
Tutorial: Cómo preentrenar ELECTRA para español desde cero



Tutorial: Cómo preentrenar ELECTRA para español desde cero
Publicado originalmente por Chris Tran, investigador de aprendizaje automático de Skim AI.![]()
Introducción
Este artículo trata sobre cómo preentrenar ELECTRA, otro miembro de la familia de métodos de preentrenamiento Transformer, para el español con el fin de obtener resultados de vanguardia en pruebas de referencia de Procesamiento del Lenguaje Natural. Se trata de la tercera parte de una serie sobre el entrenamiento de modelos lingüísticos BERT personalizados en español para diversos casos de uso:
- Parte I: Cómo entrenar desde cero un modelo lingüístico RoBERTa para el español
- Parte II: Cómo entrenar un modelo de español SpanBERTa para el reconocimiento de entidades con nombre (NER)
1. Introducción
En ICLR 2020, ELECTRA: preentrenamiento de codificadores de texto como discriminadores y no como generadoresun nuevo método de aprendizaje autosupervisado de representaciones lingüísticas. ELECTRA es otro miembro de la familia de métodos de preentrenamiento Transformer, cuyos miembros anteriores, como BERT, GPT-2, RoBERTa, han logrado muchos resultados de vanguardia en pruebas comparativas de Procesamiento del Lenguaje Natural.
A diferencia de otros métodos de modelado del lenguaje enmascarado, ELECTRA es una tarea de preentrenamiento más eficiente desde el punto de vista de las muestras, denominada detección de tokens sustituidos. A pequeña escala, ELECTRA-small puede entrenarse en una sola GPU durante 4 días para superar a GPT (Radford et al., 2018) (entrenado utilizando 30 veces más capacidad de cálculo) en la prueba GLUE. A gran escala, ELECTRA-large supera a ALBERT (Lan et al., 2019) sobre GLUE y establece un nuevo estado de la técnica para SQuAD 2.0.

ELECTRA supera sistemáticamente a los métodos de preentrenamiento de modelos lingüísticos enmascarados.
{: .text-center}
2. Método
Métodos de preentrenamiento de modelos lingüísticos enmascarados como BERT (Devlin et al., 2019) corromper la entrada sustituyendo algunos tokens (normalmente 15% de la entrada) por [MÁSCARA] y luego entrenar un modelo para reconstruir las fichas originales.
En lugar de enmascarar, ELECTRA corrompe la entrada sustituyendo algunos tokens por muestras de las salidas de un modelo lingüístico con enmascaramiento reducido. A continuación, se entrena un modelo discriminante para predecir si cada token era un original o un sustituto. Tras el preentrenamiento, se desecha el generador y se afina el discriminador en tareas posteriores.
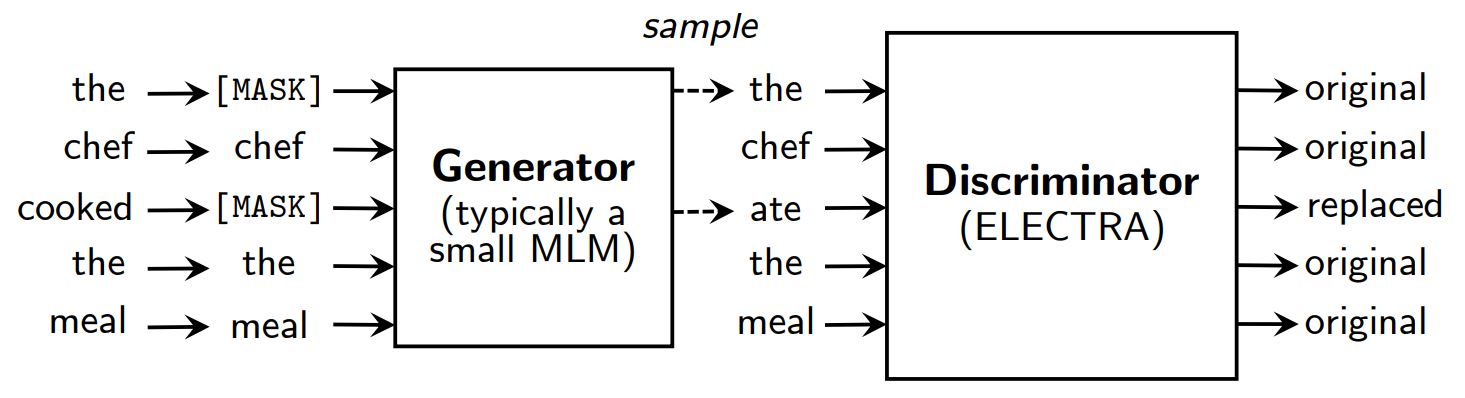
Una visión general de ELECTRA.
