
Wir müssen die Gedankenkette (CoT) überdenken, die AI&YOU #68 auslöst



Statistik der Woche: Zero-shot CoT performance was only 5.55% for GPT-4-Turbo, 8.51% for Claude-3-Opus, and 4.44% for GPT-4. (“Chain of Thoughtlessness?” paper)
Chain-of-Thought (CoT) prompting has been hailed as a breakthrough in unlocking the reasoning capabilities of large language models (LLMs). However, recent research has challenged these claims and prompted us to revisit the technique.
In der diesjährigen Ausgabe von AI&YOU befassen wir uns mit den Erkenntnissen aus drei Blogs, die wir zu diesem Thema veröffentlicht haben:
We need to rethink chain-of-thought (CoT) prompting AI&YOU #68
LLMs demonstrate remarkable capabilities in natural language processing (NLP) and generation. However, when faced with complex reasoning tasks, these models can struggle to produce accurate and reliable results. This is where Chain-of-Thought (CoT) prompting comes into play, a technique that aims to enhance the problem-solving abilities of LLMs.
An advanced schnelles Engineering technique, it is designed to guide LLMs through a step-by-step reasoning process. Unlike standard prompting methods that aim for direct answers, CoT prompting encourages the model to generate intermediate reasoning steps before arriving at a final answer.
At its core, CoT prompting involves structuring input prompts in a way that elicits a logical sequence of thoughts from the model. By breaking down complex problems into smaller, manageable steps, CoT attempts to enable LLMs to navigate through intricate reasoning paths more effectively.
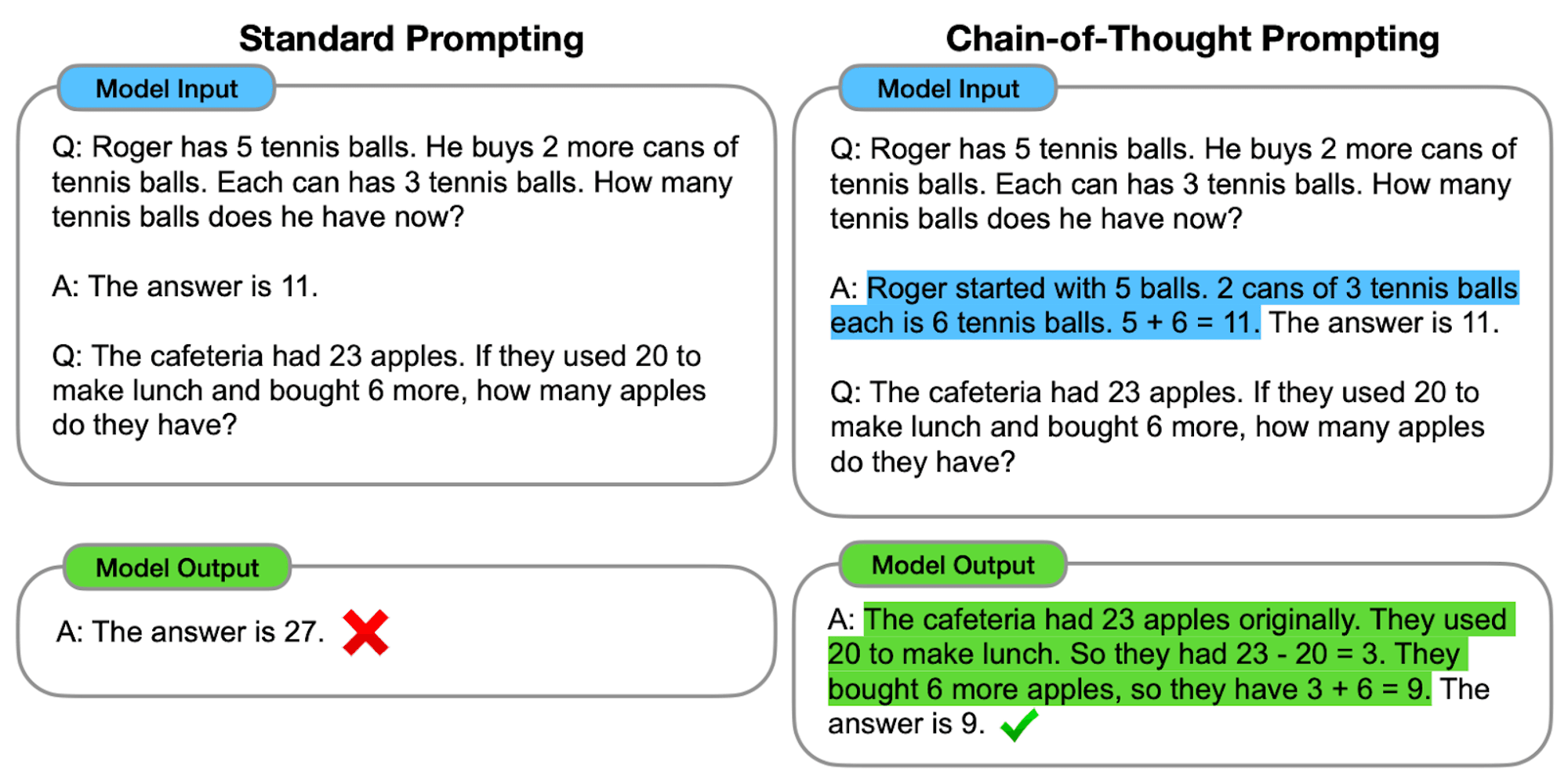
Wie CoT funktioniert
Im Kern führt das CoT-Prompting Sprachmodelle durch eine Reihe von Zwischenschritten, bevor sie zu einer endgültigen Antwort gelangen. Dieser Prozess umfasst in der Regel folgende Schritte:
Problem-Zerlegung: Die komplexe Aufgabe wird in kleinere, überschaubare Schritte aufgeteilt.
Schritt-für-Schritt-Reasoning: Das Modell wird dazu aufgefordert, jeden Schritt explizit zu durchdenken.
Logische Progression: Jeder Schritt baut auf dem vorherigen auf und bildet eine Gedankenkette.
