ディープラーニングとは何か?



ディープラーニングとは何か?
ディープラーニング(DL)は機械学習(ML)のサブセットで、主に人間の脳の学習能力と情報処理能力を模倣することに焦点を当てている。急速に進化する人工知能(AI)の世界で、ディープラーニングはヘルスケアから自律システムに至るまで、事実上あらゆる分野に影響を与える画期的な技術として登場した。
情報を学習し処理するこの能力を実現するために、ディープラーニングは人工ニューラルネットワーク(ANN)と呼ばれる、相互に接続されたニューロンの複雑な網に依存している。ANNのパワーと、時間とともに自動的に適応し改善する能力を活用することで、ディープラーニング・アルゴリズムは複雑なパターンを発見し、意味のある洞察を抽出し、驚くべき精度で予測を行うことができる。
*ディープラーニングに関するこのブログを読む前に、AIとMLについての説明を必ずチェックしてほしい。
ディープラーニングのビルディングブロック
ディープラーニングの基礎は、人間の脳の構造と機能にヒントを得たANNの概念に基づいて構築されている。ANNは、相互に接続されたノードまたはニューロンからなる様々な層で構成され、各ニューロンが情報を処理し、次の層に渡す。これらの層は、ニューロン間の接続の重みを調整することで学習し、適応することができる。
ANNの中には人工的なニューロンがあり、それぞれが別のニューロンから入力を受けてから情報を処理し、接続されたニューロンに出力を送る。ニューロン間の接続の強さは重みとして知られ、この重みが全体の計算における各入力の重要性を決定する。
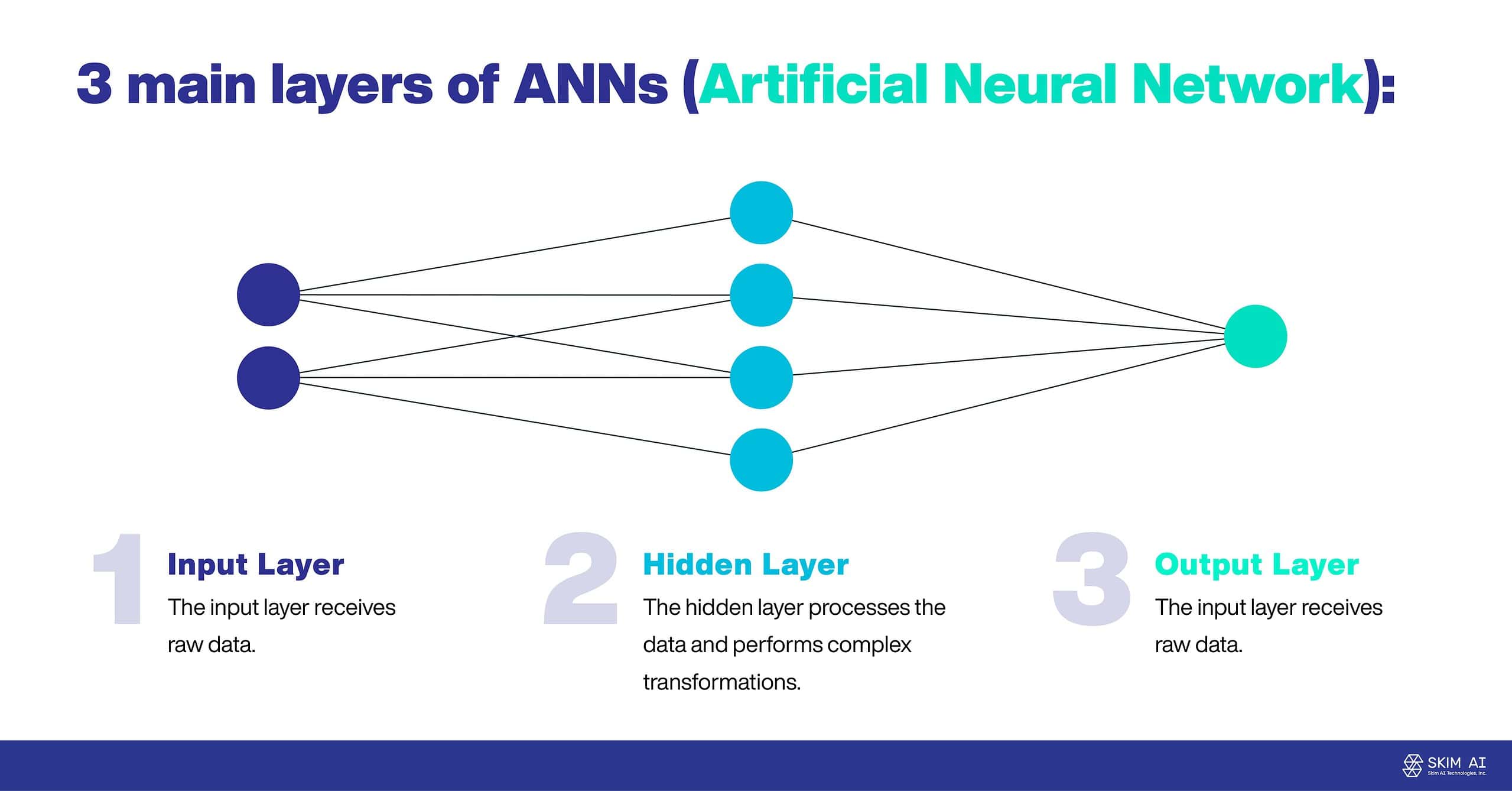
ANNは主に3つの層で構成されることが多い:
入力層:入力層は生データを受け取る。
隠れ層:隠れ層はデータを処理し、複雑な変換を行う。
出力レイヤー:出力層は最終結果を生成する。
ANNのもう一つの重要な構成要素は活性化関数で、これは受け取った入力に基づいて各ニューロンの出力を決定する。これらの関数はネットワークに非線形性を導入し、複雑なパターンを学習して複雑な計算を実行することを可能にする。
ディープラーニングは、予測値と結果の誤差を最小化するためにネットワークが重みを調整する、学習プロセスがすべてである。この学習プロセスでは、ネットワークの出力と真の値との差を定量化する損失関数を使用することが多い。
学習アーキテクチャの種類
とはいえ、ディープラーニングは1つの学習アーキテクチャに従うわけではない。幅広い問題に使われるアーキテクチャには、主にいくつかの種類がある。最も一般的なものは、畳み込みニューラルネットワーク(CNN)とリカレント・ニューラル・ネットワーク(RNN)の2つだ。しかし、以下のようなものもある。 LSTM、GRU、オートエンコーダ.
畳み込みニューラルネットワーク(CNN)
CNNはコンピュータビジョンや画像認識タスクにおいて極めて重要な役割を果たしている。CNNの登場以前は、これらのタスクは画像中のオブジェクトを識別するために、手間と時間のかかる特徴抽出技術を必要としていた。画像認識の文脈では、CNNの主な機能は、正確な予測のために不可欠な特徴を保持しながら、画像をより扱いやすい形に変換することである。
CNNは、画像、音声信号、音声の入力に対して卓越した性能を発揮するため、しばしば他のニューラルネットワークを凌駕する。
そのタスクを達成するために、主に3種類のレイヤーを採用している:
畳み込み層:ピクセル内の特徴を識別します。
プーリング層:更なる処理のために特徴を要約する。