{: .text-center}
Aunque tiene un generador y un discriminador como GAN, ELECTRA no es adversario en el sentido de que el generador que produce tokens corruptos está entrenado con la máxima probabilidad en lugar de estar entrenado para engañar al discriminador.
¿Por qué es tan eficaz ELECTRA?
Con un nuevo objetivo de formación, ELECTRA puede alcanzar un rendimiento comparable al de modelos potentes como RoBERTa (Liu et al., (2019) que tiene más parámetros y necesita 4x más computación para el entrenamiento. En el artículo se realiza un análisis para comprender qué contribuye realmente a la eficacia de ELECTRA. Las principales conclusiones son las siguientes:
- ELECTRA se beneficia enormemente de tener una pérdida definida sobre todos los tokens de entrada en lugar de sólo sobre un subconjunto. Más concretamente, en ELECTRA, el discriminador predice sobre cada token de la entrada, mientras que en BERT, el generador sólo predice 15% tokens enmascarados de la entrada.
- El rendimiento de BERT se ve ligeramente perjudicado porque en la fase de preentrenamiento, el modelo ve
[MÁSCARA]mientras que no ocurre lo mismo en la fase de ajuste.
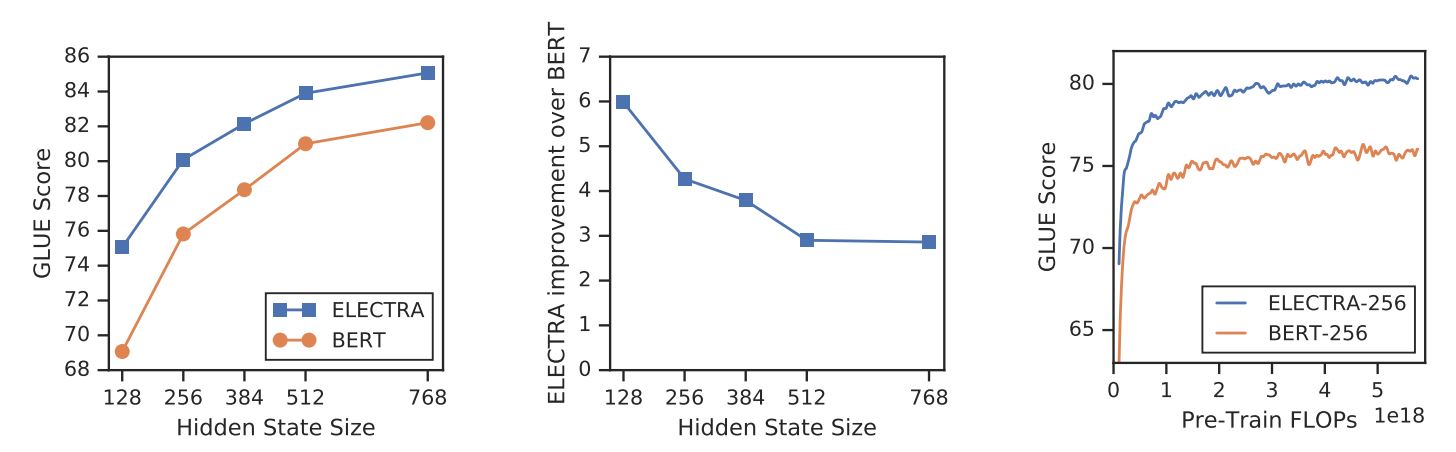
ELECTRA vs. BERT
{: .text-center}
3. Preentrenamiento ELECTRA
En esta sección, entrenaremos ELECTRA desde cero con TensorFlow utilizando scripts proporcionados por los autores de ELECTRA en google-research/electra. A continuación, convertiremos el modelo en el punto de control de PyTorch, que puede ajustarse fácilmente en tareas posteriores mediante la herramienta de Hugging Face transformadores biblioteca.
