
Esercitazione: Come mettere a punto BERT per una sintesi estrattiva



Esercitazione: Come mettere a punto BERT per una sintesi estrattiva
Pubblicato originariamente dal ricercatore di apprendimento automatico di Skim AI, Chris Tran.![]()
1. Introduzione
La sintesi è da tempo una sfida nell'elaborazione del linguaggio naturale. Per generare una versione breve di un documento conservando le informazioni più importanti, è necessario un modello in grado di estrarre accuratamente i punti chiave evitando le informazioni ripetitive. Fortunatamente, i recenti lavori in NLP, come i modelli Transformer e il pretraining dei modelli linguistici, hanno fatto avanzare lo stato dell'arte della sintesi.
In questo articolo esploreremo BERTSUM, una semplice variante di BERT, per la riassunzione estrattiva da Riassunto di testi con codificatori preaddestrati (Liu et al., 2019). Poi, nel tentativo di rendere la sintesi estrattiva ancora più veloce e piccola per i dispositivi a basse risorse, perfezioneremo DistilBERT (Sanh et al., 2019) e MobileBERT (Sun et al., 2019), due recenti versioni lite di BERT, e discutiamo i nostri risultati.
2. Riassunto estrattivo
Esistono due tipi di riassunto: astrattivo e riassunto estrattivo. La sintesi astraente significa fondamentalmente riscrivere i punti chiave, mentre la sintesi estrattiva genera un riassunto copiando direttamente le frasi più importanti da un documento.
La sintesi astratta è più impegnativa per gli esseri umani e anche più costosa dal punto di vista computazionale per le macchine. Tuttavia, la scelta del riassunto migliore dipende dallo scopo dell'utente finale. Se si sta scrivendo un saggio, il riassunto astraente potrebbe essere la scelta migliore. D'altra parte, se si sta facendo una ricerca e si ha bisogno di un riassunto veloce di ciò che si sta leggendo, la sintesi estrattiva sarebbe più utile per questo compito.
In questa sezione esploreremo l'architettura del nostro modello di riassunto estrattivo. Il sintetizzatore BERT è composto da due parti: un codificatore BERT e un classificatore di sintesi.
Codificatore BERT

L'architettura generale di BERTSUM
Il nostro codificatore BERT è il codificatore BERT-base preaddestrato dal compito di modellazione linguistica mascherata (Devlin e altri, 2018). Il compito della sintesi estrattiva è un problema di classificazione binaria a livello di frase. Vogliamo assegnare a ogni frase un'etichetta $y_i \ in {0, 1}$ che indichi se la frase deve essere inclusa nel riassunto finale. Pertanto, dobbiamo aggiungere un token [CLS] prima di ogni frase. Dopo aver eseguito un passaggio in avanti attraverso il codificatore, l'ultimo strato nascosto di questi [CLS] saranno utilizzati come rappresentazioni delle nostre frasi.
Classificatore di sintesi
Dopo aver ottenuto la rappresentazione vettoriale di ogni frase, possiamo utilizzare un semplice livello feed forward come classificatore per restituire un punteggio per ogni frase. Nel documento, l'autore ha sperimentato un semplice classificatore lineare, una rete neurale ricorrente e un piccolo modello Transformer a 3 strati. Il classificatore Transformer ha dato i risultati migliori, dimostrando che le interazioni tra le frasi attraverso il meccanismo di autoattenzione sono importanti per selezionare le frasi più importanti.
Nel codificatore, quindi, impariamo le interazioni tra i token del nostro documento, mentre nel classificatore di sintesi impariamo le interazioni tra le frasi.
3. Rendere la sintesi ancora più veloce
I modelli di trasformatori raggiungono prestazioni all'avanguardia nella maggior parte dei bechmark di NLP; tuttavia, l'addestramento e l'elaborazione di previsioni sono computazionalmente costosi. Nel tentativo di rendere la sintetizzazione più leggera e veloce per essere distribuita su dispositivi a basse risorse, ho modificato il modello codici sorgente fornito dagli autori di BERTSUM per sostituire il codificatore BERT con DistilBERT e MobileBERT. Gli strati riassuntivi sono mantenuti invariati.
