
Anleitung: Wie man ELECTRA von Grund auf für Spanisch trainiert
Anleitung: Wie man ELECTRA von Grund auf für Spanisch trainiert
Ursprünglich veröffentlicht von Skim AI's Machine Learning Researcher, Chris Tran.Einführung
Dieser Artikel beschreibt, wie man ELECTRA, ein weiteres Mitglied der Transformer Pre-Training-Methodenfamilie, für Spanisch vortrainiert, um in Natural Language Processing Benchmarks die besten Ergebnisse zu erzielen. Er ist Teil III einer Serie über das Training benutzerdefinierter BERT-Sprachmodelle für Spanisch für eine Vielzahl von Anwendungsfällen:
- Teil I: Wie man ein RoBERTa-Sprachmodell für Spanisch von Grund auf trainiert
- Teil II: Trainieren eines SpanBERTa-Sprachmodells für die Erkennung von benannten Entitäten (NER)
1. Einleitung
Auf der ICLR 2020, ELECTRA: Vortraining von Textkodierern als Unterscheidungsmerkmale statt als Generatorenwurde eine neue Methode für das selbstüberwachte Lernen von Sprachrepräsentationen vorgestellt. ELECTRA ist ein weiteres Mitglied der Transformer-Pre-Training-Methodenfamilie, deren frühere Mitglieder wie BERT, GPT-2, RoBERTa viele Spitzenergebnisse in Benchmarks für die Verarbeitung natürlicher Sprache erzielt haben.
Im Gegensatz zu anderen maskierten Sprachmodellierungsmethoden bietet ELECTRA eine effizientere Pre-Trainingsaufgabe, die sogenannte "replaced token detection". In kleinem Maßstab kann ELECTRA-small auf einem einzigen Grafikprozessor 4 Tage lang trainiert werden und übertrifft dabei GPT (Radford et al., 2018) (trainiert mit 30x mehr Rechenleistung) beim GLUE-Benchmark. In einem großen Maßstab übertrifft ELECTRA-large ALBERT (Lan et al., 2019) auf GLUE und setzt einen neuen Stand der Technik für SQuAD 2.0.

ELECTRA übertrifft durchgängig maskierte Sprachmodell-Vortrainingsansätze.
{: .text-center}
2. Verfahren
Maskierte Methoden zur Sprachmodellierung vor dem Training wie BERT (Devlin et al., 2019) die Eingabe verfälschen, indem sie einige Token (in der Regel 15% der Eingabe) ersetzen durch [MASK] und trainieren dann ein Modell, um die ursprünglichen Token zu rekonstruieren.
Anstelle einer Maskierung verfälscht ELECTRA die Eingabe, indem es einige Token durch Stichproben aus den Ausgaben eines maskierten Sprachmodells ersetzt. Dann wird ein diskriminatives Modell trainiert, um vorherzusagen, ob jedes Token ein Original oder ein Ersatz ist. Nach dem Vortraining wird der Generator verworfen, und der Diskriminator wird bei nachgelagerten Aufgaben feinabgestimmt.
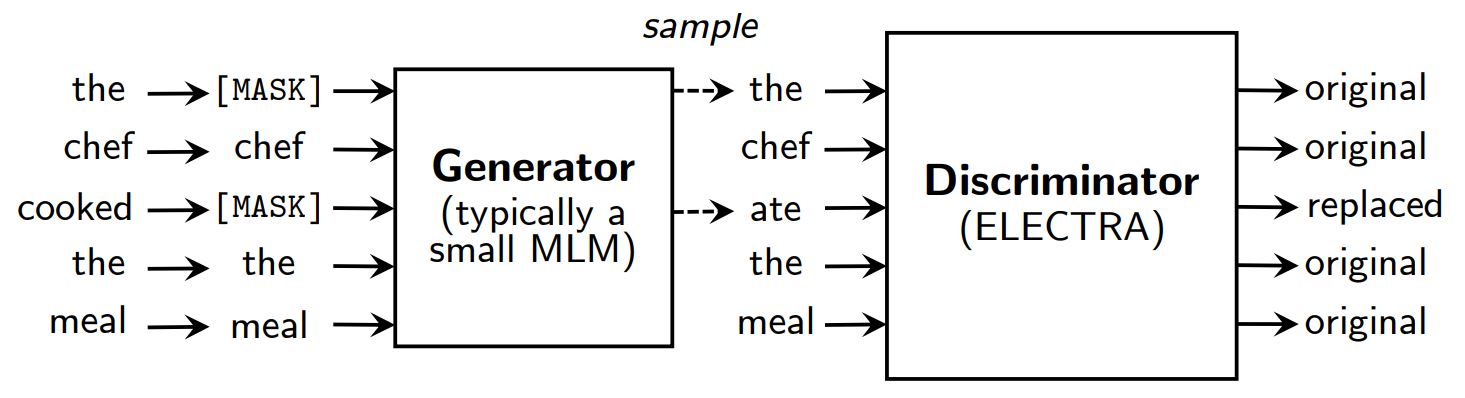
Ein Überblick über ELECTRA.
