Tutorial: Como pré-treinar a ELECTRA para espanhol a partir do zero



Tutorial: Como pré-treinar a ELECTRA para espanhol a partir do zero
Originalmente publicado por Chris Tran, investigador de aprendizagem automática da Skim AI.![]()
Introdução
Este artigo descreve como pré-treinar o ELECTRA, outro membro da família de métodos de pré-treino do Transformer, para espanhol, de modo a obter resultados de ponta em benchmarks de Processamento de Linguagem Natural. É a Parte III de uma série sobre o treino de modelos linguísticos personalizados do BERT para espanhol para uma variedade de casos de utilização:
- Parte I: Como treinar um modelo linguístico RoBERTa para espanhol a partir do zero
- Parte II: Como treinar um modelo de língua espanhola SpanBERTa para reconhecimento de entidades nomeadas (NER)
1. Introdução
No ICLR 2020, ELECTRA: Pré-treino de codificadores de texto como discriminadores em vez de geradoresO ELECTRA é mais um membro da família de métodos de pré-treino do Transformer, cujos membros anteriores, como o BERT, o GPT-2 e o RoBERTa, obtiveram muitos resultados de ponta em benchmarks de processamento de linguagem natural. O ELECTRA é mais um membro da família de métodos de pré-treino Transformer, cujos membros anteriores, como o BERT, o GPT-2 e o RoBERTa, obtiveram muitos resultados de ponta em benchmarks de Processamento de Linguagem Natural.
Ao contrário de outros métodos de modelação de linguagem mascarada, a ELECTRA é uma tarefa de pré-treino mais eficiente em termos de amostras, designada por deteção de tokens substituídos. Em pequena escala, o ELECTRA-small pode ser treinado numa única GPU durante 4 dias para superar o GPT (Radford et al., 2018) (treinado usando 30x mais computação) no benchmark GLUE. Em grande escala, o ELECTRA-large tem um desempenho superior ao ALBERT (Lan et al., 2019) no GLUE e estabelece um novo estado da arte para o SQuAD 2.0.

A ELECTRA supera consistentemente as abordagens de pré-treino de modelos de linguagem mascarados.
{.text-center}
2. Método
Métodos de pré-treino de modelação da linguagem mascarada, tais como BERT (Devlin et al., 2019) corrompe a entrada, substituindo alguns tokens (normalmente 15% da entrada) por [MÁSCARA] e depois treinar um modelo para reconstruir os tokens originais.
Em vez de mascarar, a ELECTRA corrompe a entrada substituindo alguns tokens por amostras das saídas de um modelo de linguagem mascarado reduzido. Em seguida, um modelo discriminativo é treinado para prever se cada token é um original ou uma substituição. Após o pré-treino, o gerador é deitado fora e o discriminador é afinado em tarefas a jusante.
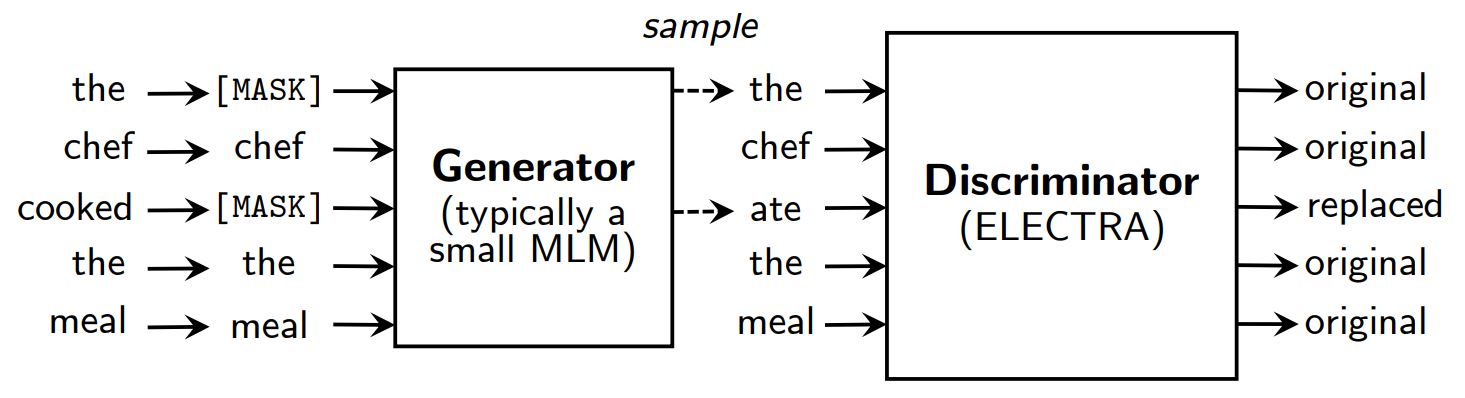
Uma visão geral da ELECTRA.
