
Resumo do artigo de investigação sobre IA: "Cadeia de Pensamento(menos)?" Prompting



A técnica Chain-of-Thought (CoT) tem sido aclamada como um avanço na libertação das capacidades de raciocínio dos modelos de linguagem de grande porte (LLMs). Esta técnica, que consiste em fornecer exemplos de raciocínio passo a passo para guiar os LLM, tem atraído uma atenção significativa na comunidade da IA. Muitos investigadores e profissionais afirmam que a técnica CoT permite que os LLMs resolvam tarefas de raciocínio complexas de forma mais eficaz, podendo assim colmatar o fosso entre a computação automática e a resolução de problemas de tipo humano.
No entanto, um documento recente intitulado "Cadeia de irreflexão? Uma análise da CdT no planeamento" desafia estas afirmações optimistas. Este trabalho de investigação, centrado em tarefas de planeamento, fornece uma análise crítica da eficácia e da generalização do CoT. Enquanto profissionais de IA, é crucial compreender estas conclusões e as suas implicações para o desenvolvimento de aplicações de IA que exijam capacidades de raciocínio sofisticadas.
Compreender o estudo
Os investigadores escolheram um domínio de planeamento clássico chamado Blocksworld como principal campo de ensaio. No Blocksworld, a tarefa é reorganizar um conjunto de blocos de uma configuração inicial para uma configuração de objetivo, utilizando uma série de acções de movimento. Este domínio é ideal para testar as capacidades de raciocínio e planeamento porque:
Permite a criação de problemas de complexidade variável
Tem soluções claras e verificáveis por algoritmos
É pouco provável que esteja fortemente representado nos dados de formação do LLM
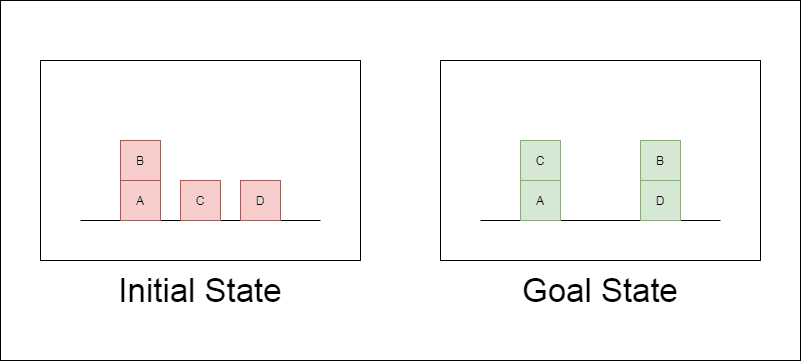
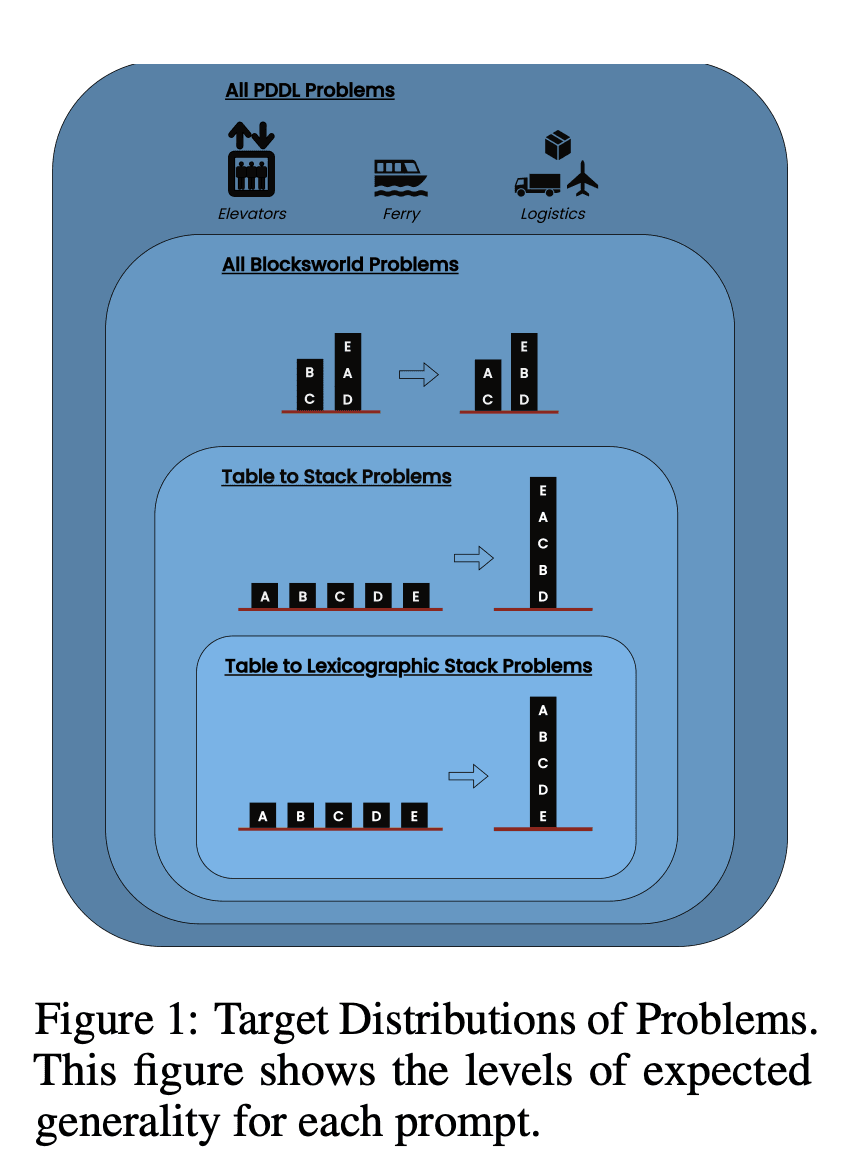
O estudo examinou três LLMs de última geração: GPT-4, Claude-3-Opus e GPT-4-Turbo. Estes modelos foram testados com mensagens de especificidade variável:
Cadeia de pensamento de tiro zero (Universal): Basta acrescentar "vamos pensar passo a passo" ao prompt.
Prova de progressão (específica da PDDL): Fornecer uma explicação geral da correção do plano com exemplos.
Algoritmo universal Blocksworld: Demonstração de um algoritmo geral para resolver qualquer problema Blocksworld.
Sugestão de empilhamento: Centrar-se numa subclasse específica de problemas Blocksworld (table-to-stack).
Empilhamento lexicográfico: Redução adicional a uma forma sintáctica específica do estado do objetivo.
Ao testar estas sugestões em problemas de complexidade crescente, os investigadores pretendiam avaliar até que ponto os LLMs conseguiam generalizar o raciocínio demonstrado nos exemplos.
