
We need to rethink chain-of-thought (CoT) prompting AI&YOU #68



Estatísticas da semana: Zero-shot CoT performance was only 5.55% for GPT-4-Turbo, 8.51% for Claude-3-Opus, and 4.44% for GPT-4. (“Chain of Thoughtlessness?” paper)
Chain-of-Thought (CoT) prompting has been hailed as a breakthrough in unlocking the reasoning capabilities of large language models (LLMs). However, recent research has challenged these claims and prompted us to revisit the technique.
Na edição desta semana de AI&YOU, exploramos as ideias de três blogues que publicámos sobre o tema:
We need to rethink chain-of-thought (CoT) prompting AI&YOU #68
LLMs demonstrate remarkable capabilities in natural language processing (NLP) and generation. However, when faced with complex reasoning tasks, these models can struggle to produce accurate and reliable results. This is where Chain-of-Thought (CoT) prompting comes into play, a technique that aims to enhance the problem-solving abilities of LLMs.
An advanced engenharia rápida technique, it is designed to guide LLMs through a step-by-step reasoning process. Unlike standard prompting methods that aim for direct answers, CoT prompting encourages the model to generate intermediate reasoning steps before arriving at a final answer.
At its core, CoT prompting involves structuring input prompts in a way that elicits a logical sequence of thoughts from the model. By breaking down complex problems into smaller, manageable steps, CoT attempts to enable LLMs to navigate through intricate reasoning paths more effectively.
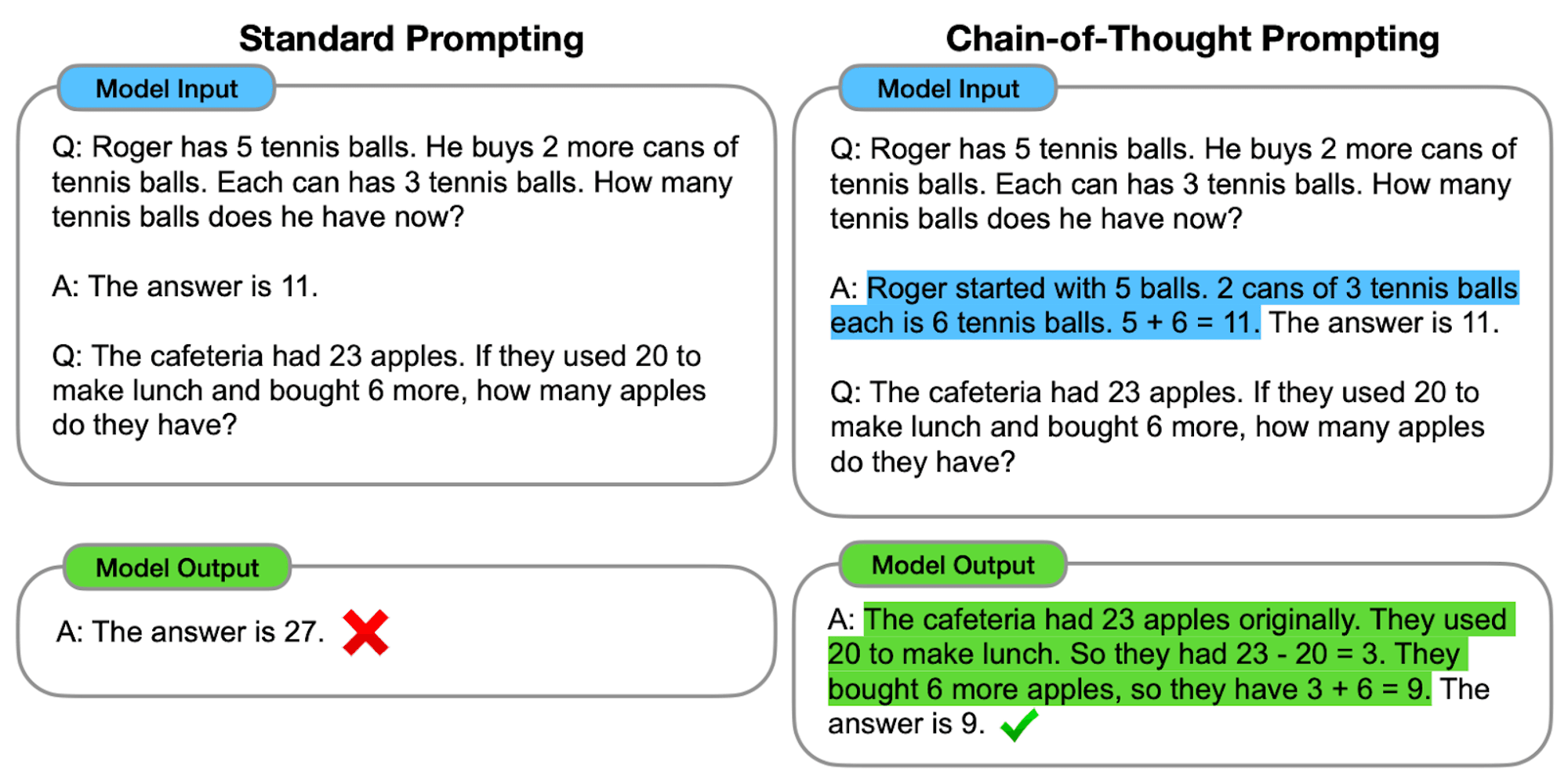
Como funciona o CoT
Na sua essência, a solicitação de CoT orienta os modelos linguísticos através de uma série de passos de raciocínio intermédios antes de chegar a uma resposta final. Este processo envolve normalmente:
Decomposição de problemas: A tarefa complexa é dividida em etapas mais pequenas e fáceis de gerir.
Raciocínio passo a passo: O modelo é convidado a refletir explicitamente sobre cada etapa.