Ecco le perdite di allenamento di queste 3 varianti: TensorBoard

Nonostante sia 40% più piccolo di BERT-base, DistilBERT ha le stesse perdite di addestramento di BERT-base, mentre MobileBERT si comporta leggermente peggio. La tabella seguente mostra le loro prestazioni sul dataset CNN/DailyMail, le dimensioni e il tempo di esecuzione di un passaggio in avanti:
| Modelli | ROUGE-1 | ROUGE-2 | ROUGE-L | Tempo di inferenza* | Dimensione | Parametri |
|---|---|---|---|---|---|---|
| bert-base | 43.23 | 20.24 | 39.63 | 1.65 s | 475 MB | 120.5 M |
| distilbert | 42.84 | 20.04 | 39.31 | 925 ms | 310 MB | 77.4 M |
| mobilebert | 40.59 | 17.98 | 36.99 | 609 ms | 128 MB | 30.8 M |
*Tempo medio di esecuzione di un passaggio in avanti su una singola GPU su un notebook standard di Google Colab
Con una velocità di 45%, DistilBERT ha quasi le stesse prestazioni di BERT-base. MobileBERT mantiene le prestazioni di 94% di BERT-base, pur essendo 4 volte più piccolo di BERT-base e 2,5 volte più piccolo di DistilBERT. Nel documento MobileBERT dimostra che MobileBERT supera in modo significativo DistilBERT su SQuAD v1.1. Tuttavia, non è il caso della sintesi estrattiva. Si tratta comunque di un risultato impressionante per MobileBERT con un disco di soli 128 MB.
4. Riassumiamo
Tutti i punti di controllo pre-addestrati, i dettagli dell'addestramento e le istruzioni di configurazione sono disponibili in questo repository GitHub. Inoltre, ho distribuito una demo di BERTSUM con il codificatore MobileBERT.
Applicazione web: https://extractive-summarization.herokuapp.com/
![]()
