
Dobbiamo ripensare la catena del pensiero (CoT) che spinge l'AI&YOU #68



Statistica della settimana: Zero-shot CoT performance was only 5.55% for GPT-4-Turbo, 8.51% for Claude-3-Opus, and 4.44% for GPT-4. (“Chain of Thoughtlessness?” paper)
Chain-of-Thought (CoT) prompting has been hailed as a breakthrough in unlocking the reasoning capabilities of large language models (LLMs). However, recent research has challenged these claims and prompted us to revisit the technique.
Nell'edizione di questa settimana di AI&YOU, esploriamo le intuizioni di tre blog che abbiamo pubblicato sull'argomento:
We need to rethink chain-of-thought (CoT) prompting AI&YOU #68
LLMs demonstrate remarkable capabilities in natural language processing (NLP) and generation. However, when faced with complex reasoning tasks, these models can struggle to produce accurate and reliable results. This is where Chain-of-Thought (CoT) prompting comes into play, a technique that aims to enhance the problem-solving abilities of LLMs.
An advanced ingegneria tempestiva technique, it is designed to guide LLMs through a step-by-step reasoning process. Unlike standard prompting methods that aim for direct answers, CoT prompting encourages the model to generate intermediate reasoning steps before arriving at a final answer.
At its core, CoT prompting involves structuring input prompts in a way that elicits a logical sequence of thoughts from the model. By breaking down complex problems into smaller, manageable steps, CoT attempts to enable LLMs to navigate through intricate reasoning paths more effectively.
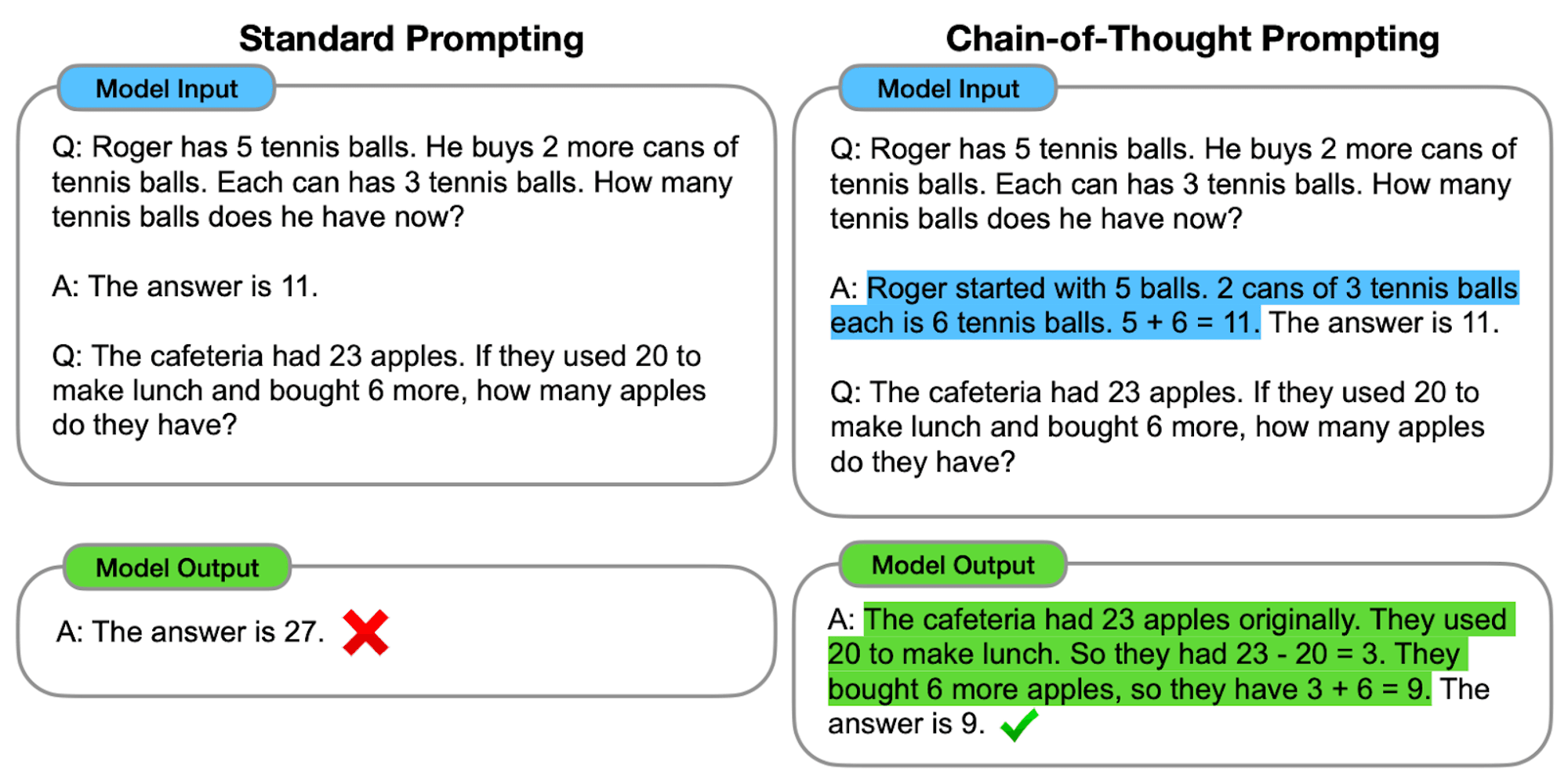
Come funziona la CoT
Nella sua essenza, la richiesta di CoT guida i modelli linguistici attraverso una serie di fasi intermedie di ragionamento prima di arrivare a una risposta finale. Questo processo prevede in genere:
Decomposizione del problema: Il compito complesso viene suddiviso in fasi più piccole e gestibili.
Ragionamento passo-passo: Il modello viene invitato a riflettere esplicitamente su ogni fase.
Progressione logica: Ogni passo si basa sul precedente, creando una catena di pensieri.