Progressão lógica: Cada passo baseia-se no anterior, criando uma cadeia de pensamentos.
Desenho de conclusão: A resposta final é obtida a partir das etapas de raciocínio acumuladas.
Tipos de CoT Prompting
O estímulo da cadeia de pensamento pode ser implementado de várias formas, destacando-se dois tipos principais:
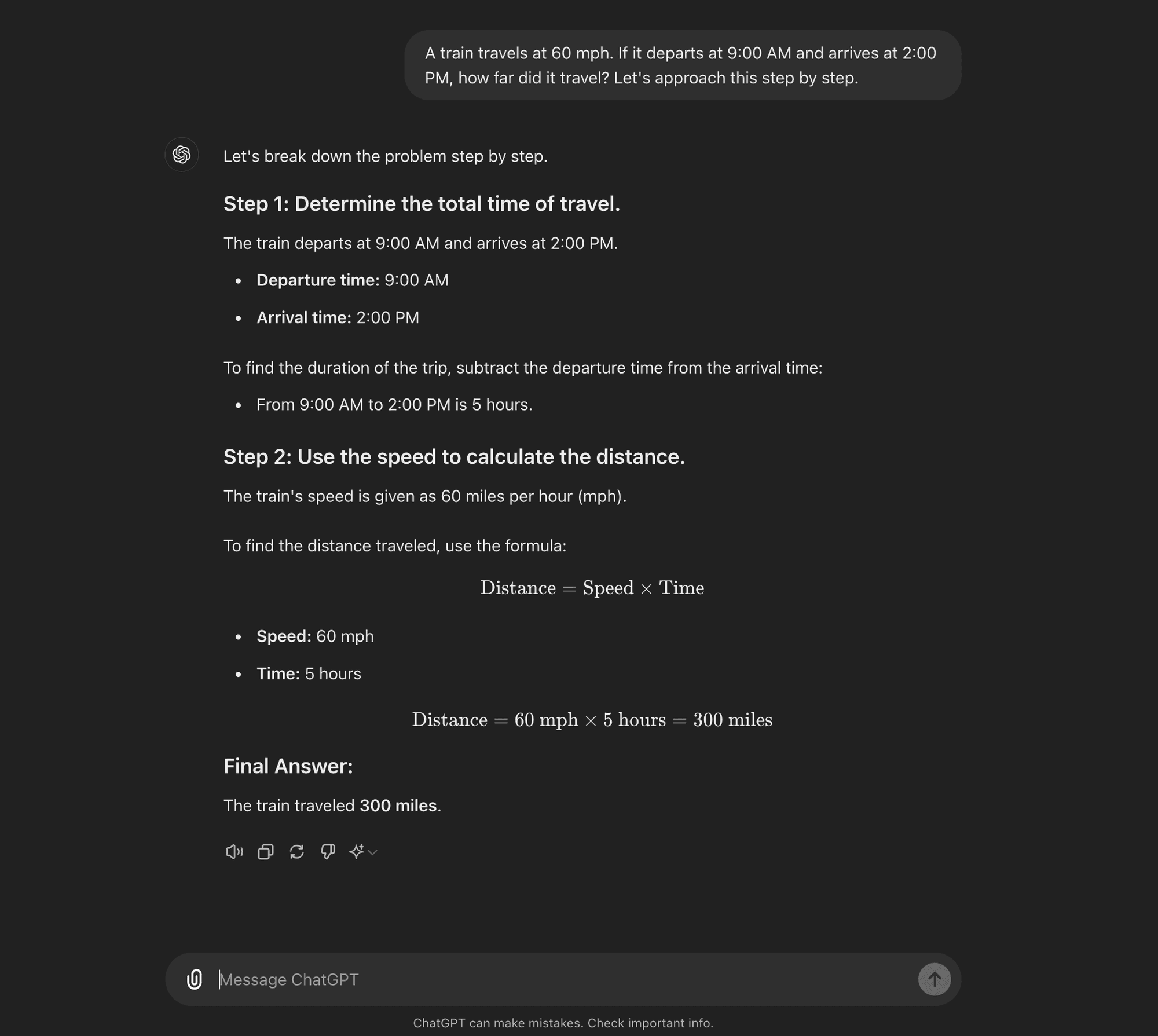
Zero-shot CoT: Zero-shot CoT doesn’t require task-specific examples. Instead, it uses a simple prompt like “Let’s approach this step by step” to encourage the model to break down its reasoning process.****
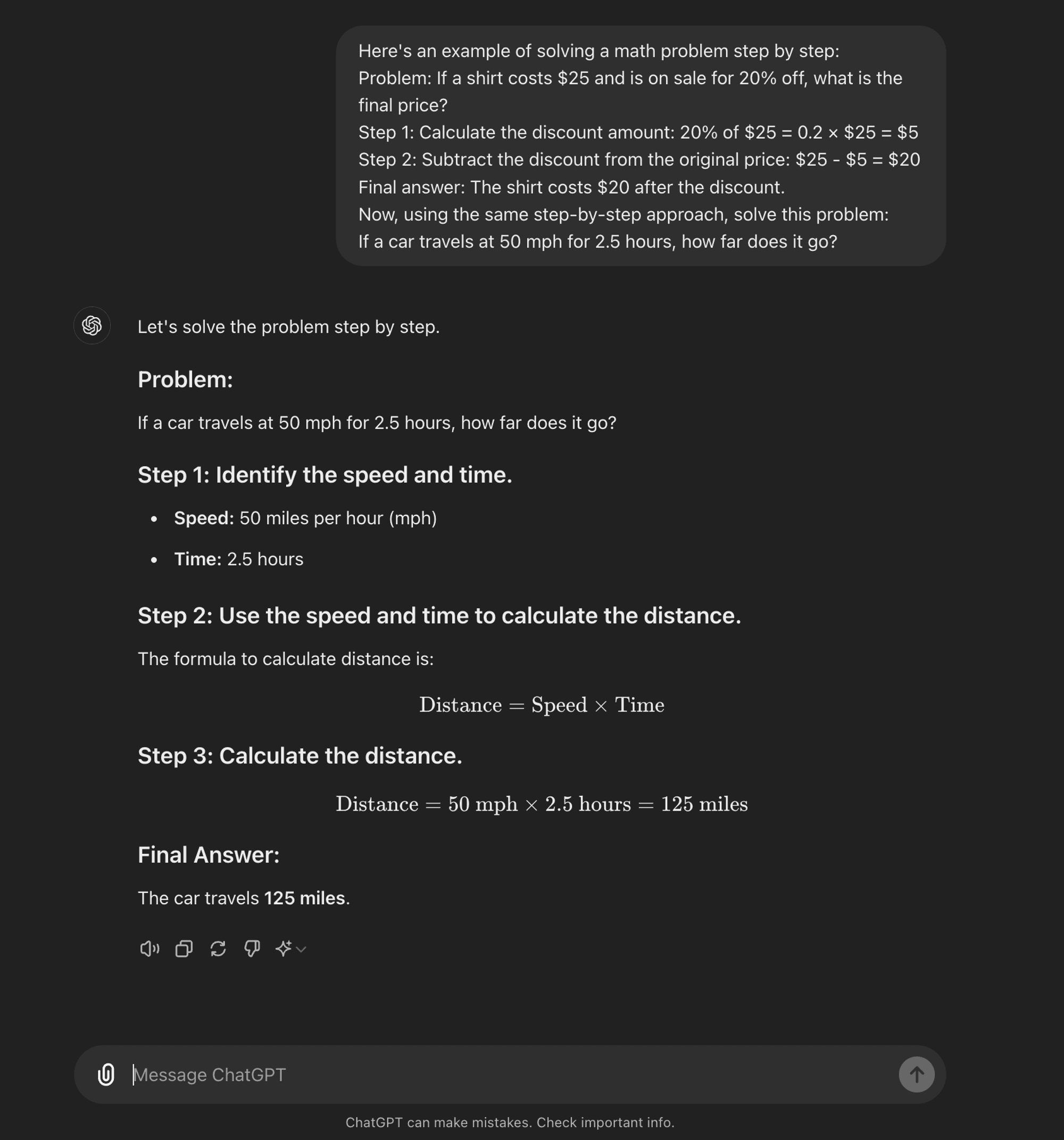
Few-shot CoT: A CoT de poucas oportunidades envolve fornecer ao modelo um pequeno número de exemplos que demonstram o processo de raciocínio desejado. Estes exemplos servem de modelo para o modelo seguir quando estiver a lidar com problemas novos e inéditos.
Zero-shot CoT
Few-shot CoT
AI Research Paper Breakdown: “Chain of Thoughtlessness?”
Now that you know what CoT prompting is, we can dive into some recent research that challenges some of its benefits and offers some insight into when it is actually useful.
