
Was ist Deep Learning?



Was ist Deep Learning?
Was ist Deep Learning? Deep Learning (DL) ist ein Teilbereich des maschinellen Lernens (ML), der sich in erster Linie darauf konzentriert, die Fähigkeit des menschlichen Gehirns zum Lernen und Verarbeiten von Informationen nachzuahmen. In der sich rasch entwickelnden Welt der künstlichen Intelligenz (KI) hat sich Deep Learning als bahnbrechende Technologie herauskristallisiert, die sich auf praktisch alle Bereiche auswirkt, vom Gesundheitswesen bis hin zu autonomen...
Um diese Fähigkeit zum Lernen und Verarbeiten von Informationen zu erreichen, stützt sich Deep Learning auf ein komplexes Netz miteinander verbundener Neuronen, die als künstliche neuronale Netze (ANNs) bezeichnet werden. Durch die Nutzung der Leistungsfähigkeit von ANNs und ihrer Fähigkeit, sich im Laufe der Zeit automatisch anzupassen und zu verbessern, können Deep-Learning-Algorithmen komplizierte Muster entdecken, aussagekräftige Erkenntnisse gewinnen und Vorhersagen mit bemerkenswerter Genauigkeit treffen.
*Bevor Sie diesen Blog über Deep Learning lesen, sollten Sie sich unsere Erklärung zu KI vs. ML ansehen.
Die Bausteine des Deep Learning
Die Grundlage des Deep Learning bildet das Konzept der ANNs, die von der Struktur und Funktion des menschlichen Gehirns inspiriert sind. ANNs bestehen aus verschiedenen Schichten miteinander verbundener Knoten oder Neuronen, wobei jedes Neuron Informationen verarbeitet und sie an die nächste Schicht weitergibt. Diese Schichten können dann lernen und sich anpassen, indem sie die Gewichte der Verbindungen zwischen den Neuronen anpassen.