{: .text-center}
Obwohl ELECTRA wie GAN über einen Generator und einen Diskriminator verfügt, ist es nicht nachteilig, da der Generator, der verfälschte Token erzeugt, mit maximaler Wahrscheinlichkeit trainiert wird und nicht, um den Diskriminator zu täuschen.
Warum ist ELECTRA so effizient?
Mit einem neuen Trainingsziel kann ELECTRA eine vergleichbare Leistung erzielen wie starke Modelle wie RoBERTa (Liu et al., (2019) das mehr Parameter hat und 4x mehr Rechenleistung für das Training benötigt. In diesem Papier wurde eine Analyse durchgeführt, um zu verstehen, was wirklich zur Effizienz von ELECTRA beiträgt. Die wichtigsten Ergebnisse sind:
- ELECTRA profitiert in hohem Maße davon, dass der Verlust für alle Token der Eingabe und nicht nur für eine Teilmenge definiert ist. Genauer gesagt, sagt der Diskriminator in ELECTRA jedes Token der Eingabe voraus, während der Generator in BERT nur 15% maskierte Token der Eingabe voraussagt.
- BERT's performance is slightly harmed because in the pre-training phase, the model sees
[MASK]Token, während dies in der Feinabstimmungsphase nicht der Fall ist.
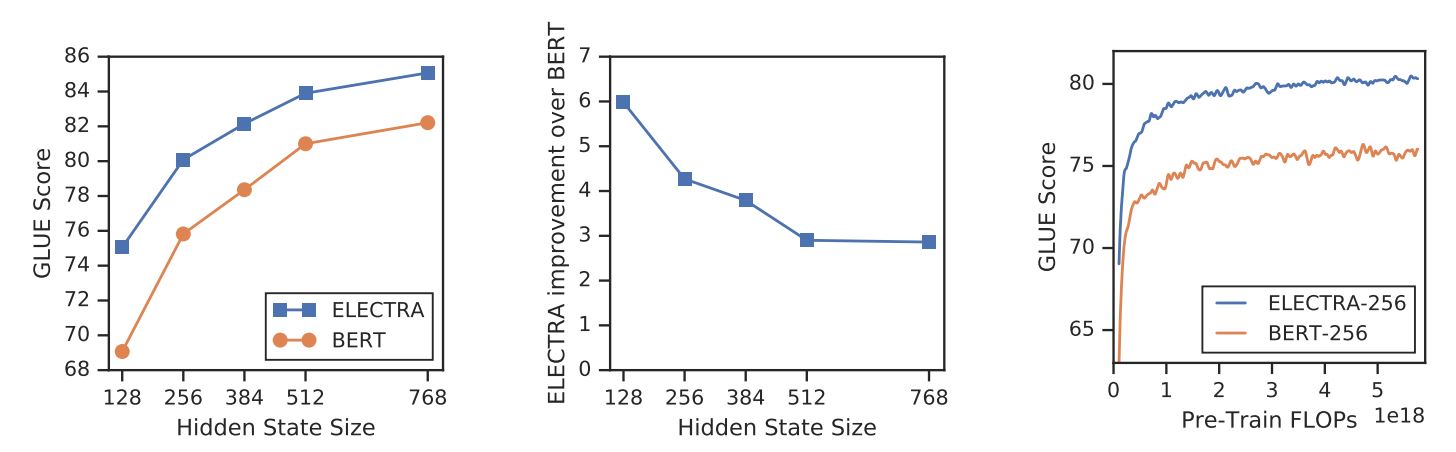
ELECTRA vs. BERT
{: .text-center}
3. ELECTRA vortrainieren
In diesem Abschnitt trainieren wir ELECTRA von Grund auf mit TensorFlow unter Verwendung von Skripten, die von den Autoren von ELECTRA in google-forschung/electra. Then we will convert the model to PyTorch's checkpoint, which can be easily fine-tuned on downstream tasks using Hugging Face's Transformatoren Bibliothek.