Fazit Zeichnung: Die endgültige Antwort ergibt sich aus den kumulierten Argumentationsschritten.
Arten von CoT Prompting
Das Prompting der Gedankenkette kann auf verschiedene Weise umgesetzt werden, wobei zwei Haupttypen hervorstechen:
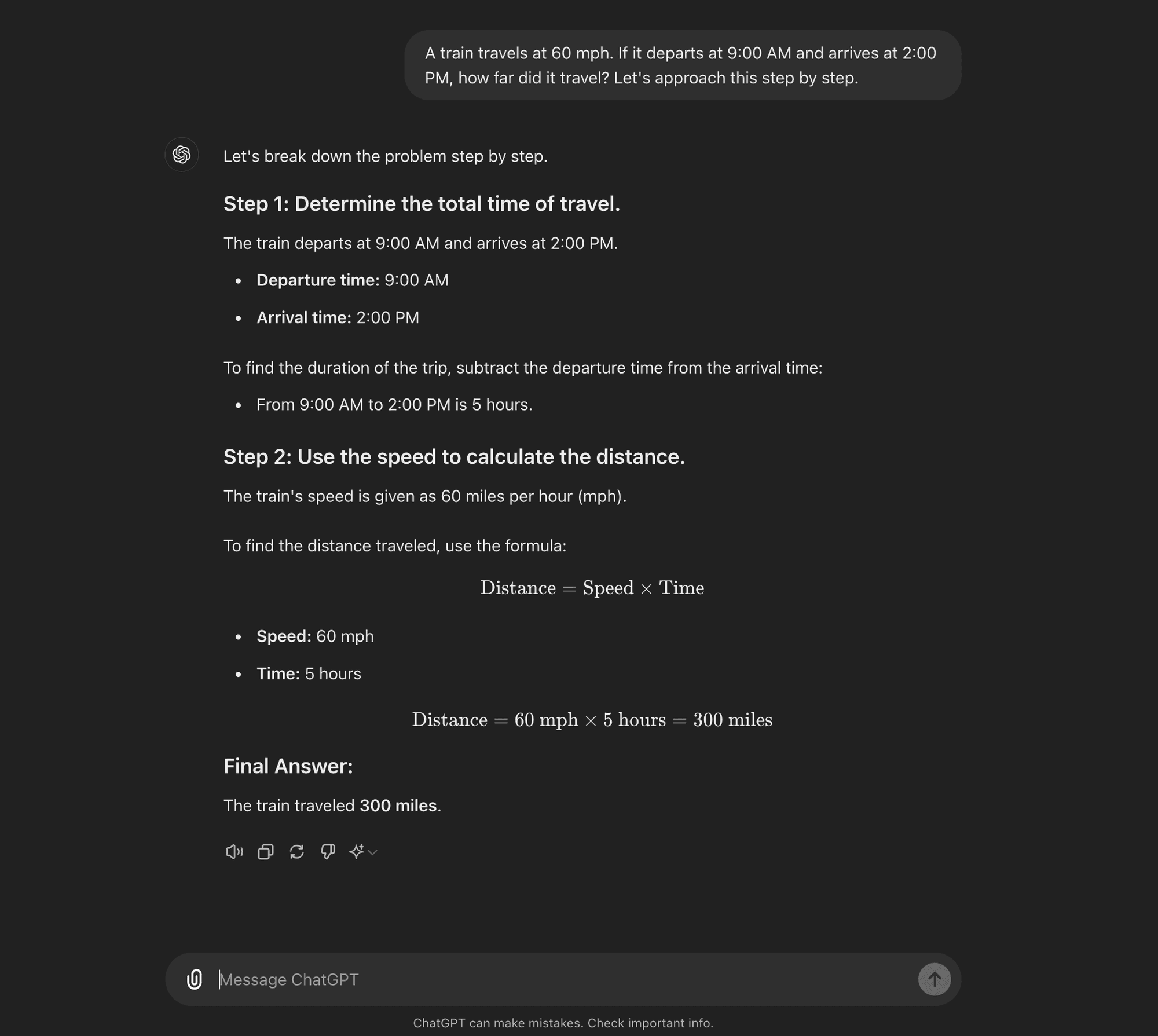
Zero-shot CoT: Zero-shot CoT doesn’t require task-specific examples. Instead, it uses a simple prompt like “Let’s approach this step by step” to encourage the model to break down its reasoning process.****
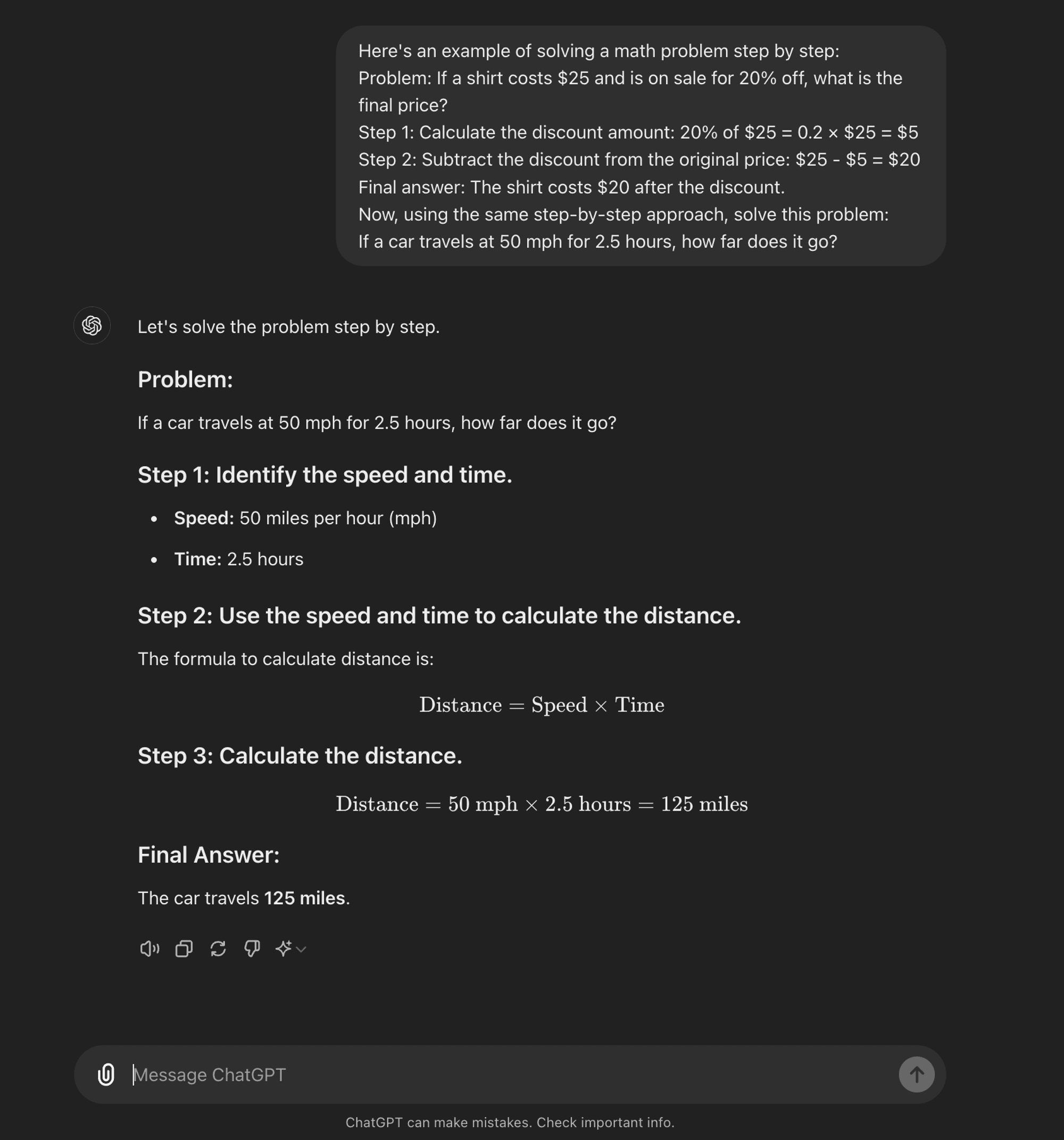
Few-shot CoT: Beim Few-shot CoT wird dem Modell eine kleine Anzahl von Beispielen zur Verfügung gestellt, die den gewünschten Denkprozess veranschaulichen. Diese Beispiele dienen als Vorlage für das Modell, wenn es neue, unbekannte Probleme angeht.
Zero-shot CoT
Few-shot CoT
AI Research Paper Breakdown: “Chain of Thoughtlessness?”
Now that you know what CoT prompting is, we can dive into some recent research that challenges some of its benefits and offers some insight into when it is actually useful.