In einem ANN gibt es künstliche Neuronen, von denen jedes einen Input von einem anderen erhält, bevor es die Informationen verarbeitet und den Output an verbundene Neuronen sendet. Die Stärke dieser Verbindungen zwischen den Neuronen wird als Gewichte bezeichnet, und diese Gewichte bestimmen die Bedeutung der einzelnen Eingaben für die Gesamtberechnung.
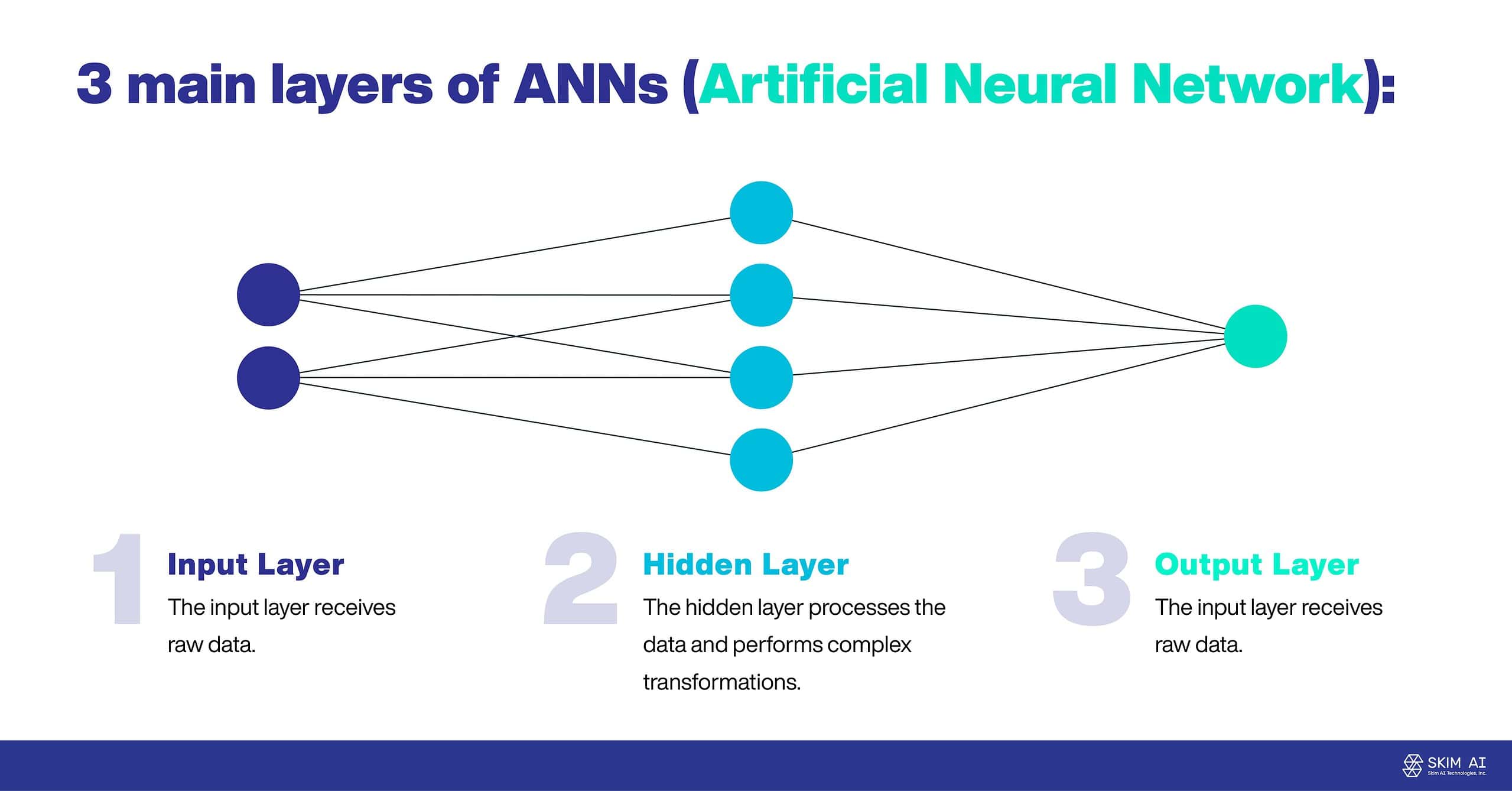
ANNs bestehen häufig aus drei Hauptschichten:
Eingabeschicht: Die Eingabeschicht erhält Rohdaten.
Verborgene Schicht: Die verborgene Schicht verarbeitet die Daten und führt komplexe Transformationen durch.
Ausgabeschicht: Die Ausgabeschicht liefert das Endergebnis.
Ein weiterer wichtiger Baustein von ANNs sind Aktivierungsfunktionen, die die Ausgabe jedes Neurons auf der Grundlage der empfangenen Eingabe bestimmen. Diese Funktionen führen Nichtlinearität in das Netz ein und ermöglichen es ihm, komplexe Muster zu lernen und komplizierte Berechnungen durchzuführen.
Beim Deep Learning dreht sich alles um den Lernprozess, bei dem das Netzwerk seine Gewichte anpasst, um den Fehler zwischen seinen Vorhersagen und den Ergebnissen zu minimieren. Dieser Lernprozess beinhaltet oft die Verwendung einer Verlustfunktion, die den Unterschied zwischen der Ausgabe des Netzwerks und den wahren Werten quantifiziert.
Die verschiedenen Arten von Lernarchitekturen
Allerdings folgt Deep Learning nicht einer einzigen Lernarchitektur. Es gibt einige Haupttypen von Architekturen, die für ein breites Spektrum von Problemen verwendet werden. Zwei der gängigsten sind Faltungsneuronale Netze (CNNs) und rekurrente Neuronale Netze (RNNs). Es gibt jedoch noch einige andere, wie z. B. LSTMs, GRUs und Autoencoder.