Principais conclusões reveladas
Os resultados deste estudo desafiam muitos dos pressupostos prevalecentes sobre a solicitação de CoT:
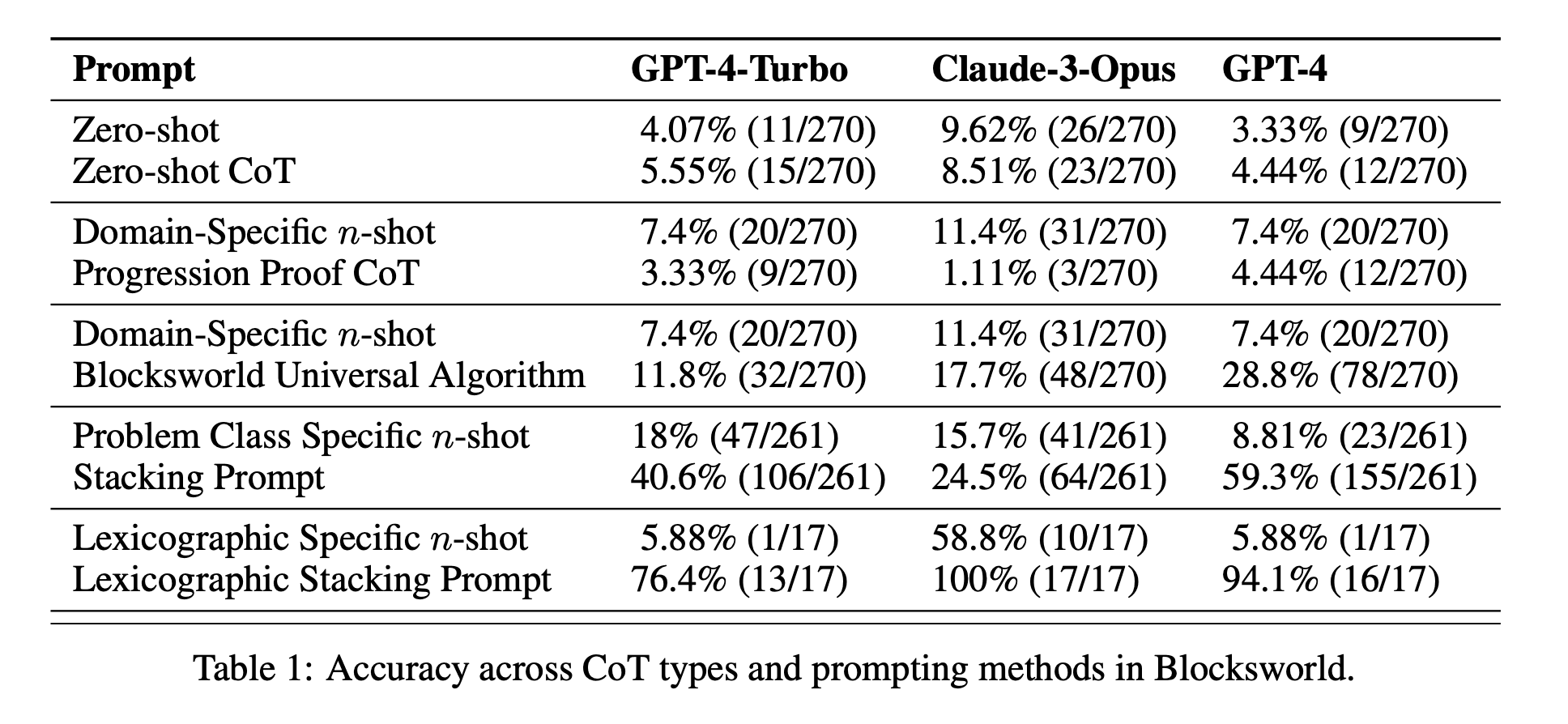
Eficácia limitada do CoT: Contrariamente às afirmações anteriores, a solicitação CoT só apresentou melhorias significativas de desempenho quando os exemplos fornecidos eram extremamente semelhantes ao problema de consulta. Assim que os problemas se desviaram do formato exato apresentado nos exemplos, o desempenho caiu drasticamente.
Degradação rápida do desempenho: À medida que a complexidade dos problemas aumentava (medida pelo número de blocos envolvidos), a precisão de todos os modelos diminuía drasticamente, independentemente do estímulo de CoT utilizado. Este facto sugere que os LLM têm dificuldade em alargar o raciocínio demonstrado em exemplos simples a cenários mais complexos.
Ineficácia das instruções gerais: Surpreendentemente, as instruções de CoT mais gerais tiveram um desempenho pior do que as instruções normais sem quaisquer exemplos de raciocínio. Este facto contradiz a ideia de que a CoT ajuda os LLM a aprender estratégias generalizáveis de resolução de problemas.
Compensação da especificidade: O estudo concluiu que as instruções altamente específicas podem atingir uma elevada precisão, mas apenas num subconjunto muito restrito de problemas. Este facto evidencia um forte compromisso entre os ganhos de desempenho e a aplicabilidade da mensagem.