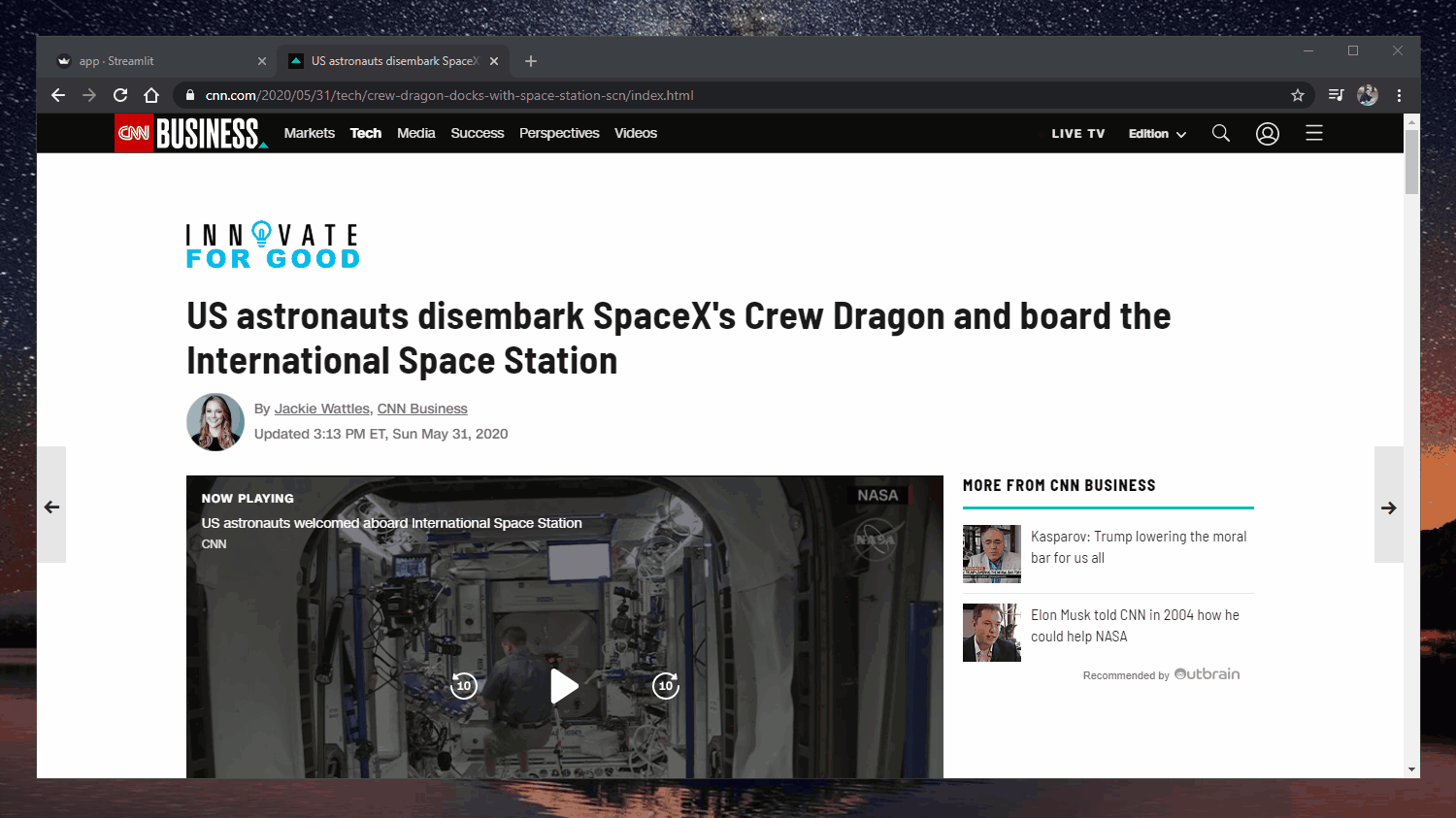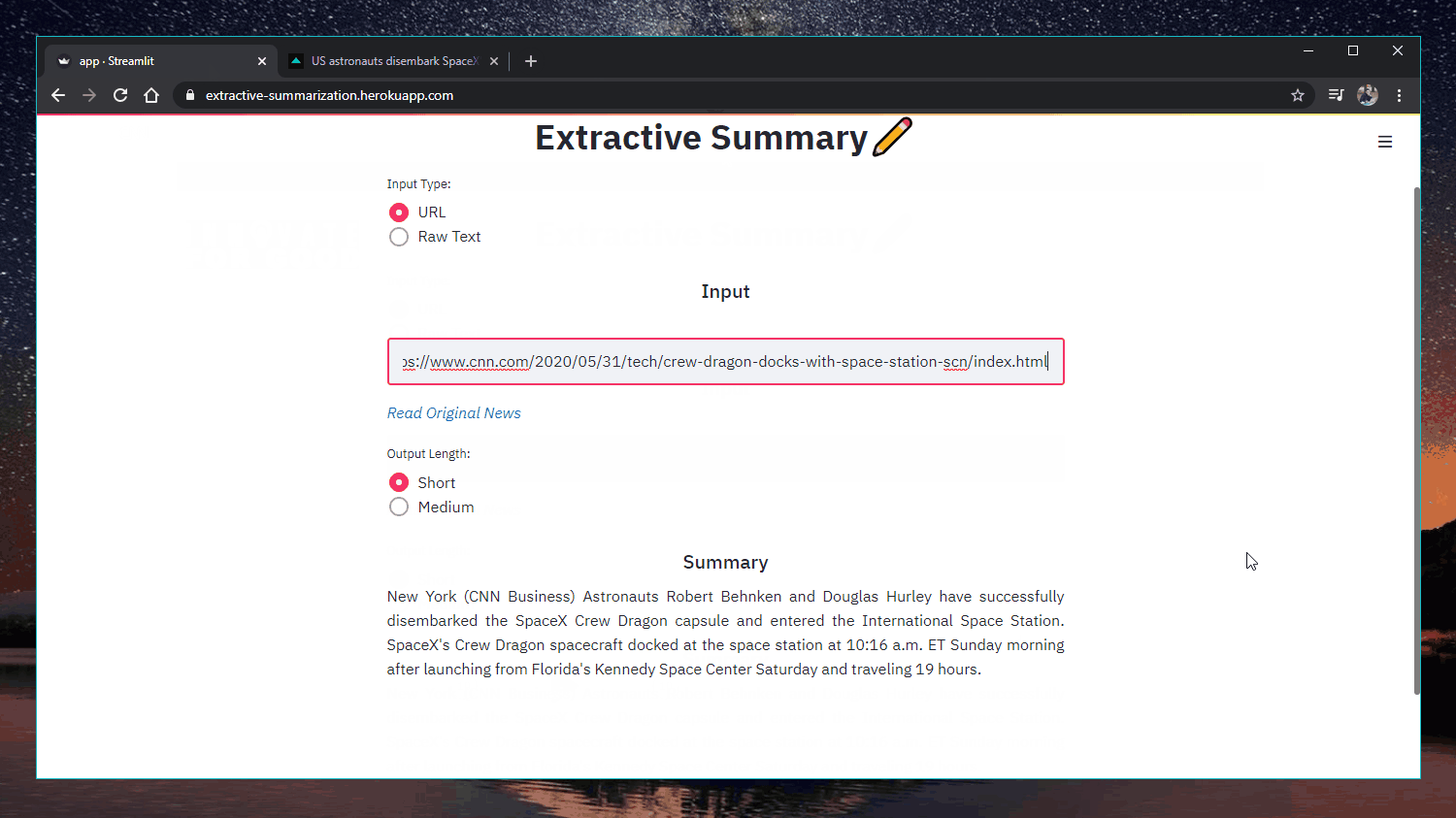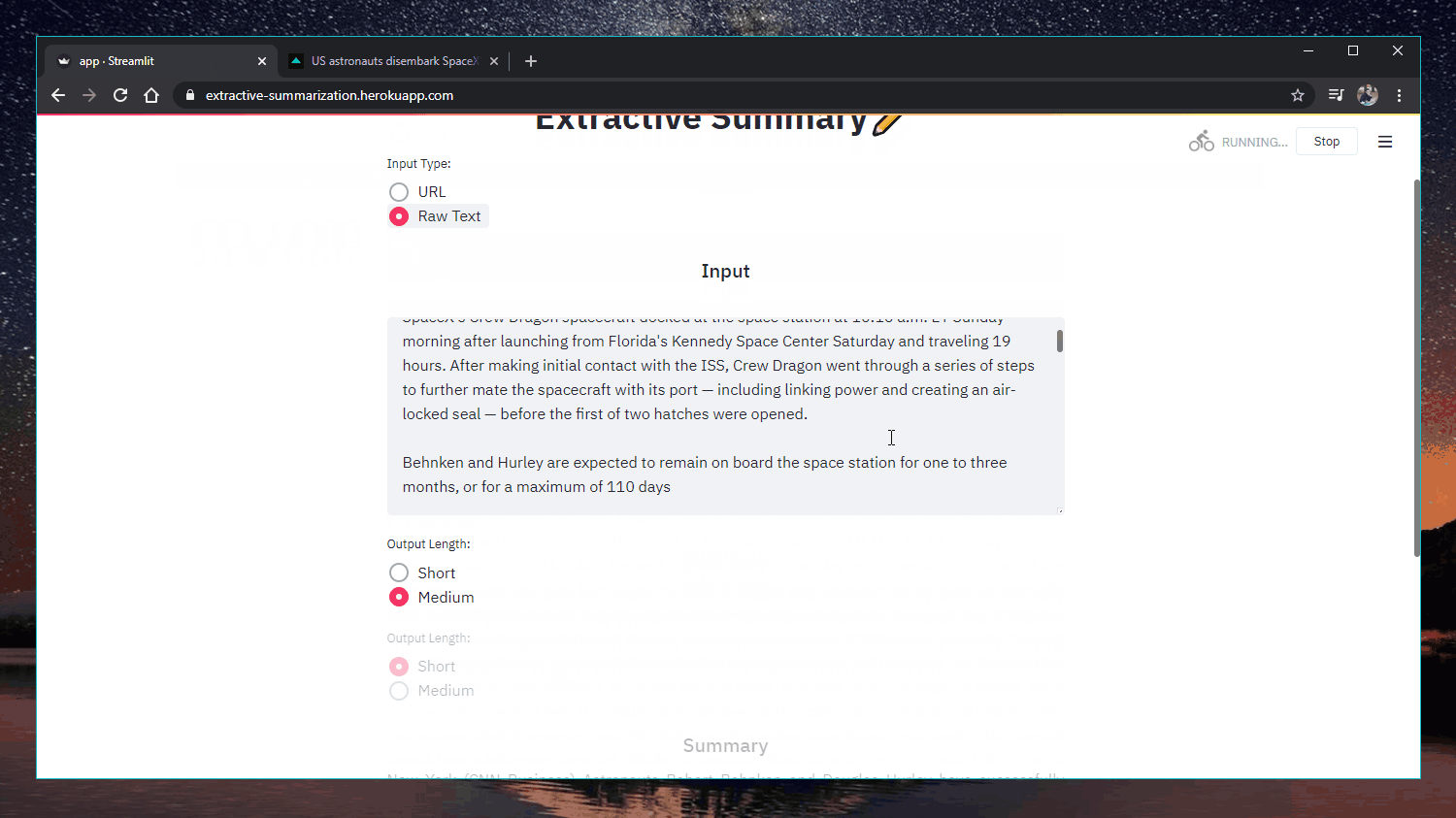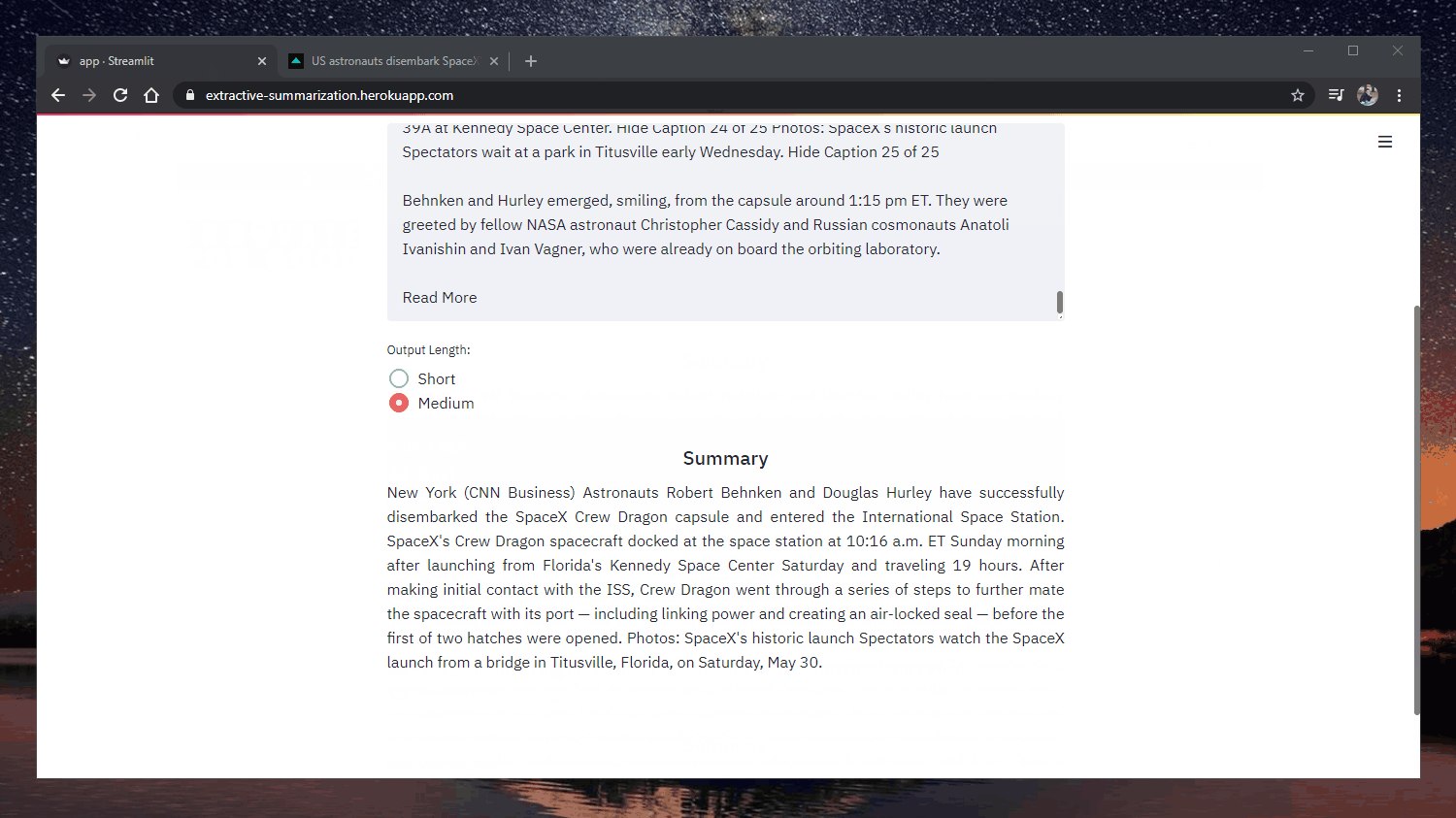
Codice:
![]()
importare torch
da models.model_builder import ExtSummarizer
da ext_sum import summarize
# Carica il modello
model_type = 'mobilebert' #@param ['bertbase', 'distilbert', 'mobilebert']
checkpoint = torch.load(f'checkpoints/{model_type}_ext.pt', map_location='cpu')
model = ExtSummarizer(checkpoint=checkpoint, bert_type=model_type, device='cpu')
# Eseguire la sintesi
input_fp = 'raw_data/input.txt'
result_fp = 'results/summary.txt'
summary = summarize(input_fp, result_fp, model, max_length=3)
print(summary)
Campione riassuntivo
Originale: https://www.cnn.com/2020/05/22/business/hertz-bankruptcy/index.html