Faltungsneuronale Netze (CNNs)
CNNs spielen eine zentrale Rolle bei Computer Vision und Bilderkennungsaufgaben. Vor dem Aufkommen von CNNs waren für diese Aufgaben mühsame und zeitintensive Techniken zur Merkmalsextraktion für die Objektidentifizierung in Bildern erforderlich. Im Zusammenhang mit der Bilderkennung besteht die Hauptfunktion eines CNN darin, Bilder in eine besser handhabbare Form umzuwandeln und dabei wesentliche Merkmale für genaue Vorhersagen beizubehalten.
CNNs übertreffen oft andere neuronale Netze aufgrund ihrer außergewöhnlichen Leistung bei Bild-, Audio- oder Spracheingaben.
Sie verwenden drei Haupttypen von Schichten, um ihre Aufgaben zu erfüllen:
Faltungsschicht: Identifiziert Merkmale innerhalb von Pixeln.
Pooling-Schicht: Abstrahiert Merkmale für die weitere Bearbeitung.
Vollständig verbundene (FC) Schicht: Verwendet die erfassten Merkmale für die Vorhersage.
Die Faltungsschicht ist die grundlegendste Komponente eines CNN, in der der Großteil der Berechnungen stattfindet. Diese Schicht besteht aus Eingabedaten, einem Filter und einer Merkmalskarte. Faltungsschichten führen eine Faltungsoperation an den Eingabedaten durch, bevor sie das Ergebnis an die Pooling-Schicht weiterleiten.
Bei einer Bilderkennungsaufgabe verdichtet diese Faltung alle Pixel innerhalb des rezeptiven Feldes zu einem einzigen Wert. Vereinfacht gesagt, wird durch die Anwendung einer Faltung auf ein Bild dessen Größe reduziert und alle Informationen innerhalb des Feldes in einem einzigen Pixel zusammengefasst. Grundlegende Merkmale, wie horizontale und diagonale Kanten, werden in der Faltungsschicht extrahiert. Die von der Faltungsschicht erzeugte Ausgabe wird als Merkmalskarte bezeichnet.
Der Hauptzweck der Pooling-Ebene besteht darin, die Größe der Merkmalskarte zu reduzieren und dadurch den Rechenaufwand und die Verbindungen zwischen den Ebenen zu verringern.
Die dritte Schicht in einem CNN ist die FC-Schicht, die die Neuronen zwischen zwei verschiedenen Schichten verbindet. Oft wird sie vor der Ausgabeschicht positioniert, um die Eingangsbilder der vorherigen Schichten zu glätten. Das geglättete Bild durchläuft in der Regel weitere FC-Schichten, in denen mathematische Funktionen den Klassifizierungsprozess einleiten.
Rekurrente Neuronale Netze (RNNs)
Rekurrente neuronale Netze (RNNs) gehören zu den modernsten Algorithmen, die entwickelt wurden, und werden von weit verbreiteten Technologien wie Siri und der Google-Sprachsuche eingesetzt.
Das RNN ist der erste Algorithmus, der seine Eingaben dank eines internen Speichers beibehalten kann, was ihn für Probleme des maschinellen Lernens mit sequentiellen Daten wie Sprache, Text, Finanzdaten, Audio und mehr wertvoll macht. Die einzigartige Architektur von RNNs ermöglicht es ihnen, Abhängigkeiten und Muster innerhalb der Sequenzen effektiv zu erfassen, was genauere Vorhersagen und eine bessere Gesamtleistung in einem breiten Spektrum von Anwendungen ermöglicht.
Ein RNN zeichnet sich dadurch aus, dass es einen verborgenen Zustand beibehalten kann, der als interner Speicher fungiert und es ihm ermöglicht, sich an Informationen aus früheren Zeitschritten zu erinnern. Dank dieser Speicherfähigkeit können RNNs weitreichende Abhängigkeiten innerhalb der Eingabesequenz erlernen und ausnutzen, was sie für Aufgaben wie Zeitreihenanalyse, NLP und Spracherkennung besonders effektiv macht.