Disegno di conclusione: La risposta finale deriva dalle fasi di ragionamento accumulate.
Tipi di sollecitazione della CoT
La sollecitazione della catena di pensiero può essere attuata in vari modi, tra cui spiccano due tipi principali:
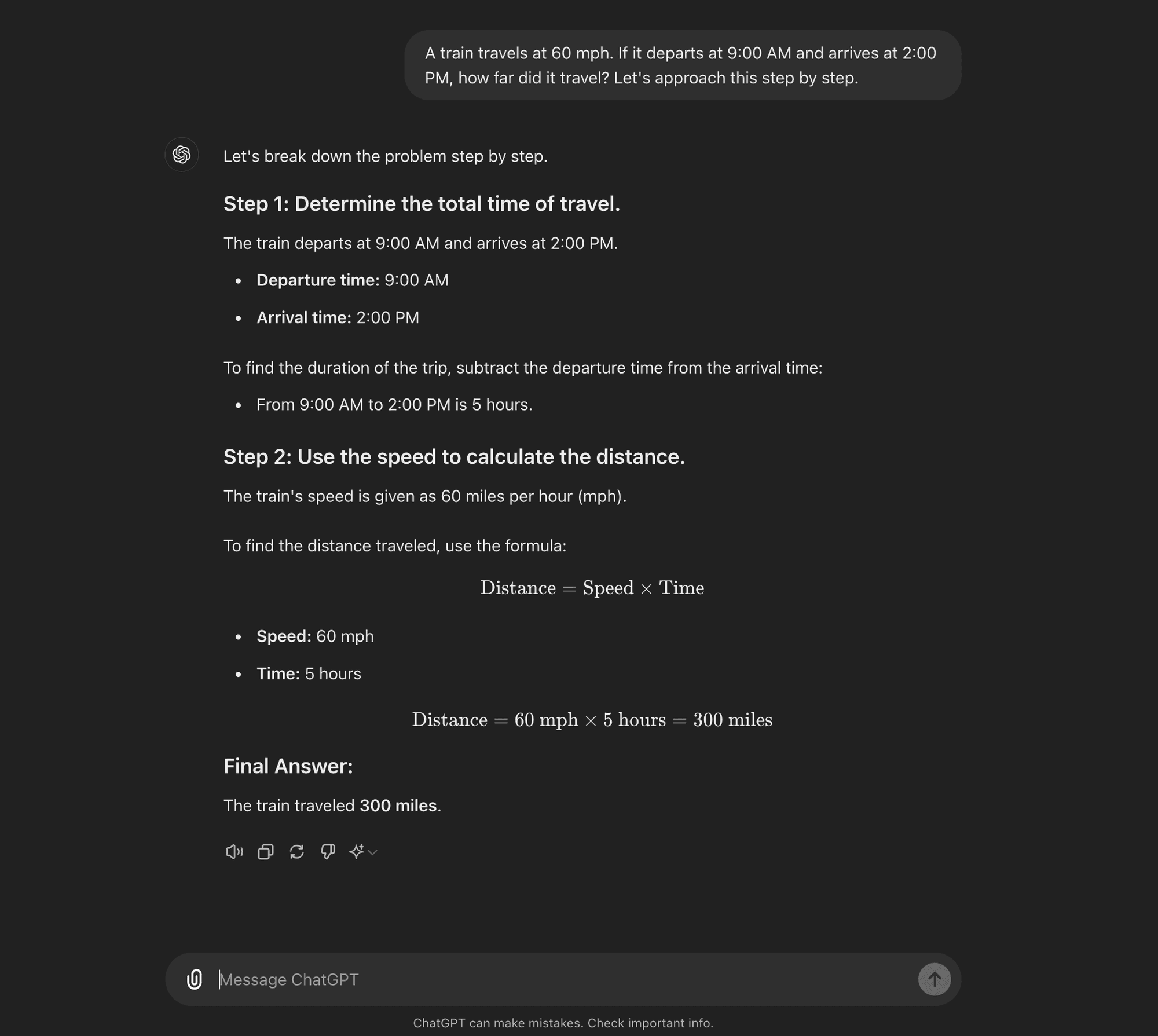
Zero-shot CoT: Zero-shot CoT doesn’t require task-specific examples. Instead, it uses a simple prompt like “Let’s approach this step by step” to encourage the model to break down its reasoning process.****
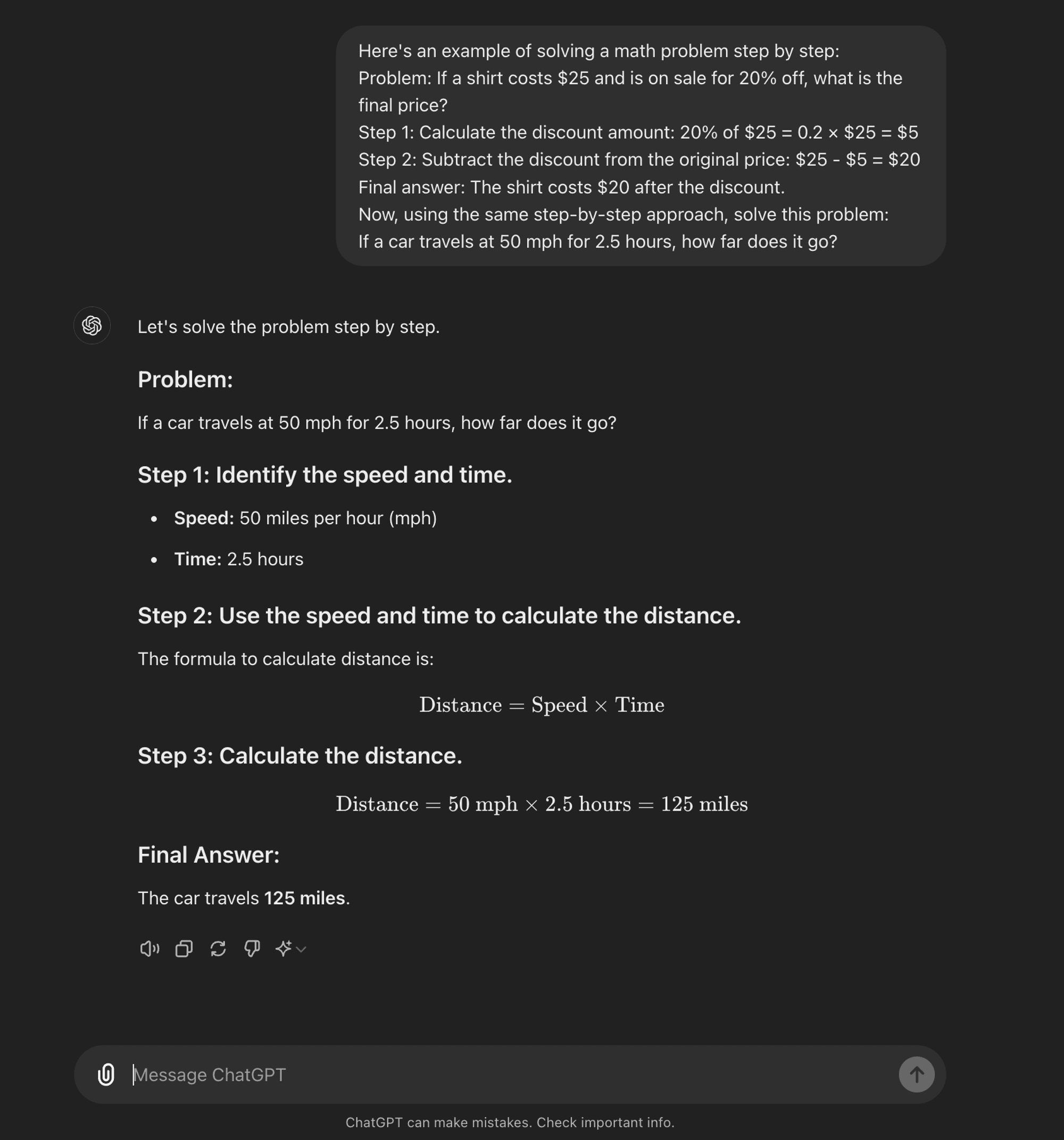
Few-shot CoT: La CoT a pochi colpi consiste nel fornire al modello un piccolo numero di esempi che dimostrano il processo di ragionamento desiderato. Questi esempi servono come modello da seguire per il modello quando affronta problemi nuovi e sconosciuti.
Zero-shot CoT
Few-shot CoT
AI Research Paper Breakdown: “Chain of Thoughtlessness?”
Now that you know what CoT prompting is, we can dive into some recent research that challenges some of its benefits and offers some insight into when it is actually useful.