FCレイヤー:取得した特徴量を予測に利用する。
畳み込み層はCNNの最も基本的な構成要素で、計算の大部分がここで行われる。この層は入力データ、フィルター、特徴マップから構成される。畳み込み層は、結果をプーリング層に送る前に、入力に対して畳み込み演算を行う。
画像認識タスクでは、この畳み込みは、その受容野内のすべてのピクセルを単一の値に凝縮する。より簡単に言えば、画像に畳み込みを適用することで、そのサイズを縮小し、フィールド内のすべての情報を1つのピクセルにまとめる。水平エッジや斜めエッジなどの基本的な特徴は、畳み込み層で抽出される。畳み込み層によって生成された出力は、特徴マップと呼ばれる。
プーリングレイヤーの主な目的は、特徴マップのサイズを小さくすることで、レイヤー間の計算と接続を減らすことである。
CNNの第3層はFC層で、2つの異なる層間のニューロンを接続する。出力層の前に位置することが多く、前の層からの入力画像は平坦化される。平坦化された画像は通常、さらにFC層を通過し、そこで数学関数が分類プロセスを開始する。
リカレント・ニューラル・ネットワーク(RNN)
リカレント・ニューラル・ネットワーク(RNN)は、開発された最先端のアルゴリズムのひとつであり、SiriやGoogleの音声検索など、広く使われているテクノロジーに採用されている。
RNNは、内部メモリによって入力を保持できる最初のアルゴリズムであり、音声、テキスト、金融データ、オーディオなどのシーケンシャルなデータを含む機械学習問題で重宝される。RNNのユニークなアーキテクチャは、シーケンス内の依存関係やパターンを効果的に捉えることを可能にし、幅広いアプリケーションにおいて、より正確な予測や全体的なパフォーマンスの向上を可能にする。
RNNの特徴は、内部メモリとして機能する隠れ状態を維持する能力であり、以前の時間ステップの情報を記憶することができる。この記憶能力により、RNNは入力シーケンス内の長距離依存関係を学習して利用することができ、時系列分析、NLP、音声認識などのタスクに特に効果的である。
RNNの構造は、相互に接続された一連の層で構成され、各層は入力シーケンスの1つの時間ステップの処理を担当する。各時間ステップの入力は、現在のデータポイントと前の時間ステップからの隠れ状態の組み合わせである。この情報はRNN層によって処理され、隠れ状態が更新され、出力が生成される。隠れ状態はメモリとして機能し、以前の時間ステップからの情報を保持し、将来の処理に影響を与える。
ディープラーニングの課題
ディープラーニングの目覚ましい成功にもかかわらず、この分野を発展させ、これらの技術の責任ある展開を確保するために、さらなる探求が必要ないくつかの課題と将来の研究分野が残っている。
解釈可能性と説明可能性
ディープラーニング・モデルの大きな限界の一つは、そのブラックボックス的な性質である。そのため、実務家、ユーザー、規制当局は、予測や決定の背後にある理由を理解し、解釈することが難しくなる。 技術開発 より良い解釈可能性と 説明可能性 このような懸念に対処する上で重要なことであり、いくつかの重要な意味を持つ。

解釈可能性と説明可能性の強化は、ユーザーや利害関係者がディープラーニングモデルがどのように予測や決定に至るかをよりよく理解するのに役立ち、それによってその能力と信頼性に対する信頼を醸成する。これは、以下のような繊細なアプリケーションにおいて特に重要である。 ヘルスケア金融、刑事司法など、AIの決定が個人の生活に大きな影響を与える可能性がある分野だ。