Einrichtung
!pip install tensorflow==1.15
!pip install transformers==2.8.0
!git clone https://github.com/google-research/electra.git
importieren os
json importieren
from transformers import AutoTokenizer
Daten
Wir werden ELECTRA mit einem spanischen Filmuntertitel-Datensatz trainieren, der von OpenSubtitles abgerufen wurde. Dieser Datensatz ist 5,4 GB groß und wir trainieren mit einer kleinen Teilmenge von ~30 MB für die Präsentation.
DATA_DIR = "./data" #@param {Typ: "string"}
TRAIN_SIZE = 1000000 #@param {Typ: "Ganzzahl"}
MODEL_NAME = "electra-spanish" #@param {type: "string"}
# Herunterladen und Entpacken des Datensatzes für spanische Filmsubstitute
if not os.path.exists(DATA_DIR):
!mkdir -p $DATA_DIR
!wget "https://object.pouta.csc.fi/OPUS-OpenSubtitles/v2016/mono/es.txt.gz" -O $DATA_DIR/OpenSubtitles.txt.gz
!gzip -d $DATA_DIR/OpenSubtitles.txt.gz
!head -n $TRAIN_SIZE $DATA_DIR/OpenSubtitles.txt > $DATA_DIR/train_data.txt
!rm $DATA_DIR/OpenSubtitles.txt
Bevor wir den Pre-Training-Datensatz erstellen, sollten wir sicherstellen, dass der Korpus das folgende Format hat:
- jede Zeile ist ein Satz
- eine Leerzeile trennt zwei Dokumente
Pretraining-Datensatz erstellen
Wir verwenden den Tokenizer von bert-base-multilingual-cased um spanische Texte zu verarbeiten.
# Speichern Sie den trainierten WordPiece-Tokenizer, um vocab.txt zu erhalten
tokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
tokenizer.save_pretrained(DATA_DIR)
Wir verwenden build_pretraining_dataset.py einen Pre-Training-Datensatz aus einem Dump von Rohtext zu erstellen.
!python3 electra/build_pretraining_dataset.py \
--corpus-dir $DATA_DIR \
--vocab-file $DATA_DIR/vocab.txt \
--output-dir $DATA_DIR/pretrain_tfrecords \
--max-seq-length 128 \
--blanks-separate-docs False \
--no-lower-case \
--num-processes 5
Ausbildung beginnen
Wir verwenden run_pretraining.py um ein ELECTRA-Modell vorzutrainieren.
Um ein kleines ELECTRA-Modell für 1 Million Schritte zu trainieren, führen Sie aus:
python3 run_pretraining.py --data-dir $DATA_DIR --model-name electra_small
Dies dauert etwas mehr als 4 Tage auf einem Tesla V100 Grafikprozessor. Allerdings sollte das Modell nach 200k Schritten (10 Stunden Training auf der v100 GPU) anständige Ergebnisse erzielen.
Um die Schulung anzupassen, erstellen Sie eine .json Datei mit den Hyperparametern. Bitte beachten Sie configure_pretraining.py für Standardwerte für alle Hyperparameter.
Im Folgenden werden die Hyperparameter so eingestellt, dass das Modell in nur 100 Schritten trainiert wird.
hparams = {
"do_train": "true",
"do_eval": "false",
"model_size": "klein",
"do_lower_case": "false",
"vocab_size": 119547,
"num_train_steps": 100,
"save_checkpoints_steps": 100,
"train_batch_size": 32,
}
with open("hparams.json", "w") as f:
json.dump(hparams, f)
Let's start training:
!python3 electra/run_pretraining.py \
--data-dir $DATA_DIR \
--model-name $MODEL_NAME \
--hparams "hparams.json"
Wenn Sie auf einer virtuellen Maschine trainieren, führen Sie die folgenden Zeilen im Terminal aus, um den Trainingsprozess mit TensorBoard zu überwachen.
pip install -U tensorboard
tensorboard dev upload --logdir data/models/electra-spanish
Dies ist die TensorBoard des Trainings von ELECTRA-small für 1 Million Schritte in 4 Tagen auf einer V100 GPU.