The research paper, titled “Chain of Thoughtlessness? An Analysis of CoT in Planning,” provides a critical examination of CoT prompting’s effectiveness and generalizability. As AI practitioners, it’s crucial to understand these findings and their implications for developing AI applications that require sophisticated reasoning capabilities.

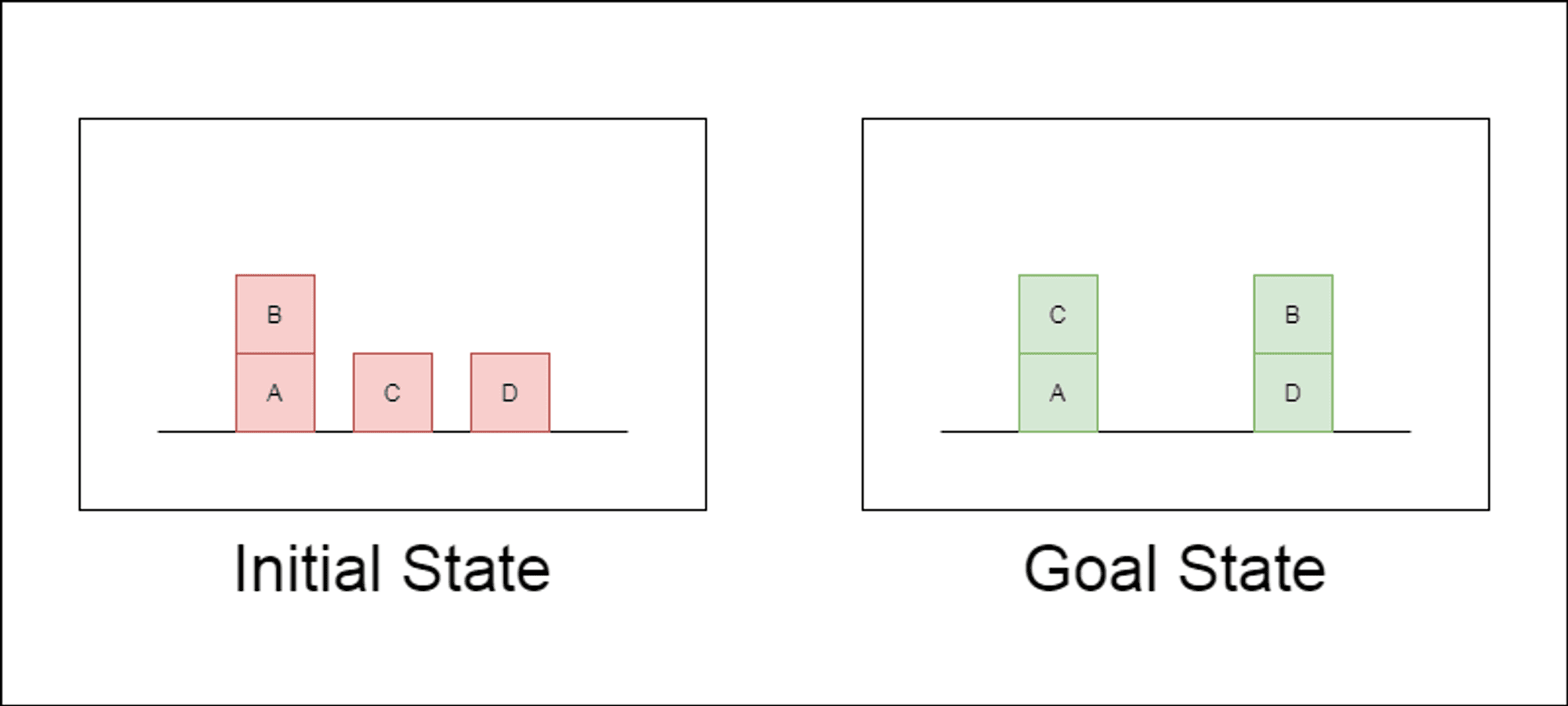
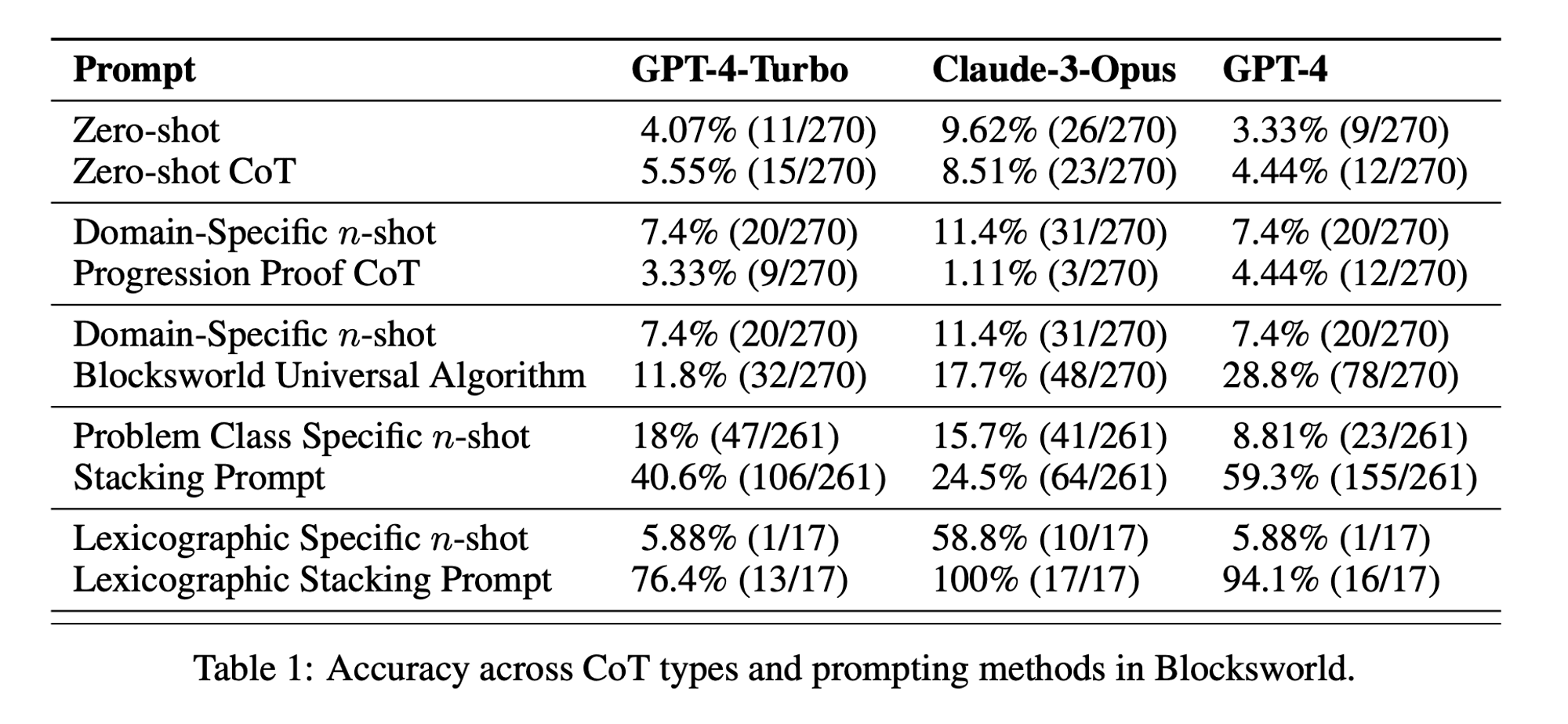
I ricercatori hanno scelto un dominio di pianificazione classico chiamato Blocksworld come terreno di prova principale. In Blocksworld, il compito è quello di riorganizzare un insieme di blocchi da una configurazione iniziale a una configurazione finale, utilizzando una serie di azioni di spostamento. Questo dominio è ideale per testare le capacità di ragionamento e di pianificazione perché:
Permette di generare problemi di complessità variabile.
Ha soluzioni chiare e verificabili dal punto di vista algoritmico.
È improbabile che sia molto rappresentato nei dati di formazione di LLM.