The research paper, titled “Chain of Thoughtlessness? An Analysis of CoT in Planning,” provides a critical examination of CoT prompting’s effectiveness and generalizability. As AI practitioners, it’s crucial to understand these findings and their implications for developing AI applications that require sophisticated reasoning capabilities.

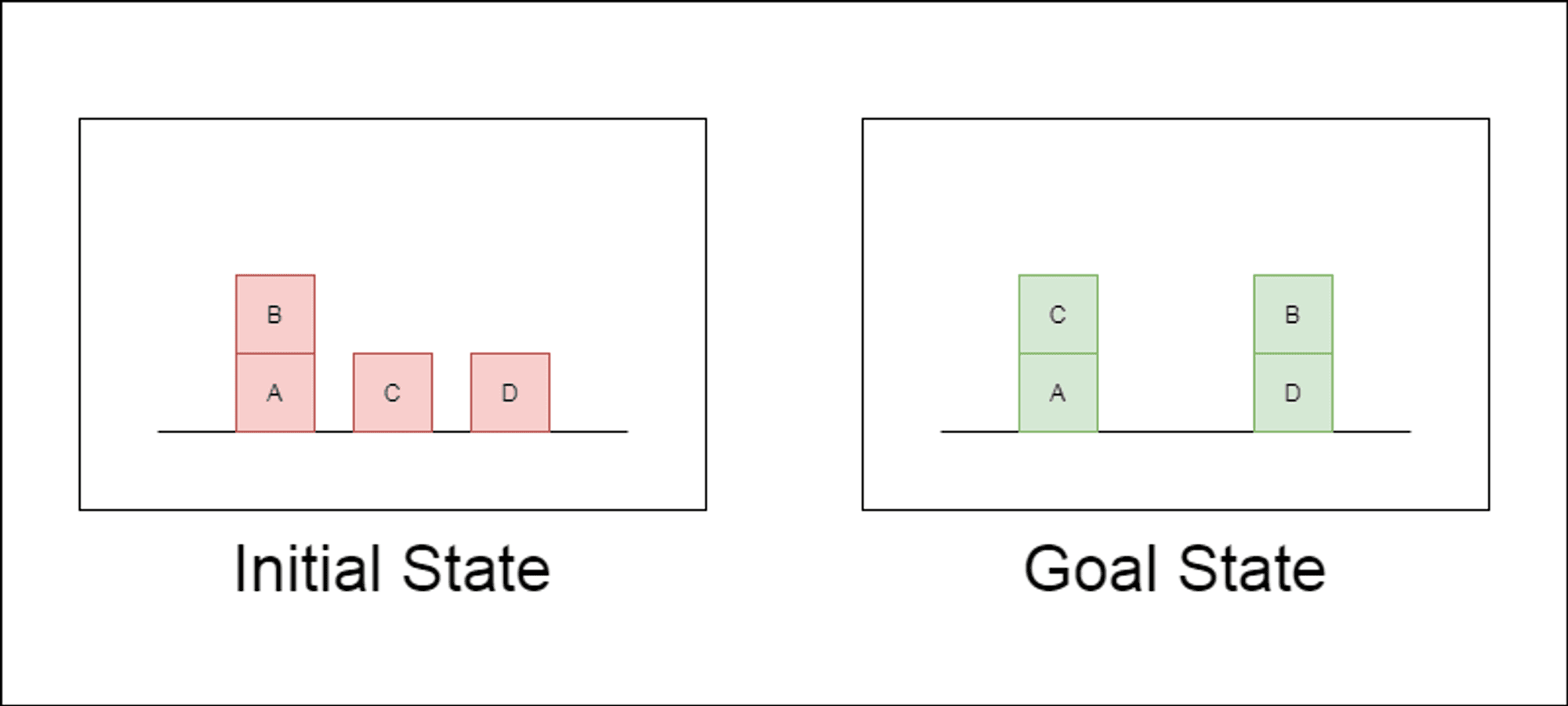
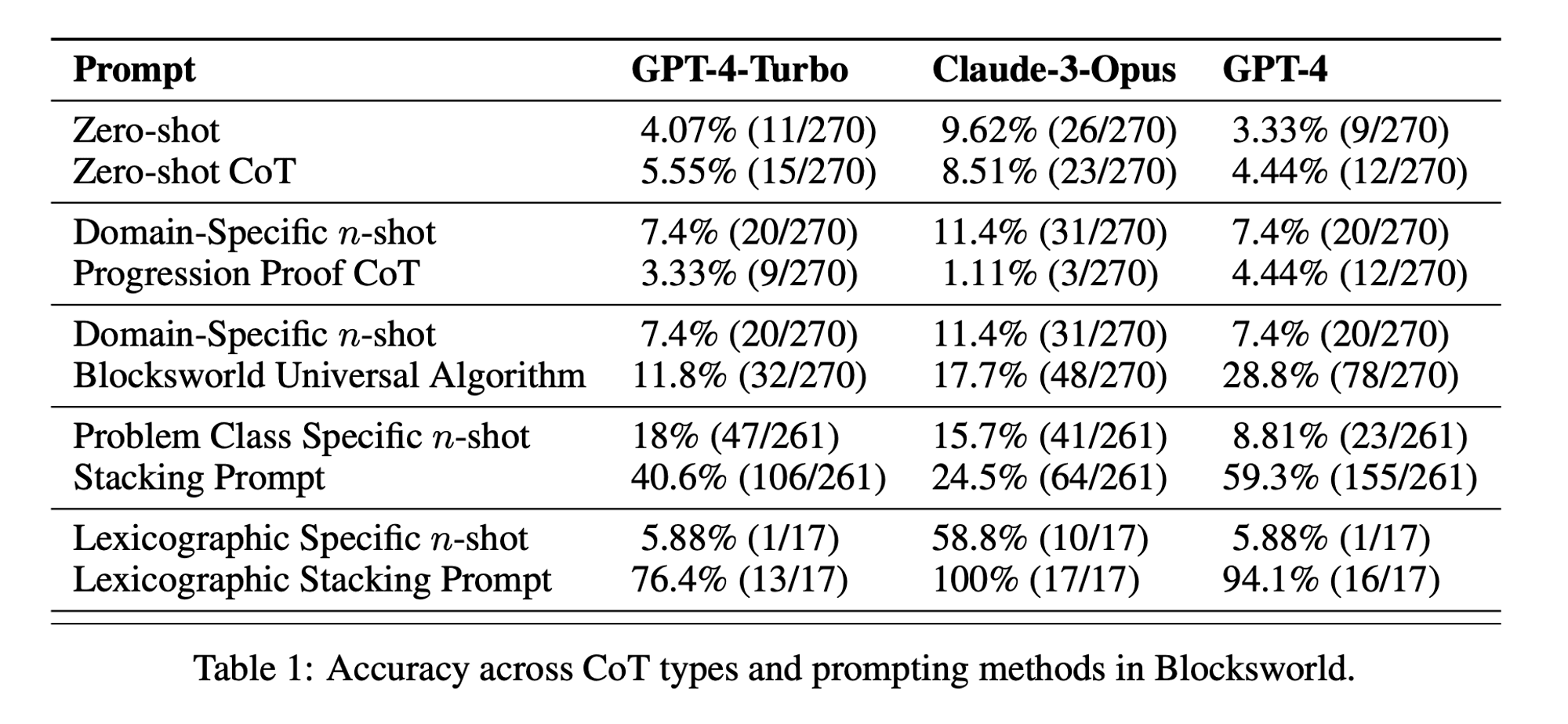
Die Forscher wählten eine klassische Planungsdomäne namens Blocksworld als primäres Testfeld. In Blocksworld besteht die Aufgabe darin, eine Reihe von Blöcken von einer Ausgangskonfiguration zu einer Zielkonfiguration umzuordnen, indem eine Reihe von Bewegungsaktionen durchgeführt wird. Diese Domäne eignet sich ideal zum Testen von Denk- und Planungsfähigkeiten, denn:
Es ermöglicht die Generierung von Problemen mit unterschiedlicher Komplexität
Sie hat klare, algorithmisch überprüfbare Lösungen
Es ist unwahrscheinlich, dass sie in den LLM-Trainingsdaten stark vertreten ist.
In der Studie wurden drei moderne LLMs untersucht: GPT-4, Claude-3-Opus und GPT-4-Turbo. Diese Modelle wurden mit Aufforderungen unterschiedlicher Spezifität getestet:
Null-Schuss Gedankenkette (Universal): Es genügt, der Aufforderung "Denken wir Schritt für Schritt" hinzuzufügen.
Fortschrittsnachweis (speziell für PDDL): Eine allgemeine Erläuterung der Korrektheit von Plänen mit Beispielen.
Blocksworld Universal Algorithmus: Demonstration eines allgemeinen Algorithmus zur Lösung beliebiger Blocksworld-Probleme.
Aufforderung zum Stapeln: Konzentration auf eine bestimmte Unterklasse von Blocksworld-Problemen (Tisch-zu-Stapel).
Lexikografische Stapelung: Weitere Eingrenzung auf eine bestimmte syntaktische Form des Zielzustandes.
Durch das Testen dieser Aufforderungen an immer komplexeren Problemen wollten die Forscher herausfinden, wie gut LLMs das in den Beispielen demonstrierte Denken verallgemeinern können.
Wesentliche Ergebnisse enthüllt
Die Ergebnisse dieser Studie stellen viele der vorherrschenden Annahmen über CoT-Prompting in Frage:
Begrenzte Wirksamkeit des CoT: Entgegen früherer Behauptungen zeigte das CoT-Prompting nur dann signifikante Leistungsverbesserungen, wenn die bereitgestellten Beispiele dem Abfrageproblem extrem ähnlich waren. Sobald die Probleme vom exakten Format der Beispiele abwichen, sank die Leistung drastisch.
Rasche Verschlechterung der Leistung: Mit zunehmender Komplexität der Probleme (gemessen an der Anzahl der beteiligten Blöcke) nahm die Genauigkeit aller Modelle drastisch ab, unabhängig von der verwendeten CoT-Aufforderung. Dies deutet darauf hin, dass LLMs Schwierigkeiten haben, das in einfachen Beispielen gezeigte logische Denken auf komplexere Szenarien zu übertragen.
Unwirksamkeit von allgemeinen Aufforderungen: Überraschenderweise schnitten allgemeinere CoT-Aufforderungen oft schlechter ab als Standardaufforderungen ohne Argumentationsbeispiele. Dies widerspricht der Vorstellung, dass CoT LLMs hilft, verallgemeinerbare Problemlösungsstrategien zu lernen.
Kompromiss bei der Spezifität: Die Studie ergab, dass mit hochspezifischen Aufforderungen eine hohe Genauigkeit erreicht werden kann, allerdings nur bei einer sehr kleinen Teilmenge von Problemen. Dies zeigt, dass es einen starken Kompromiss zwischen Leistungssteigerung und Anwendbarkeit der Aufforderung gibt.