Con la dichiarazione di bancarotta, Hertz dichiara di voler rimanere in attività ristrutturando i debiti ed emergendo come un'azienda finanziariamente più sana.
finanziariamente più sana. L'azienda noleggia auto dal 1918, quando ha aperto un negozio con una dozzina di Ford Model T, ed è sopravvissuta alla Grande Depressione, all'arresto virtuale degli Stati Uniti e a una serie di eventi.
Ford Model T, ed è sopravvissuta alla Grande Depressione, al blocco virtuale della produzione automobilistica statunitense durante la Seconda Guerra Mondiale e a numerosi shock petroliferi.
e a numerosi shock del prezzo del petrolio. "L'impatto della Covid-19 sulla domanda di viaggi è stato improvviso e drammatico, causando un brusco declino della società.
un brusco calo dei ricavi e delle prenotazioni future", si legge nel comunicato dell'azienda.
5. Conclusione
In questo articolo abbiamo esplorato BERTSUM, una semplice variante di BERT, per la sintesi estrattiva dei documenti. Riassunto di testi con codificatori preaddestrati (Liu et al., 2019). Poi, nel tentativo di rendere la sintesi estrattiva ancora più veloce e più piccola per i dispositivi a basse risorse, abbiamo messo a punto DistilBERT (Sanh et al., 2019) e MobileBERT (Sun et al., 2019) sui dataset CNN/DailyMail.
DistilBERT mantiene le prestazioni di BERT-base nella sintesi estrattiva, pur essendo più piccolo di 45%. MobileBERT è 4 volte più piccolo e 2,7 volte più veloce di BERT-base, pur mantenendo 94% delle sue prestazioni.
Infine, abbiamo distribuito un'applicazione web dimostrativa di MobileBERT per la sintesi estrattiva su https://extractive-summarization.herokuapp.com/.


