
チュートリアルELECTRAをゼロからスペイン語用にプリトレーニングする方法



チュートリアルELECTRAをゼロからスペイン語用にプリトレーニングする方法
原文はSkim AIの機械学習研究者、クリス・トラン。![]()
はじめに
この記事では、自然言語処理ベンチマークで最先端の結果を達成するために、Transformer事前学習メソッドファミリーのもう1つのメンバーであるELECTRAをスペイン語用に事前学習する方法について説明します。これは、さまざまなユースケースのためのスペイン語のカスタムBERT言語モデルのトレーニングに関するシリーズのパートIIIです:
1.はじめに
ICLR2020にて、 ELECTRA:テキスト・エンコーダを生成器ではなく識別器として事前学習させる自己教師付き言語表現学習のための新しい手法であるELECTRAが紹介された。ELECTRAは、BERT、GPT-2、RoBERTaといった従来のメンバーが自然言語処理ベンチマークで多くの最先端結果を達成しているTransformer事前学習手法ファミリーのもう一つのメンバーである。
他のマスクされた言語モデリング手法とは異なり、ELECTRAは置換されたトークン検出と呼ばれる、よりサンプル効率の良い事前学習タスクを行う。小規模の場合、ELECTRA-smallは1つのGPUで4日間訓練することで、以下の性能を上回ることができます。 GPT(ラドフォードら、2018年) (ELECTRA-largeは、GLUEベンチマーク(30倍以上の計算量で学習)において、ELECTRA-largeを上回った。大規模では、ELECTRA-largeは以下を上回る。 ALBERT(ランら、2019年) GLUEで、SQuad 2.0の新たな最先端を切り開く。

ELECTRAは一貫してマスク言語モデルの事前学習アプローチを凌駕している。
{: .text-center}
2.方法
次のようなマスク言語モデリング事前学習法 BERT(デブリンら、2019年) いくつかのトークン(通常、入力の15%)を以下のように置き換えることによって、入力を破壊する。 [マスク] そして、元のトークンを再構築するモデルを訓練する。
ELECTRAはマスキングの代わりに、いくつかのトークンを小さくマスキングされた言語モデルの出力からのサンプルに置き換えることで入力を破損する。その後、各トークンがオリジナルか置換かを予測する識別モデルを学習する。事前学習の後、生成器は捨てられ、識別器は下流のタスクで微調整される。
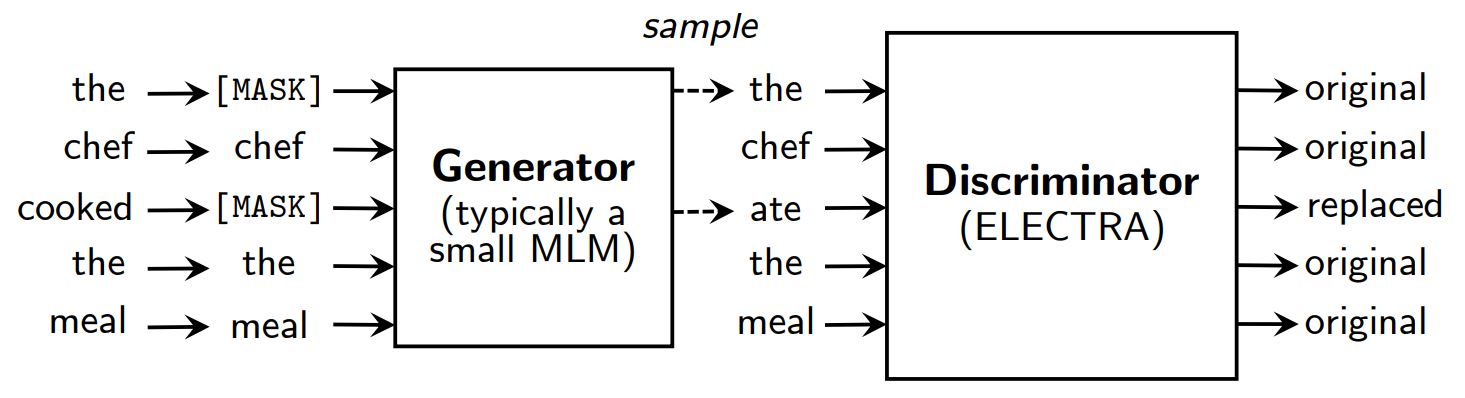
ELECTRAの概要。
{: .text-center}
GANのように生成器と識別器を持つが、ELECTRAは敵対的ではなく、破損したトークンを生成する生成器は、識別器を欺くために訓練されるのではなく、最尤法で訓練される。
なぜELECTRAはこれほど効率的なのか?