Configurar
!pip install tensorflow==1.15
!pip install transformers==2.8.0
!git clone https://github.com/google-research/electra.git
importar os
importar json
from transformadores import AutoTokenizer
Datos
Preentrenaremos a ELECTRA en un conjunto de datos de subtítulos de películas españolas recuperado de OpenSubtitles. Este conjunto de datos tiene un tamaño de 5,4 GB y lo entrenaremos en un pequeño subconjunto de ~30 MB para su presentación.
DATA_DIR = "./data" #@param {type: "cadena"}
TRAIN_SIZE = 1000000 #@param {type: "entero"}
MODEL_NAME = "electra-español" #@param {type: "string"}
# Descarga y descomprime el conjunto de datos de subtítulos de películas españolas
if not os.path.exists(DATA_DIR):
!mkdir -p $DATA_DIR
!wget "https://object.pouta.csc.fi/OPUS-OpenSubtitles/v2016/mono/es.txt.gz" -O $DATA_DIR/OpenSubtitles.txt.gz
!gzip -d $DATA_DIR/OpenSubtitles.txt.gz
!head -n $TRAIN_SIZE $DATA_DIR/OpenSubtitles.txt > $DATA_DIR/train_data.txt
!rm $DATA_DIR/OpenSubtitles.txt
Antes de construir el conjunto de datos de preentrenamiento, debemos asegurarnos de que el corpus tiene el siguiente formato:
- cada línea es una frase
- una línea en blanco separa dos documentos
Crear un conjunto de datos de preentrenamiento
Utilizaremos el tokenizador de bert-base-multilingüe-cased para procesar textos en español.
# Guarda el tokenizador WordPiece preentrenado para obtener vocab.txt
tokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
tokenizer.save_pretrained(DATA_DIR)
Utilizamos build_pretraining_dataset.py para crear un conjunto de datos de preentrenamiento a partir de un volcado de texto sin procesar.
python3 electra/build_pretraining_dataset.py
--corpus-dir $DATA_DIR \
--vocab-file $DATA_DIR/vocab.txt \
--output-dir $DATA_DIR/pretrain_tfrecords \
--max-seq-length 128 \
--blanks-separate-docs False \
--no-lower-case \
--num-processes 5
Iniciar la formación
Utilizamos run_pretraining.py para preentrenar un modelo ELECTRA.
Para entrenar un pequeño modelo ELECTRA para 1 millón de pasos, ejecute:
python3 run_pretraining.py --data-dir $DATA_DIR --model-name electra_small
Esto lleva algo más de 4 días en una GPU Tesla V100. Sin embargo, el modelo debería alcanzar resultados decentes tras 200.000 pasos (10 horas de entrenamiento en la GPU v100).
Para personalizar la formación, cree un .json que contiene los hiperparámetros. Consulte configure_pretraining.py para los valores por defecto de todos los hiperparámetros.
A continuación, establecemos los hiperparámetros para entrenar el modelo durante sólo 100 pasos.
hparams = {
"do_train": "true",
"do_eval": "false",
"model_size": "small",
"do_lower_case": "false",
"vocab_size": 119547,
"num_train_steps": 100,
"save_checkpoints_steps": 100,
"train_batch_size": 32,
}
con open("hparams.json", "w") como f:
json.dump(hparams, f)
Empecemos a entrenar:
python3 electra/run_pretraining.py
--data-dir $DATA_DIR \
--nombre-del-modelo $MODEL_NAME \
--hparams "hparams.json"
Si está entrenando en una máquina virtual, ejecute las siguientes líneas en el terminal para monitorizar el proceso de entrenamiento con TensorBoard.
pip install -U tensorboard
tensorboard dev upload --logdir data/models/electra-spanish
Esta es la TensorBoard de entrenamiento de ELECTRA-small para 1 millón de pasos en 4 días en una GPU V100.