ディープラーニングモデルを解釈し説明する能力は、潜在的なバイアス、エラー、または意図しない結果の特定と軽減を促進することもできる。モデルの内部構造に関する洞察を提供することで、実務者はモデルの選択、トレーニング、配備について十分な情報に基づいた意思決定を行うことができ、AIシステムが責任と倫理を持って使用されることを保証することができる。
ディープ・ラーニング・モデルの内部プロセスに関する洞察を得ることは、実務家がそのパフォーマンスに影響を与える可能性のある問題やエラーを特定するのに役立ちます。モデルの予測に影響を与える要因を理解することで、実務者はアーキテクチャ、トレーニングデータ、またはハイパーパラメータを微調整し、全体的なパフォーマンスと精度を向上させることができます。
ディープラーニングに必要なデータと計算能力
ディープラーニングは信じられないほど強力だが、この強力さには多大なデータと計算要件が伴う。このような要件は、ディープラーニングの実装に時として困難をもたらすことがある。

ディープラーニングにおける主な課題の1つは、大量のラベル付き学習データが必要なことだ。ディープラーニング・モデルが効果的に学習し汎化するためには、しばしば膨大な量のデータが必要となる。これは、これらのモデルが生データから自動的に特徴を抽出し、学習するように設計されているためであり、より多くのデータにアクセスできればできるほど、複雑なパターンと関係を特定し、捉えることができるようになる。
しかし、このような膨大な量のデータの取得とラベル付けには、時間と労力がかかり、コストもかかる。特に医療画像や希少言語のような特殊な領域では、ラベル付けされたデータが不足していたり、入手が困難な場合もある。この課題に対処するため、研究者は、限られたラベル付きデータでモデルの性能を向上させることを目的とした、データ増強、転移学習、教師なし学習や半教師あり学習など、様々な手法を模索してきた。
ディープラーニングモデルは、学習と推論に多大な計算リソースも必要とする。これらのモデルには通常、多数のパラメータとレイヤーが含まれるため、必要な計算を効率的に実行するには、GPUやTPUのような強力なハードウェアと特殊な処理ユニットが必要になる。
ディープラーニングモデルの計算需要は、リソースが限られているアプリケーションや組織によっては法外なものとなる可能性があり、トレーニング時間の長期化とコストの上昇を招く。このような課題を軽減するため、研究者や実務家は、ディープラーニングモデルを最適化し、性能を維持しながらモデルのサイズと複雑さを低減する方法を研究してきました。
堅牢性とセキュリティ
ディープラーニング・モデルは、さまざまなアプリケーションで卓越した性能を発揮しているが、次のような影響を受けやすい。 敵対的攻撃.これらの攻撃は、意図的に悪意のある入力サンプルを作成し、モデルが不正な予測や出力を生成するように欺くことを必要とする。このような脆弱性に対処し、敵対的な例やその他の潜在的なリスクに対する深層学習モデルの堅牢性と安全性を強化することは、AIコミュニティにとって重要な課題である。特に、自律走行車、サイバーセキュリティ、ヘルスケアなど、AIシステムの完全性と信頼性が最も重要な領域では、このような攻撃の影響は広範囲に及ぶ可能性があります。
敵対的な攻撃は、ディープラーニング・モデルが入力データの小さな、しばしば知覚できない摂動に敏感であることを悪用する。元のデータに対するわずかな変更でさえ、人間の観察者には事実上同じ入力に見えるにもかかわらず、劇的に異なる予測や分類につながる可能性がある。この現象は、敵が入力データを操作してシステムの性能を危険にさらす可能性がある実世界のシナリオにおいて、ディープラーニングモデルの安定性と信頼性に懸念を抱かせる。