Lo studio ha esaminato tre LLM di ultima generazione: GPT-4, Claude-3-Opus e GPT-4-Turbo. Questi modelli sono stati testati utilizzando prompt di diversa specificità:
Catena di pensieri a colpo zero (Universale): Semplicemente aggiungendo "pensiamo passo dopo passo" al prompt.
Prova di progressione (specifica per la PDDL): Fornire una spiegazione generale della correttezza del piano con esempi.
Algoritmo universale di Blocksworld: Dimostrare un algoritmo generale per risolvere qualsiasi problema di Blocksworld.
Prompt di impilamento: Concentrarsi su una sottoclasse specifica di problemi di Blocksworld (table-to-stack).
Accatastamento lessicografico: Ulteriore restringimento a una particolare forma sintattica dello stato obiettivo.
Testando questi suggerimenti su problemi di complessità crescente, i ricercatori hanno voluto valutare quanto i LLM fossero in grado di generalizzare il ragionamento dimostrato negli esempi.
Svelati i risultati principali
I risultati di questo studio mettono in discussione molte delle ipotesi prevalenti sulla richiesta di CoT:
Efficacia limitata della CoT: Contrariamente a quanto affermato in precedenza, la richiesta di CoT ha mostrato miglioramenti significativi delle prestazioni solo quando gli esempi forniti erano estremamente simili al problema da interrogare. Non appena i problemi si discostano dall'esatto formato mostrato negli esempi, le prestazioni calano drasticamente.
Rapido degrado delle prestazioni: Con l'aumentare della complessità dei problemi (misurata in base al numero di blocchi coinvolti), l'accuratezza di tutti i modelli è diminuita drasticamente, indipendentemente dal prompt CoT utilizzato. Ciò suggerisce che i LLM faticano a estendere il ragionamento dimostrato in esempi semplici a scenari più complessi.
Inefficacia dei suggerimenti generali: Sorprendentemente, i suggerimenti più generali della CoT hanno spesso dato risultati peggiori rispetto a quelli standard senza esempi di ragionamento. Questo contraddice l'idea che la CoT aiuti i LLM ad apprendere strategie generalizzabili di risoluzione dei problemi.