{.text-center}
Embora tenha um gerador e um discriminador como o GAN, o ELECTRA não é contraditório, na medida em que o gerador que produz tokens corrompidos é treinado com a máxima probabilidade em vez de ser treinado para enganar o discriminador.
Porque é que a ELECTRA é tão eficiente?
Com um novo objetivo de formação, a ELECTRA pode atingir um desempenho comparável ao de modelos fortes como RoBERTa (Liu et al., (2019) que tem mais parâmetros e necessita de 4x mais computação para o treino. No documento, foi efectuada uma análise para compreender o que realmente contribui para a eficiência da ELECTRA. As principais conclusões são:
- A ELECTRA beneficia muito do facto de ter uma perda definida sobre todos os tokens de entrada em vez de apenas um subconjunto. Mais especificamente, na ELECTRA, o discriminador prevê todos os tokens da entrada, enquanto que no BERT, o gerador prevê apenas os tokens mascarados 15% da entrada.
- O desempenho do BERT é ligeiramente prejudicado porque, na fase de pré-treino, o modelo vê
[MÁSCARA]enquanto que na fase de afinação não é esse o caso.
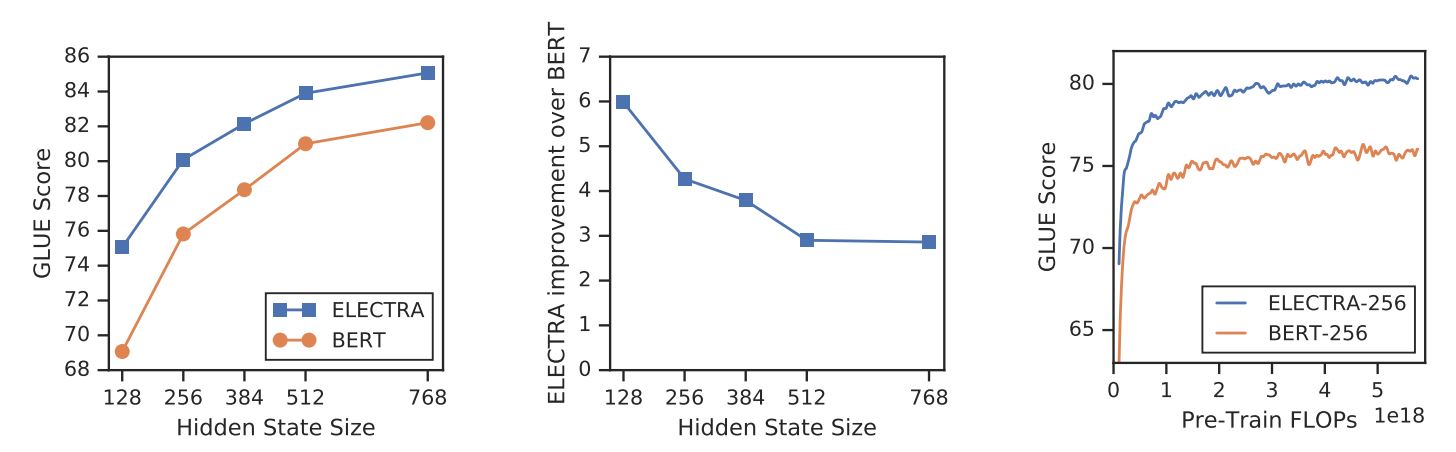
ELECTRA vs. BERT
{.text-center}
3. Pré-treino da ELECTRA
Nesta secção, vamos treinar a ELECTRA de raiz com o TensorFlow utilizando scripts fornecidos pelos autores da ELECTRA em google-research/electra. Em seguida, converteremos o modelo para o ponto de controlo do PyTorch, que pode ser facilmente afinado em tarefas a jusante utilizando a função Hugging Face transformadores biblioteca.