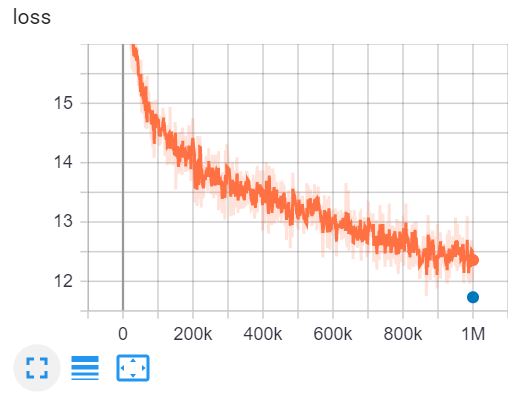 {: .align-center}
{: .align-center}
4. Konvertierung von Tensorflow-Checkpoints in das PyTorch-Format
Hugging Face hat ein Werkzeug um Tensorflow-Checkpoints in PyTorch zu konvertieren. Allerdings wurde dieses Tool noch nicht für ELECTRA aktualisiert. Glücklicherweise habe ich ein GitHub Repo von @lonePatient gefunden, das uns bei dieser Aufgabe helfen kann.
!git clone https://github.com/lonePatient/electra_pytorch.git
MODEL_DIR = "data/models/electra-spanish/"
config = {
"vocab_size": 119547,
"embedding_size": 128,
"hidden_size": 256,
"num_hidden_layers": 12,
"num_attention_heads": 4,
"intermediate_size": 1024,
"generator_size":"0.25",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"attention_probs_dropout_prob": 0.1,
"max_position_embeddings": 512,
"type_vocab_size": 2,
"initializer_range": 0.02
}
with open(MODEL_DIR + "config.json", "w") as f:
json.dump(config, f)
!python electra_pytorch/convert_electra_tf_checkpoint_to_pytorch.py \
--tf_checkpoint_path=$MODEL_DIR \
--electra_config_file=$MODEL_DIR/config.json \
--pytorch_dump_pfad=$MODEL_DIR/pytorch_model.bin
Verwenden Sie ELECTRA mit Transformatoren
Nachdem wir den Modell-Checkpoint in das PyTorch-Format konvertiert haben, können wir unser vortrainiertes ELECTRA-Modell für nachgelagerte Aufgaben mit der Funktion Transformatoren Bibliothek.
importieren torch
from transformers import ElectraForPreTraining, ElectraTokenizerFast
discriminator = ElectraForPreTraining.from_pretrained(MODEL_DIR)
tokenizer = ElectraTokenizerFast.from_pretrained(DATA_DIR, do_lower_case=False)
sentence = "Los pájaros están cantando" # Die Vögel singen
fake_sentence = "Los pájaros están hablando" # Die Vögel sprechen
fake_tokens = tokenizer.tokenize(fake_sentence, add_special_tokens=True)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
diskriminator_outputs = diskriminator(fake_inputs)
Vorhersagen = diskriminator_outputs[0] > 0
[print("%7s" % token, end="") for token in fake_tokens]
print("\n")
[print("%7s" % int(prediction), end="") for prediction in predictions.tolist()];
[CLS] Los paj ##aros estan habla ##ndo [SEP]
1 0 0 0 0 0 0 0
Unser Modell wurde nur für 100 Schritte trainiert, so dass die Vorhersagen nicht genau sind. Das vollständig trainierte ELECTRA-small für Spanisch kann wie folgt geladen werden:
discriminator = ElectraForPreTraining.from_pretrained("skimai/electra-small-spanish")
tokenizer = ElectraTokenizerFast.from_pretrained("skimai/electra-small-spanish", do_lower_case=False)
5. Schlussfolgerung
In diesem Artikel sind wir das ELECTRA-Papier durchgegangen, um zu verstehen, warum ELECTRA derzeit der effizienteste Ansatz für das Pre-Training von Transformern ist. In kleinem Maßstab kann ELECTRA-small 4 Tage lang auf einer GPU trainiert werden und übertrifft GPT beim GLUE-Benchmark. Im großen Maßstab setzt ELECTRA-large einen neuen Maßstab für SQuAD 2.0.
Wir trainieren dann ein ELECTRA-Modell auf spanischen Texten und konvertieren den Tensorflow-Checkpoint in PyTorch und verwenden das Modell mit dem Transformatoren Bibliothek.
Referenzen
- [1] ELECTRA: Vortraining von Textkodierern als Unterscheidungsmerkmale statt als Generatoren
- [2] google-forschung/electra - the official GitHub repository of the original paper
- [3] electra_pytorch - a PyTorch implementation of ELECTRA