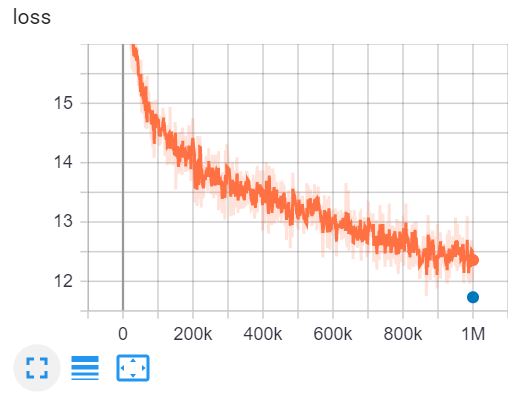 {: .align-center}
{: .align-center}
4. Convertir los puntos de control de Tensorflow al formato PyTorch.
Cara de abrazo tiene una herramienta para convertir los puntos de control de Tensorflow a PyTorch. Sin embargo, esta herramienta aún no ha sido actualizada para ELECTRA. Afortunadamente, he encontrado un repositorio en GitHub de @lonePatient que puede ayudarnos con esta tarea.
!git clone https://github.com/lonePatient/electra_pytorch.git
MODEL_DIR = "data/models/electra-español/"
config = {
"vocab_size" 119547,
"embedding_size": 128,
"hidden_size": 256,
"num_hidden_layers": 12,
"num_attention_heads": 4,
"tamaño_intermedio": 1024,
"generator_size":"0.25",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"attention_probs_dropout_prob": 0.1,
"max_position_embeddings": 512,
"type_vocab_size": 2,
"initializer_range": 0.02
}
con open(ARCHIVO_MODELO + "config.json", "w") como f:
json.dump(config, f)
python electra_pytorch/convert_electra_tf_checkpoint_to_pytorch.py
--tf_checkpoint_path=$MODEL_DIR \
--electra_config_file=$MODEL_DIR/config.json \
--pytorch_dump_path=$MODEL_DIR/pytorch_model.bin
Utilice ELECTRA con transformadores
Después de convertir el punto de control del modelo al formato PyTorch, podemos empezar a utilizar nuestro modelo ELECTRA preentrenado en tareas posteriores con la función transformadores biblioteca.
importar antorcha
from transformers import ElectraForPreTraining, ElectraTokenizerFast
discriminador = ElectraForPreTraining.from_pretrained(ARCHIVO_DE_ MODELOS)
tokenizer = ElectraTokenizerFast.from_pretrained(DATA_DIR, do_lower_case=False)
sentence = "Los pájaros están cantando" # Los pájaros están cantando
fake_sentence = "Los pájaros están hablando" # Los pájaros están hablando
fake_tokens = tokenizer.tokenize(fake_sentence, add_special_tokens=True)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
discriminator_outputs = discriminator(fake_inputs)
predicciones = discriminador_salidas[0] > 0
[print("%7s" % token, end="") for token in fake_tokens]
print("\n")
[print("%7s" % int(predicción), end="") for predicción in predicciones.tolist()];
[CLS] Los paj ##aros estan habla ##ndo [SEP]
1 0 0 0 0 0 0 0
Nuestro modelo fue entrenado para sólo 100 pasos, por lo que las predicciones no son exactas. El modelo ELECTRA-small completamente entrenado para español puede cargarse como se indica a continuación:
discriminador = ElectraForPreTraining.from_pretrained("skimai/electra-pequeño-español")
tokenizador = ElectraTokenizerFast.from_pretrained("skimai/electra-español-pequeño", do_lower_case=False)
5. Conclusión
En este artículo, hemos recorrido el documento de ELECTRA para entender por qué ELECTRA es el enfoque de preentrenamiento de transformadores más eficiente del momento. A pequeña escala, ELECTRA-small puede entrenarse en una GPU durante 4 días para superar a GPT en la prueba GLUE. A gran escala, ELECTRA-large establece un nuevo estado del arte para SQuAD 2.0.
A continuación, entrenamos realmente un modelo ELECTRA sobre textos en español y convertimos el punto de control de Tensorflow a PyTorch y utilizamos el modelo con la aplicación transformadores biblioteca.
Referencias
- [1] ELECTRA: preentrenamiento de codificadores de texto como discriminadores y no como generadores
- [2] google-research/electra - el repositorio oficial GitHub del documento original
- [3] electra_pytorch - una implementación de ELECTRA en PyTorch