Falta de uma verdadeira aprendizagem algorítmica: Os resultados sugerem fortemente que os LLM não estão a aprender a aplicar procedimentos algorítmicos gerais a partir dos exemplos de CoT. Em vez disso, parecem basear-se na correspondência de padrões, que se desintegra rapidamente quando confrontados com problemas novos ou mais complexos.
Estas conclusões têm implicações significativas para os profissionais de IA e para as empresas que pretendem tirar partido das solicitações de CoT nas suas aplicações. Sugerem que, embora a CoT possa melhorar o desempenho em determinados cenários restritos, pode não ser a panaceia para tarefas de raciocínio complexas que muitos esperavam.
Para além do Blocksworld: Alargamento da investigação
Para garantir que as suas conclusões não se limitavam ao domínio Blocksworld, os investigadores alargaram a sua investigação a vários domínios de problemas sintéticos habitualmente utilizados em estudos anteriores sobre CoT:
CoinFlip: Uma tarefa que envolve a previsão do estado de uma moeda após uma série de lançamentos.
LastLetterConcatenation: Uma tarefa de processamento de texto que requer a concatenação das últimas letras de determinadas palavras.
Aritmética de vários passos: Problemas de simplificação de expressões aritméticas complexas.
Estes domínios foram escolhidos porque permitem a criação de problemas com uma complexidade crescente, semelhante à do Blocksworld. Os resultados destas experiências adicionais foram surpreendentemente consistentes com os resultados do Blocksworld:
Falta de generalização: A solicitação de CoT mostrou melhorias apenas em problemas muito semelhantes aos exemplos fornecidos. À medida que a complexidade do problema aumentava, o desempenho diminuía rapidamente para níveis comparáveis ou piores do que os da solicitação padrão.
Correspondência de padrões sintácticos: Na tarefa LastLetterConcatenation, a sugestão de CoT melhorou certos aspectos sintácticos das respostas (como a utilização das letras corretas), mas não conseguiu manter a precisão à medida que o número de palavras aumentava.
Fracasso apesar de passos intermédios perfeitos: Nas tarefas de aritmética, mesmo quando os modelos conseguiam resolver perfeitamente todas as operações possíveis com um só algarismo, não conseguiam generalizar para sequências de operações mais longas.
Estes resultados reforçam ainda mais a conclusão de que os LLM actuais não aprendem verdadeiramente estratégias de raciocínio generalizáveis a partir de exemplos de CoT. Em vez disso, parecem basear-se fortemente na correspondência de padrões superficiais, que se desintegra quando confrontados com problemas que se desviam dos exemplos demonstrados.
Implicações para o desenvolvimento da IA
As conclusões deste estudo têm implicações significativas para o desenvolvimento da IA, em particular para as empresas que trabalham em aplicações que exigem capacidades complexas de raciocínio ou planeamento:
Reavaliação da eficácia da CdT: O estudo põe em causa a noção de que o CoT induz a "desbloquear" capacidades de raciocínio geral em LLMs. Os criadores de IA devem ser cautelosos quanto a confiar na CoT para tarefas que exijam um verdadeiro raciocínio algorítmico ou a generalização para cenários novos.
Limitações dos actuais LLM: Apesar das suas capacidades impressionantes em muitos domínios, os LLMs mais avançados continuam a ter dificuldades em raciocinar de forma consistente e generalizável. Isto sugere que podem ser necessárias abordagens alternativas para aplicações que exijam um planeamento robusto ou a resolução de problemas em várias etapas.
O custo da engenharia rápida: Embora os pedidos de CoT altamente específicos possam produzir bons resultados para conjuntos de problemas restritos, o esforço humano necessário para elaborar esses pedidos pode superar os benefícios, especialmente devido à sua limitada generalização.
Repensar as métricas de avaliação: O estudo realça a importância de testar modelos de IA em problemas de complexidade e estrutura variáveis. Confiar apenas em conjuntos de testes estáticos pode sobrestimar as verdadeiras capacidades de raciocínio de um modelo.