Die Struktur eines RNN besteht aus einer Reihe miteinander verbundener Schichten, wobei jede Schicht für die Verarbeitung eines Zeitschritts der Eingabesequenz zuständig ist. Die Eingabe für jeden Zeitschritt ist eine Kombination aus dem aktuellen Datenpunkt und dem verborgenen Zustand aus dem vorherigen Zeitschritt. Diese Informationen werden dann von der RNN-Schicht verarbeitet, die den verborgenen Zustand aktualisiert und eine Ausgabe erzeugt. Der verborgene Zustand fungiert als Speicher, in dem Informationen aus früheren Zeitschritten gespeichert werden, um die zukünftige Verarbeitung zu beeinflussen.
Herausforderungen des Deep Learning
Trotz der bemerkenswerten Erfolge des Deep Learning gibt es noch einige Herausforderungen und Bereiche für die künftige Forschung, die weiter erforscht werden müssen, um das Feld voranzubringen und einen verantwortungsvollen Einsatz dieser Technologien zu gewährleisten.
Interpretierbarkeit und Erklärbarkeit
Eine der größten Einschränkungen von Deep-Learning-Modellen ist ihr Blackbox-Charakter, der sich auf die Undurchsichtigkeit und Komplexität ihrer internen Funktionsweise bezieht. Dies macht es für Praktiker, Nutzer und Regulierungsbehörden schwierig, die Gründe für ihre Vorhersagen und Entscheidungen zu verstehen und zu interpretieren. Entwicklung von Techniken für bessere Interpretierbarkeit und Erklärbarkeit ist von entscheidender Bedeutung, um diese Bedenken auszuräumen, und hat mehrere wichtige Auswirkungen.

Eine verbesserte Interpretierbarkeit und Erklärbarkeit wird Nutzern und Interessengruppen helfen, besser zu verstehen, wie Deep-Learning-Modelle zu ihren Vorhersagen oder Entscheidungen kommen, und so das Vertrauen in ihre Fähigkeiten und Zuverlässigkeit stärken. Dies ist besonders wichtig bei sensiblen Anwendungen wie z. B. GesundheitswesenDie Folgen von KI-Entscheidungen können sich erheblich auf das Leben des Einzelnen auswirken.
Die Fähigkeit, Deep-Learning-Modelle zu interpretieren und zu erklären, kann auch die Identifizierung und Abschwächung potenzieller Verzerrungen, Fehler oder unbeabsichtigter Folgen erleichtern. Durch Einblicke in das Innenleben der Modelle können Praktiker fundierte Entscheidungen über die Auswahl, das Training und den Einsatz von Modellen treffen, um sicherzustellen, dass KI-Systeme verantwortungsvoll und ethisch korrekt eingesetzt werden.
Einblicke in die internen Prozesse von Deep-Learning-Modellen können Praktikern dabei helfen, Probleme oder Fehler zu erkennen, die sich auf ihre Leistung auswirken können. Durch das Verständnis der Faktoren, die die Vorhersagen eines Modells beeinflussen, können Praktiker die Architektur, die Trainingsdaten oder die Hyperparameter feinabstimmen, um die Gesamtleistung und Genauigkeit zu verbessern.
Daten und rechnerische Anforderungen für Deep Learning
Deep Learning ist unglaublich leistungsfähig, aber mit dieser Leistung gehen erhebliche Daten- und Rechenanforderungen einher. Diese Anforderungen können manchmal eine Herausforderung für die Implementierung von Deep Learning darstellen.

Eine der größten Herausforderungen beim Deep Learning ist der Bedarf an großen Mengen an beschrifteten Trainingsdaten. Deep-Learning-Modelle benötigen oft große Datenmengen, um effektiv lernen und verallgemeinern zu können. Das liegt daran, dass diese Modelle darauf ausgelegt sind, automatisch Merkmale aus Rohdaten zu extrahieren und zu lernen. Je mehr Daten sie zur Verfügung haben, desto besser können sie komplexe Muster und Beziehungen erkennen und erfassen.