The research paper, titled “Chain of Thoughtlessness? An Analysis of CoT in Planning,” provides a critical examination of CoT prompting’s effectiveness and generalizability. As AI practitioners, it’s crucial to understand these findings and their implications for developing AI applications that require sophisticated reasoning capabilities.

Os investigadores escolheram um domínio de planeamento clássico chamado Blocksworld como principal campo de ensaio. No Blocksworld, a tarefa é reorganizar um conjunto de blocos de uma configuração inicial para uma configuração de objetivo, utilizando uma série de acções de movimento. Este domínio é ideal para testar as capacidades de raciocínio e planeamento porque:
Permite a criação de problemas de complexidade variável
Tem soluções claras e verificáveis por algoritmos
É pouco provável que esteja fortemente representado nos dados de formação do LLM
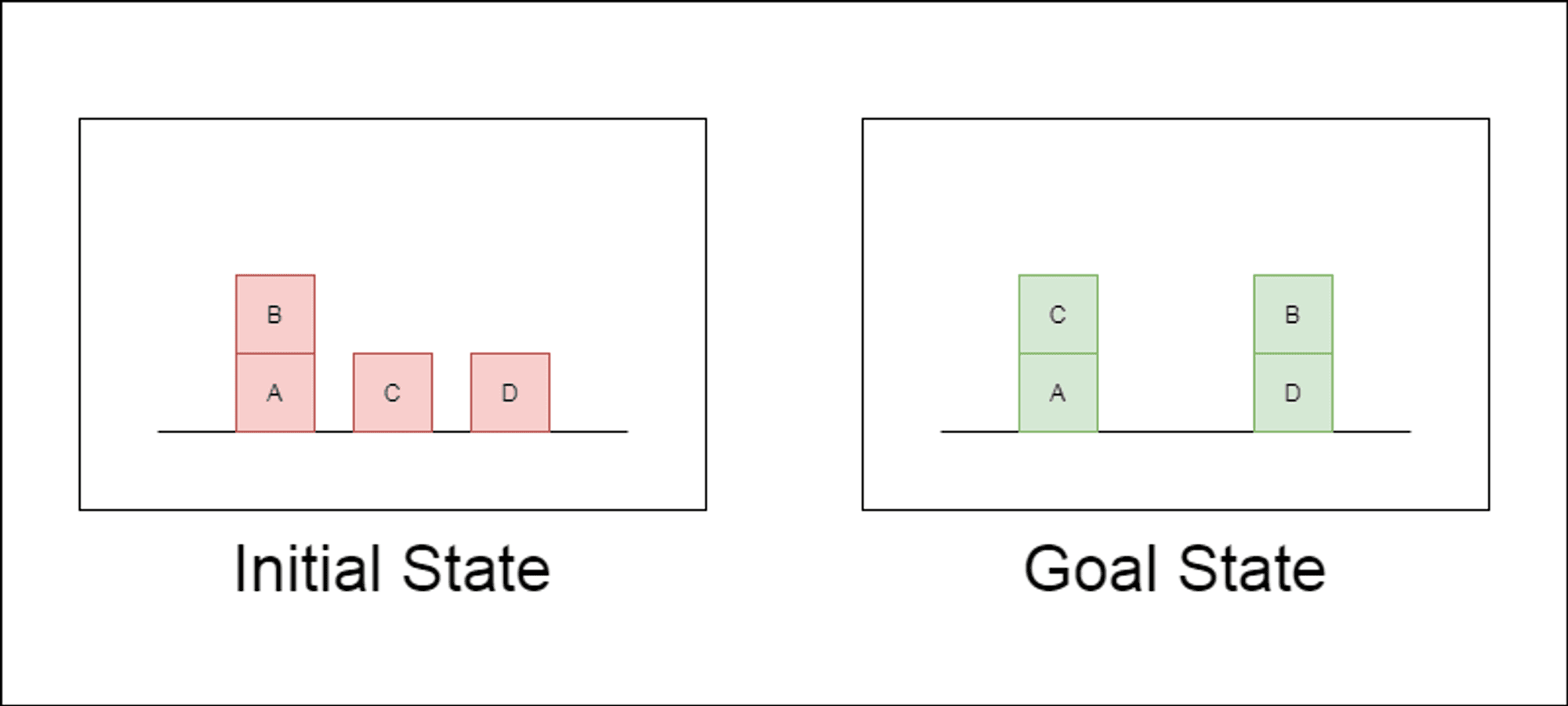