O fosso entre a perceção e a realidade: Existe uma discrepância significativa entre a perceção das capacidades de raciocínio dos LLM (frequentemente antropomorfizadas no discurso popular) e as suas capacidades reais, tal como demonstrado neste estudo.
Recomendações para os profissionais de IA
Tendo em conta estes dados, eis algumas recomendações fundamentais para os profissionais de IA e para as empresas que trabalham com LLMs:
Práticas de avaliação rigorosas:
Implementar estruturas de teste que possam gerar problemas de complexidade variável.
Não se baseie apenas em conjuntos de testes estáticos ou benchmarks que possam estar representados nos dados de formação.
Avaliar o desempenho num espetro de variações de problemas para avaliar a verdadeira generalização.
Expectativas realistas para a CdT:
Utilizar judiciosamente os estímulos do CoT, compreendendo as suas limitações em termos de generalização.
Tenha em atenção que as melhorias de desempenho do CoT podem ser limitadas a conjuntos de problemas restritos.
Considerar o compromisso entre o esforço de engenharia imediato e os potenciais ganhos de desempenho.
Abordagens híbridas:
Para tarefas de raciocínio complexas, considerar a combinação de LLMs com abordagens algorítmicas tradicionais ou módulos de raciocínio especializados.
Explorar métodos que possam tirar partido dos pontos fortes dos LLM (por exemplo, compreensão da linguagem natural), compensando simultaneamente as suas fraquezas em termos de raciocínio algorítmico.
Transparência nas aplicações de IA:
Comunicar claramente as limitações dos sistemas de IA, especialmente quando envolvem tarefas de raciocínio ou planeamento.
Evitar exagerar as capacidades dos LLMs, particularmente em aplicações de segurança crítica ou de alto risco.
Investigação e desenvolvimento contínuos:
Investir na investigação destinada a melhorar as verdadeiras capacidades de raciocínio dos sistemas de IA.
Explorar arquitecturas alternativas ou métodos de formação que possam conduzir a uma generalização mais robusta em tarefas complexas.
Afinação específica do domínio:
Para domínios problemáticos estreitos e bem definidos, considere a possibilidade de afinar os modelos com base em dados e padrões de raciocínio específicos do domínio.
Tenha em atenção que este ajuste fino pode melhorar o desempenho no domínio, mas não pode ser generalizado para além dele.
Seguindo estas recomendações, os profissionais de IA podem desenvolver aplicações de IA mais robustas e fiáveis, evitando as potenciais armadilhas associadas à sobrestimação das capacidades de raciocínio dos actuais LLM. As conclusões deste estudo constituem um valioso lembrete da importância da avaliação crítica e da avaliação realista no domínio da IA em rápida evolução.
A linha de fundo
Este estudo pioneiro sobre o estímulo da cadeia de pensamento em tarefas de planeamento desafia a nossa compreensão das capacidades de LLM e leva a uma reavaliação das actuais práticas de desenvolvimento de IA. Ao revelar as limitações da CoT na generalização a problemas complexos, sublinha a necessidade de testes mais rigorosos e de expectativas mais realistas nas aplicações de IA.
Para os profissionais de IA e para as empresas, estas conclusões sublinham a importância de combinar os pontos fortes do LLM com abordagens de raciocínio especializadas, investindo em soluções específicas do domínio sempre que necessário e mantendo a transparência sobre as limitações do sistema de IA. À medida que avançamos, a comunidade de IA deve concentrar-se no desenvolvimento de novas arquitecturas e métodos de formação que possam colmatar a lacuna entre a correspondência de padrões e o verdadeiro raciocínio algorítmico. Este estudo serve como um lembrete crucial de que, embora os LLMs tenham feito progressos notáveis, alcançar capacidades de raciocínio semelhantes às humanas continua a ser um desafio permanente na investigação e desenvolvimento da IA.