ELECTRAは、新たな訓練目的によって、以下のような強力なモデルに匹敵するパフォーマンスを達成することができる。 RoBERTa(Liu et al. ELECTRAは、より多くのパラメータを持ち、学習に4倍の計算量を必要とする。本論文では、ELECTRAの効率に何が本当に貢献しているのかを理解するために分析を行った。主な結果は以下の通りである:
- ELECTRAは、部分集合ではなく全ての入力トークンに対して定義された損失を持つことで大きな恩恵を受けている。より具体的には、ELECTRAでは識別器は入力のすべてのトークンを予測するが、BERTでは生成器は入力の15%個のマスクされたトークンのみを予測する。
- BERTの性能は若干損なわれている。
[マスク]トークンは、微調整の段階ではそうではない。
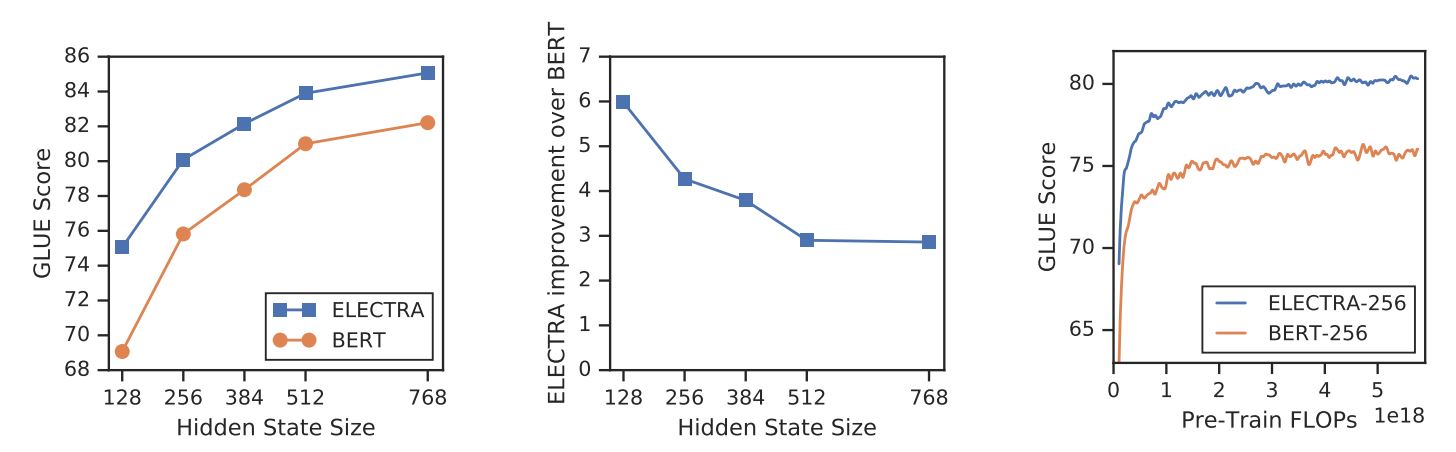
ELECTRA対BERT
{: .text-center}
3.ELECTRAの事前トレーニング
このセクションでは、TensorFlowを使ってELECTRAをゼロから訓練する。 グーグル-リサーチ/エレクトラ.その後、モデルをPyTorchのチェックポイントに変換し、Hugging Faceの 変圧器 図書館
セットアップ
!.pip install tensorflow==1.15
!.pip transformers==2.8.0 をインストールする。
!git clone https://github.com/google-research/electra.git
インポート os
インポート json
from transformers import AutoTokenizer
データ
OpenSubtitlesから取得したスペイン語映画字幕データセットでELECTRAの事前学習を行います。このデータセットのサイズは5.4GBで、プレゼンテーションのために~30MBの小さなサブセットで学習します。
DATA_DIR = "./data" #@param {タイプ:「文字列"}。
TRAIN_SIZE = 1000000 #@param {type: "integer"}。
MODEL_NAME = "electra-spanish" #@param {type:"文字列"}。
# スペイン語映画の字幕データセットをダウンロードして解凍する
if not os.path.exists(DATA_DIR):
mkdir -p $DATA_DIR
!wget "https://object.pouta.csc.fi/OPUS-OpenSubtitles/v2016/mono/es.txt.gz" -O $DATA_DIR/OpenSubtitles.txt.gz
!gzip -d $DATA_DIR/OpenSubtitles.txt.gz。
!head -n $TRAIN_SIZE $DATA_DIR/OpenSubtitles.txt > $DATA_DIR/train_data.txt
!rm $DATA_DIR/OpenSubtitles.txt
プリ・トレーニング・データセットを構築する前に、コーパスが以下のような形式であることを確認する必要がある:
- 各行は文章である
- 空行
事前学習データセットの構築
のトークナイザーを使用する。 バートベース多言語ケース スペイン語のテキストを処理する。
# vocab.txtを得るために事前に訓練されたWordPieceトークナイザーを保存する。
tokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
tokenizer.save_pretrained(DATA_DIR)
を使用する。 build_pretraining_dataset.py を使って、生テキストのダンプから事前学習データセットを作成する。
!python3 electra/build_pretraining_dataset.py ㊟ -コーパスディレクトリ $DATA_DIR
--corpus-dir $DATA_DIR \
