
Verschiedene Arten des maschinellen Lernens



Verschiedene Arten des maschinellen Lernens
Maschinelles Lernen ist ein sich schnell entwickelnder Bereich, der das Potenzial hat, viele Branchen zu verändern, vom Gesundheitswesen über das Finanzwesen bis hin zur Fertigung. Im Mittelpunkt des maschinellen Lernens stehen vier Hauptarten von Lerntechniken: Überwachtes Lernen, unüberwachtes Lernen, halb-überwachtes Lernen, und Verstärkungslernen.
Jeder dieser Ansätze hat seine eigenen Stärken und Schwächen, und das Verständnis ihrer Funktionsweise ist entscheidend für die erfolgreiche Umsetzung von Lösungen der künstlichen Intelligenz (KI).
*Bevor Sie in diesen Blog über maschinelles Lernen eintauchen, sollten Sie sich unseren Artikel über KI vs. ML ansehen, um den Unterschied zwischen den beiden zu erfahren.
Überwachtes Lernen

Überwachtes Lernen ist eine Art des maschinellen Lernens, bei dem der Algorithmus auf einem markierten Datensatz trainiert wird. Das bedeutet, dass die Eingabedaten bereits von Menschen klassifiziert oder gekennzeichnet wurden, und der Algorithmus lernt, auf der Grundlage dieser gekennzeichneten Daten Vorhersagen zu treffen. Beim überwachten Lernen erhält der Algorithmus sowohl die Eingabedaten als auch die entsprechenden Ausgabedaten und nutzt diese Informationen, um eine Zuordnungsfunktion zwischen den beiden zu lernen.
Eine der häufigsten Anwendungen des überwachten Lernens ist die Klassifizierung. Bei der Klassifizierung wird der Algorithmus darauf trainiert, vorherzusagen, zu welcher Kategorie ein Eingabedatenpunkt gehört. Ein Algorithmus für überwachtes Lernen könnte zum Beispiel auf einem Datensatz mit Bildern von Katzen und Hunden trainiert werden, wobei jedes Bild entweder als "Katze" oder "Hund" gekennzeichnet ist. Einmal trainiert, kann der Algorithmus dann ein neues Bild aufnehmen und vorhersagen, ob es sich um eine Katze oder einen Hund handelt.
Eine weitere gängige Anwendung des überwachten Lernens ist die Regression. Bei der Regression wird der Algorithmus darauf trainiert, eine kontinuierliche numerische Ausgabe auf der Grundlage der Eingabedaten vorherzusagen. Ein Algorithmus für überwachtes Lernen könnte zum Beispiel auf einem Datensatz mit Hauspreisen trainiert werden, wobei jeder Datenpunkt Informationen wie die Größe des Hauses, die Anzahl der Schlafzimmer und den Standort enthält. Der Algorithmus würde dann lernen, den Preis für ein neues Haus auf der Grundlage dieser Merkmale vorherzusagen.
Unüberwachtes Lernen

Unüberwachtes Lernen ist eine weitere gängige Form des maschinellen Lernens, bei der der Algorithmus im Gegensatz zum überwachten Lernen auf einem unmarkierten Datensatz trainiert wird. Beim unüberwachten Lernen erhält der Algorithmus keine Informationen über die Ausgabe oder die Bezeichnungen der Eingabedaten. Stattdessen lernt er, selbständig Muster und Strukturen in den Daten zu erkennen.
Eine der häufigsten Anwendungen des unüberwachten Lernens ist das Clustering. Clustering-Algorithmen fassen ähnliche Datenpunkte auf der Grundlage ihrer Merkmale zusammen, ohne dass die Datenbeschriftungen vorher bekannt sind. Dies kann für Aufgaben wie die Kundensegmentierung nützlich sein, bei der ein Unternehmen Kunden auf der Grundlage ihrer Kaufgewohnheiten oder anderer Verhaltensweisen gruppieren möchte.
Eine weitere Anwendung des unüberwachten Lernens ist die Dimensionalitätsreduktion. Algorithmen zur Dimensionalitätsreduzierung werden eingesetzt, um die Anzahl der Merkmale in einem Datensatz zu verringern und dabei so viel wie möglich von den ursprünglichen Informationen beizubehalten. Dies kann für Aufgaben wie Bild- und Spracherkennung nützlich sein, bei denen die Eingabedaten hochdimensional und schwer zu verarbeiten sein können.
Semi-überwachtes Lernen