ディープラーニングの応用
ディープラーニングは、幅広いアプリケーションや産業において、その変革の可能性を示してきた。最も注目すべきアプリケーションには、以下のようなものがある:
- 画像認識とコンピュータビジョンディープラーニングは、画像認識とコンピュータ・ビジョンのタスクの精度と効率を劇的に向上させた。特にCNNは画像分類、物体検出、セグメンテーションに優れている。このような進歩により、顔認識、自律走行車、医療画像解析などのアプリケーションへの道が開かれた。
- 自然言語処理:ディープラーニングは自然言語処理に革命をもたらし、より洗練された言語モデルとアプリケーションの開発を可能にした。様々なモデルが採用され、機械翻訳、感情分析、テキスト要約、質問応答システムなどのタスクで最先端の結果を達成している。
- 音声認識と生成:ディープラーニングは音声認識・生成においても大きな進歩を遂げている。RNNやCNNのような技術は、話し言葉を文字に変換する、より正確で効率的な自動音声認識(ASR)システムの開発に使用されている。ディープラーニング・モデルはまた、テキストから人間のような音声を生成する高品質の音声合成も可能にしている。
- 強化学習:ディープラーニングを強化学習と組み合わせることで、次のようなものが開発された。 深層強化学習(DRL) アルゴリズムを学習します。DRLは意思決定や制御のための最適なポリシーを学習するエージェントのトレーニングに採用されています。DRLの応用分野はロボット工学、金融、ゲームなど多岐にわたります。
- 生成モデル:以下のような生成ディープラーニングモデル 生成的逆数ネットワーク (GANs)は、現実的なデータサンプルを生成するための顕著な可能性を示している。これらのモデルは、画像合成、スタイル転送、データ補強、異常検出などのタスクに利用されている。
- ヘルスケアディープラーニングはヘルスケアにも大きく貢献しており、診断、創薬、個別化医療に革命をもたらしている。例えば、ディープラーニング・アルゴリズムは、病気の早期発見のための医療画像の解析、患者の転帰予測、潜在的な薬剤候補の特定などに使われている。
産業とアプリケーションに革命を起こす
ディープラーニングは、さまざまな産業やアプリケーションに革命をもたらす可能性を秘めた画期的な技術として登場した。その中核となるディープラーニングは、人間の脳の学習能力と情報処理能力を模倣するために人工ニューラルネットワークを活用する。CNNとRNNは、画像認識、NLP、音声認識、ヘルスケアなどの分野で大きな進歩を可能にした2つの著名なアーキテクチャである。
ディープラーニングは、その責任ある倫理的な展開を保証するために対処すべき課題に依然として直面している。これらの課題には、深層学習モデルの解釈可能性と説明可能性の向上、データと計算機要件への対応、敵対的攻撃に対するモデルの堅牢性とセキュリティの強化などが含まれる。
研究者や実務家がこれらの課題に取り組むための革新的なテクニックを探求し、開発し続けるにつれて、ディープラーニングの分野は間違いなく進歩し続け、私たちの生活、仕事、身の回りの世界との関わり方を一変させる新たな能力とアプリケーションをもたらすだろう。ディープラーニングは、その計り知れない可能性によって、人工知能の未来を形成し、様々な領域における技術進歩を推進する上で、ますます重要な役割を果たすことになるだろう。