Die Beschaffung und Kennzeichnung solch großer Datenmengen kann jedoch zeitaufwändig, arbeitsintensiv und teuer sein. In manchen Fällen sind beschriftete Daten knapp oder schwer zu beschaffen, insbesondere in spezialisierten Bereichen wie der medizinischen Bildgebung oder seltenen Sprachen. Um diese Herausforderung zu bewältigen, haben Forscher verschiedene Techniken wie Datenerweiterung, Transferlernen und unüberwachtes oder halbüberwachtes Lernen erforscht, die darauf abzielen, die Modellleistung mit begrenzten beschrifteten Daten zu verbessern.
Deep-Learning-Modelle erfordern auch erhebliche Rechenressourcen für Training und Schlussfolgerungen. Diese Modelle umfassen in der Regel eine große Anzahl von Parametern und Schichten, die leistungsstarke Hardware und spezielle Verarbeitungseinheiten wie GPUs oder TPUs erfordern, um die erforderlichen Berechnungen effizient durchzuführen.
Die Rechenanforderungen von Deep-Learning-Modellen können für einige Anwendungen oder Organisationen mit begrenzten Ressourcen unerschwinglich sein, was zu längeren Trainingszeiten und höheren Kosten führt. Um diese Herausforderungen zu entschärfen, haben Forscher und Praktiker Methoden zur Optimierung von Deep-Learning-Modellen und zur Verringerung der Modellgröße und -komplexität bei gleichbleibender Leistung erforscht, was letztlich zu kürzeren Trainingszeiten und geringeren Ressourcenanforderungen führt.
Robustheit und Sicherheit
Deep-Learning-Modelle haben in verschiedenen Anwendungen eine außergewöhnliche Leistung gezeigt; sie sind jedoch anfällig für feindliche Angriffe. Bei diesen Angriffen werden absichtlich bösartige Eingabebeispiele erstellt, um das Modell zu täuschen und falsche Vorhersagen oder Ausgaben zu erzeugen. Die Behebung dieser Schwachstellen und die Verbesserung der Robustheit und Sicherheit von Deep-Learning-Modellen gegenüber schädlichen Beispielen und anderen potenziellen Risiken ist eine wichtige Herausforderung für die KI-Gemeinschaft. Die Folgen solcher Angriffe können weitreichend sein, insbesondere in Bereichen wie autonome Fahrzeuge, Cybersicherheit und Gesundheitswesen, in denen die Integrität und Zuverlässigkeit von KI-Systemen von größter Bedeutung sind.
Angriffe durch Angreifer nutzen die Empfindlichkeit von Deep-Learning-Modellen gegenüber kleinen, oft nicht wahrnehmbaren Störungen in den Eingabedaten aus. Selbst geringfügige Änderungen an den Originaldaten können zu dramatisch unterschiedlichen Vorhersagen oder Klassifizierungen führen, obwohl die Eingaben für menschliche Beobachter praktisch identisch erscheinen. Dieses Phänomen gibt Anlass zu Bedenken hinsichtlich der Stabilität und Zuverlässigkeit von Deep-Learning-Modellen in realen Szenarien, in denen Angreifer die Eingaben manipulieren könnten, um die Systemleistung zu beeinträchtigen.
Anwendungen von Deep Learning
Deep Learning hat sein transformatives Potenzial in einem breiten Spektrum von Anwendungen und Branchen unter Beweis gestellt. Einige der bemerkenswertesten Anwendungen sind:
- Bilderkennung und Computer Vision: Deep Learning hat die Genauigkeit und Effizienz von Bilderkennungs- und Computer-Vision-Aufgaben drastisch verbessert. Insbesondere CNNs haben sich bei der Bildklassifizierung, Objekterkennung und Segmentierung hervorgetan. Diese Fortschritte haben den Weg für Anwendungen wie Gesichtserkennung, autonome Fahrzeuge und medizinische Bildanalyse geebnet.