--vocab-file $DATA_DIR/vocab.txt \
--output-dir $DATA_DIR/pretrain_tfrecords ˶ -max-seq length 128
--最大seq-length 128
-blanks-separate-docsはFalseです。
--num-process 5
--num-processes 5
トレーニング開始
を使用する。 run_pretraining.py ELECTRAモデルを事前に訓練する。
小さなELECTRAモデルを100万ステップ学習させるには、以下を実行します:
python3 run_pretraining.py --data-dir $DATA_DIR --model-name electra_small
Tesla V100 GPUで4日強かかります。しかし、モデルは200kステップ(v100 GPUで10時間のトレーニング)後に適切な結果を達成するはずです。
トレーニングをカスタマイズするには .json ファイルにはハイパーパラメータが含まれている。参照 configure_pretraining.py すべてのハイパーパラメータのデフォルト値。
以下では、ハイパーパラメータを設定して、100ステップだけモデルを訓練する。
hparams = {
"do_train":"true"、
「do_eval":"false"、
"model_size":"small"、
do_lower_case": "false":"false"、
"vocab_size":119547,
「num_train_steps":100,
"save_checkpoints_steps":100,
「train_batch_size":32,
}
with open("hparams.json", "w") as f:
json.dump(hparams, f)
トレーニングを始めよう
--data-dir $DATA_DIR ☑ -モデル名
--モデル名 $MODEL_NAME
--hparams "hparams.json"
仮想マシン上でトレーニングする場合は、ターミナル上で以下の行を実行し、TensorBoardでのトレーニングプロセスを監視する。
pip install -U tensorboard
tensorboard dev upload --logdir data/models/electra-spanish
これは テンソルボード V100 GPUを使用し、4日間で100万ステップのELECTRA-smallをトレーニング。
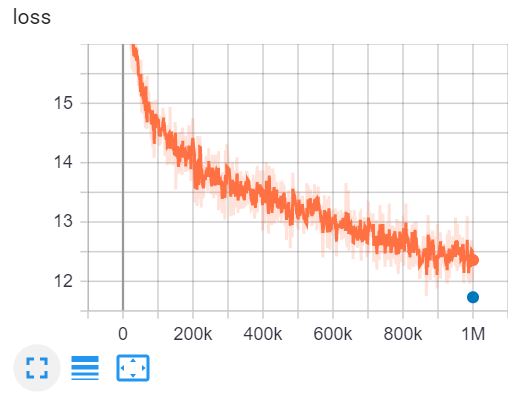 {: .align-center}
{: .align-center}
4.TensorflowのチェックポイントをPyTorch形式に変換する。
ハグする顔 道具 を使ってTensorflowのチェックポイントをPyTorchに変換することができます。しかし、このツールはまだELECTRA用にアップデートされていない。幸いなことに、@lonePatientによるGitHubのレポを見つけた。
git clone https://github.com/lonePatient/electra_pytorch.git
MODEL_DIR = "data/models/electra-spanish/"
コンフィグ = {
"vocab_size":119547,
"embedding_size":128,
「hidden_size": 256256,
「num_hidden_layers":12,
「num_attention_heads":4,
"intermediate_size":1024,
"generator_size":"0.25",
"hidden_act":"gelu"、
"hidden_dropout_prob":0.1,
"attention_probs_dropout_prob":0.1,
"max_position_embeddings":512,
「type_vocab_size": 1:2,
"initializer_range":0.02