Beim halbüberwachten Lernen handelt es sich um eine Kombination aus überwachten und nicht überwachten Lerntechniken. Der Algorithmus wird auf einem Datensatz trainiert, der sowohl gelabelte als auch nicht gelabelte Daten enthält.
Die gekennzeichneten Daten werden verwendet, um den Algorithmus auf überwachte Weise zu trainieren, während die nicht gekennzeichneten Daten dem Algorithmus helfen, mehr über die zugrunde liegende Struktur der Daten zu erfahren. Die Idee hinter dem halbüberwachten Lernen ist, dass die nicht gekennzeichneten Daten verwendet werden können, um die Genauigkeit und Generalisierungsfähigkeit des Algorithmus zu verbessern.
Semi-überwachtes Lernen wird häufig in der natürlichen Sprachverarbeitung (NLP) eingesetzt, einem Bereich der Informatik und der künstlichen Intelligenz, der sich darauf konzentriert, Maschinen in die Lage zu versetzen, geschriebene und gesprochene Sprache ähnlich wie Menschen zu verstehen. Sprachmodelle werden in der Regel auf großen Mengen unbeschrifteter Textdaten trainiert, die zur Verbesserung der Genauigkeit von Aufgaben wie Textklassifizierung und Sprachübersetzung verwendet werden können.
Semi-überwachtes Lernen kann auch für Aufgaben wie Bild- und Spracherkennung verwendet werden, bei denen die Menge der gekennzeichneten Daten begrenzt oder teuer ist. Indem der Algorithmus die verfügbaren unmarkierten Daten nutzt, kann er seine Leistung für die jeweilige Aufgabe verbessern.
Reinforcement Learning
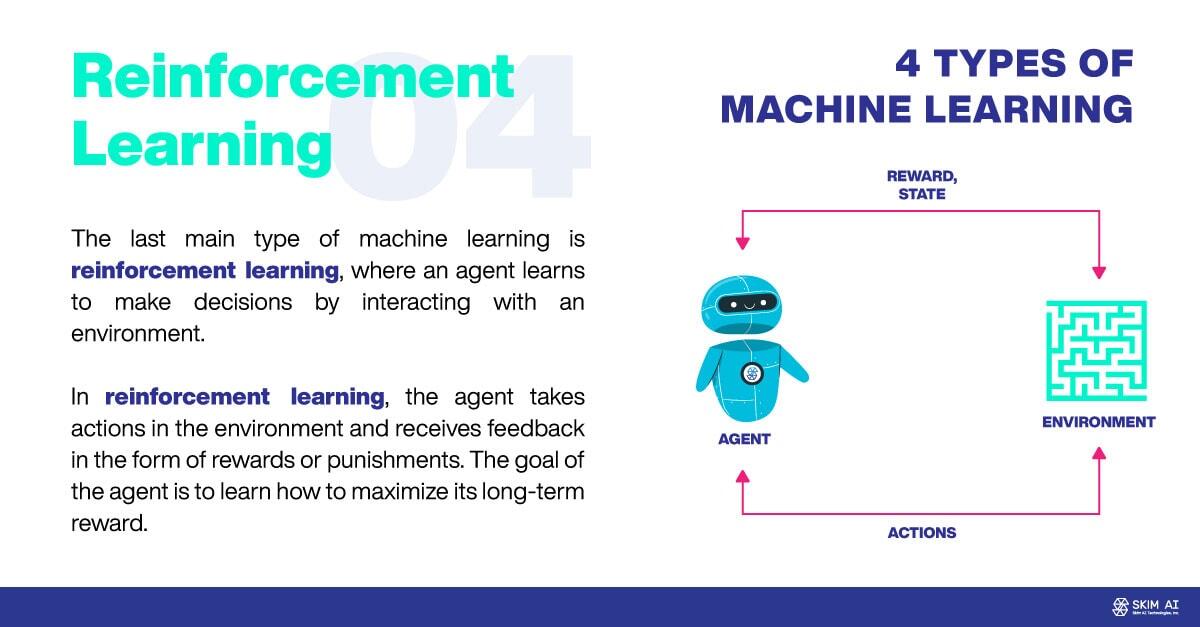
Die letzte Hauptart des maschinellen Lernens ist das Verstärkungslernen, bei dem ein Agent durch Interaktion mit einer Umgebung lernt, Entscheidungen zu treffen. Beim Verstärkungslernen führt der Agent Aktionen in der Umgebung durch und erhält Rückmeldungen in Form von Belohnungen oder Bestrafungen. Das Ziel des Agenten ist es, zu lernen, wie er seine langfristige Belohnung maximieren kann.
Die wichtigsten Anwendungen des verstärkenden Lernens finden sich im Bereich der Robotik, wo ein Agent lernen kann, einen physischen Roboter zu steuern, um eine Aufgabe zu erfüllen. Der Agent führt Aktionen in der Umgebung aus, wie z. B. das Bewegen der Arme oder Beine des Roboters, und erhält eine Rückmeldung in Form einer Belohnung oder Strafe, je nachdem, wie gut er die Aufgabe erfüllt.
Verstärkungslernen kann auch für Spiele und Simulationen verwendet werden, bei denen ein Agent lernen kann, ein Spiel zu spielen oder in einer virtuellen Umgebung zu navigieren. Verstärkungslernen wurde beispielsweise eingesetzt, um Agenten für Videospiele wie Atari-Spiele und das Spiel Go zu trainieren.
Ein weiterer Bereich, in dem sich das Reinforcement Learning als vielversprechend erwiesen hat, ist das Gesundheitswesen, wo es zur Optimierung von Behandlungen für verschiedene Krankheiten eingesetzt werden kann. Der Agent kann lernen, Behandlungsentscheidungen auf der Grundlage von Patientendaten zu treffen und Rückmeldungen in Form von Patientenergebnissen zu erhalten.
Industrien im Wandel
Maschinelles Lernen ist ein sich schnell entwickelnder Bereich, der das Potenzial hat, nahezu jede Branche zu verändern und einige unserer komplexesten Probleme zu lösen. Das Verständnis der verschiedenen Arten des maschinellen Lernens, wie überwachtes, unüberwachtes, halbüberwachtes und verstärkendes Lernen, ermöglicht es uns, weiterhin Grenzen zu verschieben und unsere datengesteuerte Welt zu beeinflussen.