- NLP: Deep Learning hat die Verarbeitung natürlicher Sprache revolutioniert und die Entwicklung anspruchsvollerer Sprachmodelle und Anwendungen ermöglicht. Verschiedene Modelle wurden eingesetzt, um bei Aufgaben wie maschineller Übersetzung, Stimmungsanalyse, Textzusammenfassung und Systemen zur Beantwortung von Fragen Spitzenergebnisse zu erzielen.
- Spracherkennung und Spracherzeugung: Auch bei der Spracherkennung und -generierung hat das Deep Learning große Fortschritte gemacht. Techniken wie RNNs und CNNs wurden eingesetzt, um genauere und effizientere automatische Spracherkennungssysteme (ASR) zu entwickeln, die gesprochene Sprache in geschriebenen Text umwandeln. Deep-Learning-Modelle haben auch eine hochwertige Sprachsynthese ermöglicht, die aus Text menschenähnliche Sprache erzeugt.
- Reinforcement Learning: Deep Learning, kombiniert mit Reinforcement Learning, hat zur Entwicklung von Deep Reinforcement Learning (DRL) Algorithmen. DRL wurde eingesetzt, um Agenten zu trainieren, die in der Lage sind, optimale Strategien zur Entscheidungsfindung und Kontrolle zu erlernen. Die Anwendungen von DRL erstrecken sich über die Bereiche Robotik, Finanzen und Spiele.
- Generative Modelle: Generative Deep-Learning-Modelle, wie z. B. Generative adversarische Netze (GANs)haben ein bemerkenswertes Potenzial für die Erzeugung realistischer Datenmuster gezeigt. Diese Modelle wurden für Aufgaben wie Bildsynthese, Stilübertragung, Datenerweiterung und Anomalieerkennung verwendet.
- Gesundheitswesen: Deep Learning hat auch im Gesundheitswesen einen bedeutenden Beitrag zur Revolutionierung der Diagnostik, der Arzneimittelforschung und der personalisierten Medizin geleistet. So wurden beispielsweise Deep-Learning-Algorithmen zur Analyse medizinischer Bilder für die Früherkennung von Krankheiten, zur Vorhersage von Patientenergebnissen und zur Identifizierung potenzieller Arzneimittelkandidaten eingesetzt.
Revolutionierung von Branchen und Anwendungen
Deep Learning hat sich zu einer bahnbrechenden Technologie entwickelt, die das Potenzial hat, eine Vielzahl von Branchen und Anwendungen zu revolutionieren. Im Kern nutzt Deep Learning künstliche neuronale Netze, um die Fähigkeit des menschlichen Gehirns zum Lernen und Verarbeiten von Informationen zu imitieren. CNNs und RNNs sind zwei bekannte Architekturen, die bedeutende Fortschritte in Bereichen wie Bilderkennung, NLP, Spracherkennung und Gesundheitswesen ermöglicht haben.
Deep Learning steht immer noch vor Herausforderungen, die angegangen werden müssen, um seinen verantwortungsvollen und ethischen Einsatz zu gewährleisten. Zu diesen Herausforderungen gehören die Verbesserung der Interpretierbarkeit und Erklärbarkeit von Deep-Learning-Modellen, die Bewältigung von Daten- und Rechenanforderungen sowie die Verbesserung der Robustheit und Sicherheit dieser Modelle gegen Angriffe von außen.
Da Forscher und Praktiker weiterhin innovative Techniken zur Bewältigung dieser Herausforderungen erforschen und entwickeln, wird sich der Bereich des Deep Learning zweifellos weiter entwickeln und neue Fähigkeiten und Anwendungen hervorbringen, die die Art und Weise, wie wir leben, arbeiten und mit der Welt um uns herum interagieren, verändern werden. Mit seinem immensen Potenzial wird Deep Learning eine zunehmend wichtige Rolle bei der Gestaltung der Zukunft der künstlichen Intelligenz spielen und den technologischen Fortschritt in verschiedenen Bereichen vorantreiben