Configuração
!pip install tensorflow==1.15
!pip install transformers==2.8.0
!git clone https://github.com/google-research/electra.git
importar os
importar json
from transformers import AutoTokenizer
Dados
Iremos pré-treinar o ELECTRA num conjunto de dados de legendas de filmes espanhóis obtidos a partir do OpenSubtitles. Este conjunto de dados tem um tamanho de 5,4 GB e treinaremos num pequeno subconjunto de ~30 MB para apresentação.
DATA_DIR = "./data" #@param {type: "string"}
TRAIN_SIZE = 1000000 #@param {type: "integer"}
MODEL_NAME = "electra-espanhol" #@param {type: "string"}
# Descarregar e descomprimir o conjunto de dados de legendas de filmes espanhóis
if not os.path.exists(DATA_DIR):
!mkdir -p $DATA_DIR
!wget "https://object.pouta.csc.fi/OPUS-OpenSubtitles/v2016/mono/es.txt.gz" -O $DATA_DIR/OpenSubtitles.txt.gz
!gzip -d $DATA_DIR/OpenSubtitles.txt.gz
!head -n $TRAIN_SIZE $DATA_DIR/OpenSubtitles.txt > $DATA_DIR/train_data.txt
!rm $DATA_DIR/OpenSubtitles.txt
Antes de construir o conjunto de dados de pré-treino, devemos certificar-nos de que o corpus tem o seguinte formato:
- cada linha é uma frase
- uma linha em branco separa dois documentos
Criar conjunto de dados de pré-treino
Utilizaremos o tokenizador de bert-base-multilingual-cased para processar textos em espanhol.
# Salve o tokenizador WordPiece pré-treinado para obter vocab.txt
tokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
tokenizer.save_pretrained(DATA_DIR)
Utilizamos construir_conjunto_de_dados_de_treino.py para criar um conjunto de dados de pré-treino a partir de um despejo de texto em bruto.
!python3 electra/build_pretraining_dataset.py \
--corpus-dir $DATA_DIR \
--vocab-file $DATA_DIR/vocab.txt \
--output-dir $DATA_DIR/pretrain_tfrecords \
--max-seq-length 128 \
--blanks-separate-docs False \
--no-lower-case \
--num-processos 5
Iniciar a formação
Utilizamos executar_treinamento.py para pré-treinar um modelo ELECTRA.
Para treinar um pequeno modelo ELECTRA para 1 milhão de passos, execute:
python3 run_pretraining.py --data-dir $DATA_DIR --model-name electra_small
Isso leva um pouco mais de 4 dias em uma GPU Tesla V100. No entanto, o modelo deve obter resultados decentes após 200 mil passos (10 horas de treino no GPU v100).
Para personalizar a formação, crie um .json que contém os hiperparâmetros. Consulte configure_pretraining.py para os valores por defeito de todos os hiperparâmetros.
Abaixo, definimos os hiperparâmetros para treinar o modelo para apenas 100 passos.
hparams = {
"do_train": "true" (verdadeiro),
"do_eval": "false",
"model_size": "small",
"do_lower_case": "false",
"vocab_size": 119547,
"num_train_steps": 100,
"save_checkpoints_steps": 100,
"train_batch_size": 32,
}
com open("hparams.json", "w") as f:
json.dump(hparams, f)
Vamos começar a treinar:
!python3 electra/run_pretraining.py \
--data-dir $DATA_DIR \
--model-name $MODEL_NAME \
--hparams "hparams.json"
Se estiver a treinar numa máquina virtual, execute as seguintes linhas no terminal para monitorizar o processo de treino com o TensorBoard.
pip install -U tensorboard
tensorboard dev upload --logdir data/models/electra-spanish
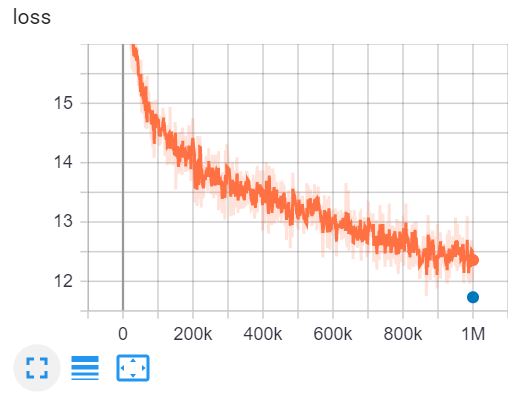
Este é o TensorBoard de treino do ELECTRA-small para 1 milhão de passos em 4 dias numa GPU V100.