Fehlen eines echten algorithmischen Lernens: Die Ergebnisse deuten stark darauf hin, dass LLMs nicht lernen, allgemeine algorithmische Verfahren aus den CoT-Beispielen anzuwenden. Stattdessen scheinen sie sich auf Mustervergleiche zu verlassen, die bei neuartigen oder komplexeren Problemen schnell versagen.
Diese Ergebnisse haben erhebliche Auswirkungen für KI-Praktiker und Unternehmen, die CoT-Prompting in ihren Anwendungen nutzen wollen. Sie deuten darauf hin, dass CoT zwar die Leistung in bestimmten engen Szenarien steigern kann, aber möglicherweise nicht das Allheilmittel für komplexe Denkaufgaben ist, auf das viele gehofft hatten.
Auswirkungen auf die KI-Entwicklung
Die Ergebnisse dieser Studie haben erhebliche Auswirkungen auf die KI-Entwicklung, insbesondere für Unternehmen, die an Anwendungen arbeiten, die komplexe Denk- oder Planungsfunktionen erfordern:
Neubewertung der CoT-Wirksamkeit: AI developers should be cautious about relying on CoT for tasks that require true algorithmic thinking or generalization to novel scenarios.
Beschränkungen der derzeitigen LLMs: Alternative approaches may be necessary for applications requiring robust planning or multi-step problem-solving.
Die Kosten einer prompten Entwicklung: Während hochspezifische CoT-Prompts gute Ergebnisse für enge Problemgruppen liefern können, kann der menschliche Aufwand, der für die Erstellung dieser Prompts erforderlich ist, die Vorteile überwiegen, insbesondere angesichts ihrer begrenzten Verallgemeinerbarkeit.
Bewertungsmetriken überdenken: Relying solely on static test sets may overestimate a model’s true reasoning capabilities.
Die Kluft zwischen Wahrnehmung und Realität: Es besteht eine erhebliche Diskrepanz zwischen den wahrgenommenen Argumentationsfähigkeiten von LLMs (die im populären Diskurs oft anthropomorphisiert werden) und ihren tatsächlichen Fähigkeiten, wie in dieser Studie gezeigt wurde.
Recommendations for AI Practitioners:
Bewertung: Implement diverse testing frameworks to assess true generalization across problem complexities.
CoT Usage: Apply Chain-of-Thought prompting judiciously, recognizing its limitations in generalization.
Hybrid Solutions: Consider combining LLMs with traditional algorithms for complex reasoning tasks.
Transparency: Clearly communicate AI system limitations, especially for reasoning or planning tasks.
R&D Focus: Invest in research to enhance true reasoning capabilities of AI systems.
Feinabstimmung: Consider domain-specific fine-tuning, but be aware of potential generalization limits.
For AI practitioners and enterprises, these findings highlight the importance of combining LLM strengths with specialized reasoning approaches, investing in domain-specific solutions where necessary, and maintaining transparency about AI system limitations. As we move forward, the AI community must focus on developing new architectures and training methods that can bridge the gap between pattern matching and true algorithmic reasoning.
10 Best Prompting Techniques for LLMs
This week, we also explore ten of the most powerful and common prompting techniques, offering insights into their applications and best practices.

Well-designed prompts can significantly enhance an LLM’s performance, enabling more accurate, relevant, and creative outputs. Whether you’re a seasoned AI developer or just starting with LLMs, these techniques will help you unlock the full potential of AI models.
Make sure to check out the full blog to learn more about each one.
Danke, dass Sie sich die Zeit genommen haben, AI & YOU zu lesen!
Für noch mehr Inhalte zum Thema KI für Unternehmen, einschließlich Infografiken, Statistiken, Anleitungen, Artikeln und Videos, folgen Sie Skim AI auf LinkedIn
Sie sind Gründer, CEO, Risikokapitalgeber oder Investor und suchen KI-Beratung, fraktionierte KI-Entwicklung oder Due-Diligence-Dienstleistungen? Holen Sie sich die Beratung, die Sie brauchen, um fundierte Entscheidungen über die KI-Produktstrategie Ihres Unternehmens und Investitionsmöglichkeiten zu treffen.
Wir entwickeln maßgeschneiderte KI-Lösungen für von Venture Capital und Private Equity unterstützte Unternehmen in den folgenden Branchen: Medizintechnik, Nachrichten/Content-Aggregation, Film- und Fotoproduktion, Bildungstechnologie, Rechtstechnologie, Fintech und Kryptowährungen.