Trade-off di specificità: Lo studio ha rilevato che i prompt altamente specifici possono raggiungere un'elevata accuratezza, ma solo su un sottoinsieme molto ristretto di problemi. Ciò evidenzia un forte compromesso tra l'aumento delle prestazioni e l'applicabilità del prompt.
Mancanza di un vero apprendimento algoritmico: I risultati suggeriscono fortemente che i LLM non stanno imparando ad applicare procedure algoritmiche generali dagli esempi di CoT. Sembrano invece affidarsi alla corrispondenza dei modelli, che si rompe rapidamente quando si trovano di fronte a problemi nuovi o più complessi.
Questi risultati hanno implicazioni significative per i professionisti dell'intelligenza artificiale e per le aziende che desiderano sfruttare i prompt della CoT nelle loro applicazioni. Suggeriscono che, sebbene la CoT possa aumentare le prestazioni in alcuni scenari ristretti, potrebbe non essere la panacea per i compiti di ragionamento complessi che molti avevano sperato.
Implicazioni per lo sviluppo dell'IA
I risultati di questo studio hanno implicazioni significative per lo sviluppo dell'IA, in particolare per le imprese che lavorano su applicazioni che richiedono capacità complesse di ragionamento o pianificazione:
Rivalutazione dell'efficacia della CTF: AI developers should be cautious about relying on CoT for tasks that require true algorithmic thinking or generalization to novel scenarios.
Limiti degli attuali LLM: Alternative approaches may be necessary for applications requiring robust planning or multi-step problem-solving.
Il costo dell'ingegneria tempestiva: Sebbene i suggerimenti di CoT altamente specifici possano dare buoni risultati per insiemi di problemi ristretti, l'impegno umano richiesto per creare questi suggerimenti può superare i benefici, soprattutto in considerazione della loro limitata generalizzabilità.
Ripensare le metriche di valutazione: Relying solely on static test sets may overestimate a model’s true reasoning capabilities.
Il divario tra percezione e realtà: C'è una discrepanza significativa tra le capacità di ragionamento percepite dei LLM (spesso antropomorfizzate nel discorso popolare) e le loro reali capacità, come dimostrato in questo studio.
Recommendations for AI Practitioners:
Valutazione: Implement diverse testing frameworks to assess true generalization across problem complexities.
CoT Usage: Apply Chain-of-Thought prompting judiciously, recognizing its limitations in generalization.
Hybrid Solutions: Consider combining LLMs with traditional algorithms for complex reasoning tasks.
Transparency: Clearly communicate AI system limitations, especially for reasoning or planning tasks.
R&D Focus: Invest in research to enhance true reasoning capabilities of AI systems.
Messa a punto: Consider domain-specific fine-tuning, but be aware of potential generalization limits.
For AI practitioners and enterprises, these findings highlight the importance of combining LLM strengths with specialized reasoning approaches, investing in domain-specific solutions where necessary, and maintaining transparency about AI system limitations. As we move forward, the AI community must focus on developing new architectures and training methods that can bridge the gap between pattern matching and true algorithmic reasoning.
10 Best Prompting Techniques for LLMs
This week, we also explore ten of the most powerful and common prompting techniques, offering insights into their applications and best practices.

Well-designed prompts can significantly enhance an LLM’s performance, enabling more accurate, relevant, and creative outputs. Whether you’re a seasoned AI developer or just starting with LLMs, these techniques will help you unlock the full potential of AI models.
Make sure to check out the full blog to learn more about each one.
Grazie per aver dedicato del tempo alla lettura di AI & YOU!
Per ulteriori contenuti sull'IA aziendale, tra cui infografiche, statistiche, guide, articoli e video, seguite Skim AI su LinkedIn
Siete un fondatore, un CEO, un Venture Capitalist o un investitore alla ricerca di servizi di consulenza sull'IA, di sviluppo frazionario dell'IA o di due diligence? Ottenete la guida necessaria per prendere decisioni informate sulla strategia di prodotto AI della vostra azienda e sulle opportunità di investimento.
Realizziamo soluzioni AI personalizzate per aziende sostenute da Venture Capital e Private Equity nei seguenti settori: Tecnologia medica, aggregazione di notizie e contenuti, produzione di film e foto, tecnologia educativa, tecnologia legale, Fintech e criptovalute.