 {.align-center}
{.align-center}
4. Converter os pontos de controlo do Tensorflow para o formato PyTorch
A cara de abraço tem uma ferramenta para converter os pontos de controlo do Tensorflow em PyTorch. No entanto, essa ferramenta ainda não foi atualizada para o ELECTRA. Felizmente, eu encontrei um repositório no GitHub feito por @lonePatient que pode nos ajudar com essa tarefa.
!git clone https://github.com/lonePatient/electra_pytorch.git
MODEL_DIR = "data/models/electra-spanish/"
config = {
"vocab_size": 119547,
"embedding_size": 128,
"hidden_size": 256,
"num_hidden_layers": 12,
"num_attention_heads": 4,
"tamanho_intermédio": 1024,
"generator_size":"0.25",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"attention_probs_dropout_prob": 0.1,
"max_position_embeddings": 512,
"type_vocab_size": 2,
"initializer_range": 0.02
}
com open(MODEL_DIR + "config.json", "w") as f:
json.dump(config, f)
!python electra_pytorch/convert_electra_tf_checkpoint_to_pytorch.py \
--tf_checkpoint_path=$MODEL_DIR \
--electra_config_file=$MODEL_DIR/config.json \
--pytorch_dump_path=$MODEL_DIR/pytorch_model.bin
Utilizar ELECTRA com transformadores
Depois de converter o ponto de controlo do modelo para o formato PyTorch, podemos começar a utilizar o nosso modelo ELECTRA pré-treinado em tarefas a jusante com o transformadores biblioteca.
importar torch
from transformers import ElectraForPreTraining, ElectraTokenizerFast
discriminator = ElectraForPreTraining.from_pretrained(MODEL_DIR)
tokenizer = ElectraTokenizerFast.from_pretrained(DATA_DIR, do_lower_case=False)
frase = "Los pájaros están cantando" # Os pássaros estão a cantar
falsa_sentença = "Los pájaros están hablando" # Os pássaros estão a falar
fake_tokens = tokenizer.tokenize(fake_sentence, add_special_tokens=True)
entradas_falsas = tokenizer.encode(frase_falsa, return_tensors="pt")
discriminator_outputs = discriminator(fake_inputs)
previsões = discriminator_outputs[0] > 0
[print("%7s" % token, end="") for token in fake_tokens]
print("\n")
[print("%7s" % int(prediction), end="") for prediction in predictions.tolist()];
[CLS] Os paj ##aros estão a falar ##ndo [SEP]
1 0 0 0 0 0 0 0
O nosso modelo foi treinado para apenas 100 passos, pelo que as previsões não são exactas. O modelo ELECTRA-small totalmente treinado para o espanhol pode ser carregado da seguinte forma:
discriminator = ElectraForPreTraining.from_pretrained("skimai/electra-small-spanish")
tokenizer = ElectraTokenizerFast.from_pretrained("skimai/electra-small-spanish", do_lower_case=False)
5. Conclusão
Neste artigo, percorremos o documento ELECTRA para entender por que o ELECTRA é a abordagem de pré-treinamento de transformadores mais eficiente no momento. Em pequena escala, o ELECTRA-small pode ser treinado em uma GPU por 4 dias para superar o GPT no benchmark GLUE. Em grande escala, o ELECTRA-grande estabelece um novo estado da arte para o SQuAD 2.0.
Em seguida, treinamos um modelo ELECTRA em textos espanhóis e convertemos o ponto de controlo do Tensorflow para PyTorch e utilizamos o modelo com o transformadores biblioteca.
Referências
- [1] ELECTRA: Pré-treino de codificadores de texto como discriminadores em vez de geradores
- [2] google-research/electra - o repositório oficial GitHub do documento original
- [3] electra_pytorch - uma implementação PyTorch da ELECTRA