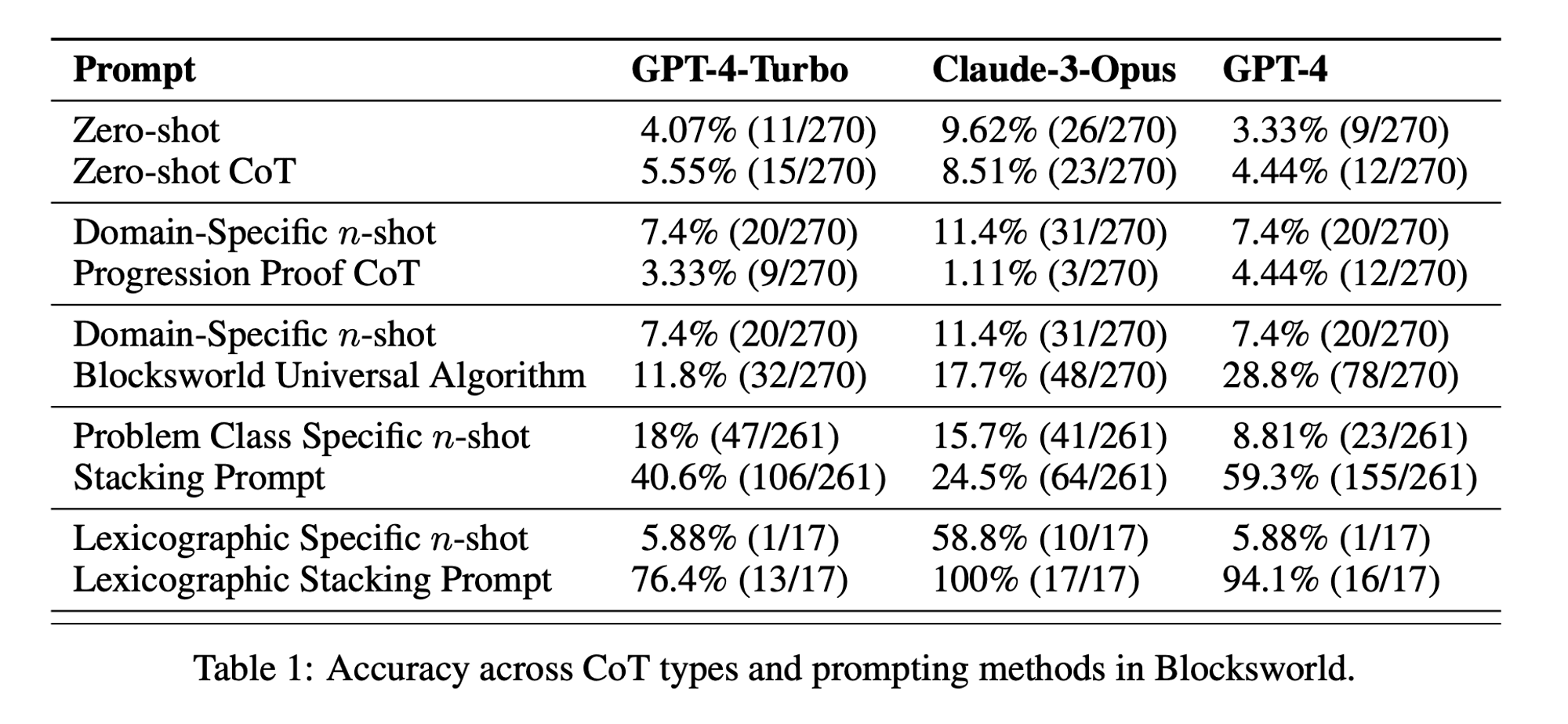
O estudo examinou três LLMs de última geração: GPT-4, Claude-3-Opus e GPT-4-Turbo. Estes modelos foram testados com mensagens de especificidade variável:
Cadeia de pensamento de tiro zero (Universal): Basta acrescentar "vamos pensar passo a passo" ao prompt.
Prova de progressão (específica da PDDL): Fornecer uma explicação geral da correção do plano com exemplos.
Algoritmo universal Blocksworld: Demonstração de um algoritmo geral para resolver qualquer problema Blocksworld.
Sugestão de empilhamento: Centrar-se numa subclasse específica de problemas Blocksworld (table-to-stack).
Empilhamento lexicográfico: Redução adicional a uma forma sintáctica específica do estado do objetivo.
Ao testar estas sugestões em problemas de complexidade crescente, os investigadores pretendiam avaliar até que ponto os LLMs conseguiam generalizar o raciocínio demonstrado nos exemplos.
Principais conclusões reveladas
Os resultados deste estudo desafiam muitos dos pressupostos prevalecentes sobre a solicitação de CoT:
Eficácia limitada do CoT: Contrariamente às afirmações anteriores, a solicitação CoT só apresentou melhorias significativas de desempenho quando os exemplos fornecidos eram extremamente semelhantes ao problema de consulta. Assim que os problemas se desviaram do formato exato apresentado nos exemplos, o desempenho caiu drasticamente.
Degradação rápida do desempenho: À medida que a complexidade dos problemas aumentava (medida pelo número de blocos envolvidos), a precisão de todos os modelos diminuía drasticamente, independentemente do estímulo de CoT utilizado. Este facto sugere que os LLM têm dificuldade em alargar o raciocínio demonstrado em exemplos simples a cenários mais complexos.
Ineficácia das instruções gerais: Surpreendentemente, as instruções de CoT mais gerais tiveram um desempenho pior do que as instruções normais sem quaisquer exemplos de raciocínio. Este facto contradiz a ideia de que a CoT ajuda os LLM a aprender estratégias generalizáveis de resolução de problemas.