}
with open(MODEL_DIR + "config.json", "w") as f:
json.dump(config, f)
!python electra_pytorch/convert_electra_tf_checkpoint_to_pytorch.py ㊟ --tf_checkpoint_path=$MODEL_IR
--tf_checkpoint_path=$MODEL_DIR ୧-͈ᴗ-͈)
-tf_checkpoint_path=$MODEL_DIR
--pytorch_dump_path=$MODEL_DIR/pytorch_model.bin
ELECTRAを使用する 変圧器
モデルのチェックポイントをPyTorch形式に変換した後、学習済みのELECTRAモデルを下流のタスクで使用するために 変圧器 図書館
インポートトーチ
from transformers import ElectraForPreTraining, ElectraTokenizerFast
discriminator = ElectraForPreTraining.from_pretrained(MODEL_DIR)
tokenizer = ElectraTokenizerFast.from_pretrained(DATA_DIR, do_lower_case=False)
sentence = "Los pájaros están cantando" # 鳥が歌っている
fake_sentence = "Los pájaros están hablando" # 鳥が話している。
fake_tokens = tokenizer.tokenize(fake_sentence, add_special_tokens=True)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
discriminator_outputs = discriminator(fake_inputs)
予測値 = discriminator_outputs[0] > 0
[print("%7s "%トークン, end="") for token in fake_tokens].
print("%7s" % token end="")
[print("%7s" % int(prediction), end="") for prediction in predictions.tolist()];
[CLS] ##arosは##ndo [SEP]を話しています。
1 0 0 0 0 0 0 0
私たちのモデルは100ステップしか学習していないため、予測は正確ではありません。完全に訓練されたスペイン語のELECTRA-smallは以下のように読み込むことができます:
識別器 = ElectraForPreTraining.from_pretrained("skimai/electra-small-spanish")
tokenizer = ElectraTokenizerFast.from_pretrained("skimai/electra-small-spanish", do_lower_case=False)
5.結論
この記事では、ELECTRAの論文を通して、なぜELECTRAが現時点で最も効率的な変換器の事前学習アプローチなのかを理解しました。小規模の場合、ELECTRA-smallは1つのGPUで4日間学習させることができ、GLUEベンチマークにおいてGPTを上回ります。大規模では、ELECTRA-largeがSQuAD 2.0の新たな最先端を打ち立てます。
次に、実際にスペイン語のテキストでELECTRAモデルを学習し、TensorflowのチェックポイントをPyTorchに変換し、モデルを 変圧器 図書館
参考文献
- [1] ELECTRA:テキスト・エンコーダを生成器ではなく識別器として事前学習させる
- [2] グーグル-リサーチ/エレクトラ - 原著論文の公式GitHubリポジトリ
- [3] エレクトラ・パイトーチ - ELECTRAのPyTorch実装