Compensação da especificidade: O estudo concluiu que as instruções altamente específicas podem atingir uma elevada precisão, mas apenas num subconjunto muito restrito de problemas. Este facto evidencia um forte compromisso entre os ganhos de desempenho e a aplicabilidade da mensagem.
Falta de uma verdadeira aprendizagem algorítmica: Os resultados sugerem fortemente que os LLM não estão a aprender a aplicar procedimentos algorítmicos gerais a partir dos exemplos de CoT. Em vez disso, parecem basear-se na correspondência de padrões, que se desintegra rapidamente quando confrontados com problemas novos ou mais complexos.
Estas conclusões têm implicações significativas para os profissionais de IA e para as empresas que pretendem tirar partido das solicitações de CoT nas suas aplicações. Sugerem que, embora a CoT possa melhorar o desempenho em determinados cenários restritos, pode não ser a panaceia para tarefas de raciocínio complexas que muitos esperavam.
Implicações para o desenvolvimento da IA
As conclusões deste estudo têm implicações significativas para o desenvolvimento da IA, em particular para as empresas que trabalham em aplicações que exigem capacidades complexas de raciocínio ou planeamento:
Reavaliação da eficácia da CdT: AI developers should be cautious about relying on CoT for tasks that require true algorithmic thinking or generalization to novel scenarios.
Limitações dos actuais LLM: Alternative approaches may be necessary for applications requiring robust planning or multi-step problem-solving.
O custo da engenharia rápida: Embora os pedidos de CoT altamente específicos possam produzir bons resultados para conjuntos de problemas restritos, o esforço humano necessário para elaborar esses pedidos pode superar os benefícios, especialmente devido à sua limitada generalização.
Repensar as métricas de avaliação: Relying solely on static test sets may overestimate a model’s true reasoning capabilities.
O fosso entre a perceção e a realidade: Existe uma discrepância significativa entre a perceção das capacidades de raciocínio dos LLM (frequentemente antropomorfizadas no discurso popular) e as suas capacidades reais, tal como demonstrado neste estudo.
Recommendations for AI Practitioners:
Avaliação: Implement diverse testing frameworks to assess true generalization across problem complexities.
CoT Usage: Apply Chain-of-Thought prompting judiciously, recognizing its limitations in generalization.
Hybrid Solutions: Consider combining LLMs with traditional algorithms for complex reasoning tasks.
Transparency: Clearly communicate AI system limitations, especially for reasoning or planning tasks.
R&D Focus: Invest in research to enhance true reasoning capabilities of AI systems.
Afinação: Consider domain-specific fine-tuning, but be aware of potential generalization limits.
For AI practitioners and enterprises, these findings highlight the importance of combining LLM strengths with specialized reasoning approaches, investing in domain-specific solutions where necessary, and maintaining transparency about AI system limitations. As we move forward, the AI community must focus on developing new architectures and training methods that can bridge the gap between pattern matching and true algorithmic reasoning.
10 Best Prompting Techniques for LLMs
This week, we also explore ten of the most powerful and common prompting techniques, offering insights into their applications and best practices.

Well-designed prompts can significantly enhance an LLM’s performance, enabling more accurate, relevant, and creative outputs. Whether you’re a seasoned AI developer or just starting with LLMs, these techniques will help you unlock the full potential of AI models.
Make sure to check out the full blog to learn more about each one.
Obrigado por ler AI & YOU!
Para obter ainda mais conteúdos sobre IA empresarial, incluindo infográficos, estatísticas, guias de instruções, artigos e vídeos, siga o Skim AI em LinkedIn
É um Fundador, CEO, Capitalista de Risco ou Investidor que procura serviços de Consultoria de IA, Desenvolvimento de IA fraccionada ou Due Diligence? Obtenha a orientação necessária para tomar decisões informadas sobre a estratégia de produtos de IA da sua empresa e oportunidades de investimento.
Criamos soluções de IA personalizadas para empresas apoiadas por capital de risco e capital privado nos seguintes sectores: Tecnologia Médica, Agregação de Notícias/Conteúdo, Produção de Filmes e Fotos, Tecnologia Educacional, Tecnologia Jurídica, Fintech e Criptomoeda.


